OpenAI重返开源战略:GPT-OSS系列如何赋能本地化AI创新
自2019年发布GPT-2后,OpenAI在很大程度上将其最先进的模型保留在专有云端服务中,此举引发了业界对AI中心化发展的广泛讨论。然而,近期OpenAI宣布推出两款全新的开放权重模型——gpt-oss-120b和gpt-oss-20b,这标志着该公司在开源策略上迈出了意义非凡的一步。此举不仅提供了在用户硬件上运行AI模型的能力,更深层次地反映了OpenAI对AI普惠化和本地化应用需求的积极响应,预示着AI技术生态可能迎来一个更加多元和去中心化的新阶段。
这一战略转变并非偶然,它深刻洞察了市场对高性能AI模型本地部署的迫切需求。传统云端AI服务虽然便捷,但在特定场景下,如数据敏感性、低延迟要求或定制化需求极高的企业环境中,本地部署的优势无可替代。OpenAI此次推出的gpt-oss系列,正是为了填补这一空白,让用户能够在自己的基础设施上,更灵活、更安全地利用顶尖的生成式AI能力。
gpt-oss技术架构与性能深度剖析
gpt-oss系列的两款模型——gpt-oss-120b和gpt-oss-20b,在设计上展现了OpenAI在效率与性能平衡上的考量。这两款模型均基于Transformer架构,并巧妙地引入了混合专家(Mixture-of-Experts, MoE)技术。MoE架构的核心优势在于,它允许模型在处理每个token时,只激活部分专家网络,从而有效降低实际计算量和内存占用,即使模型总参数规模庞大,也能保持较高的运行效率。
具体来看,gpt-oss-20b拥有210亿总参数,通过MoE技术,每个token仅需激活36亿参数。而规模更大的gpt-oss-120b,总参数高达1170亿,每个token的有效参数量也控制在51亿。这种设计使得即使是参数量庞大的模型,也能在相对有限的硬件资源上运行,显著降低了本地部署的门槛。
在硬件适配性方面,gpt-oss-20b被设计为可在具备16GB或更高内存的消费级机器上流畅运行,这使得个人开发者和小型团队也能轻松尝试高性能AI模型的本地化应用。而gpt-oss-120b虽然需要80GB的内存,这通常超出普通消费级设备范畴,但它能适配于如Nvidia H100等专业级AI加速卡,满足了企业级用户对更高性能的需求。
两款模型均支持128,000 token的超大上下文窗口,这对于处理长篇文档、复杂对话或需要深度理解上下文的任务至关重要。此外,它们还支持可配置的“链式思考”(Chain of Thought, CoT)功能,用户可以通过简单的系统提示,调整CoT的级别(低、中、高),以平衡推理速度和输出质量。更高的CoT设置通常能带来更优的推理结果,但也会消耗更多的计算资源和时间,这种灵活性使得模型能够根据具体应用场景进行优化。
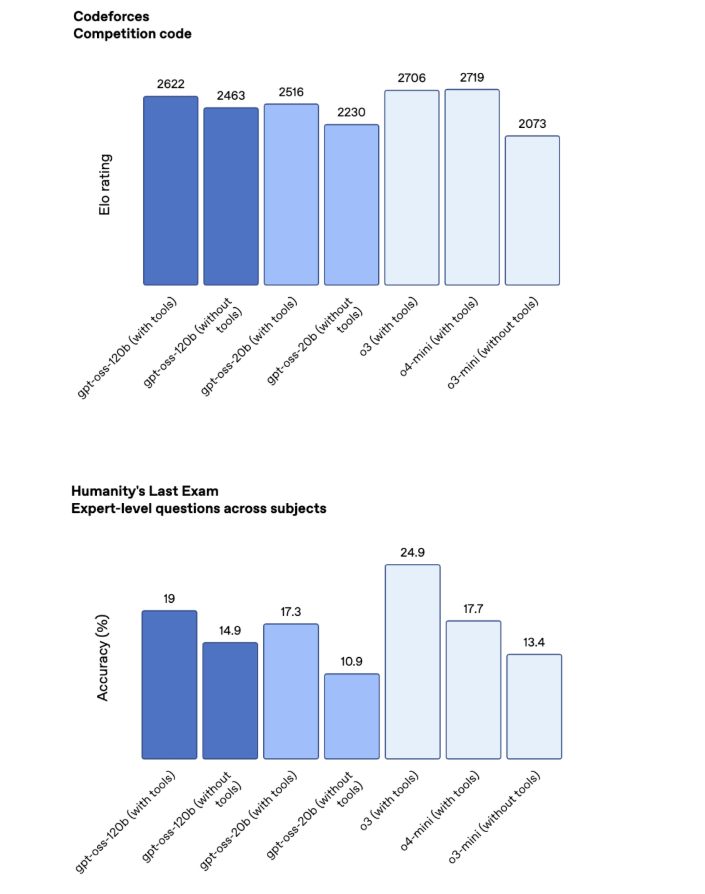
在性能基准测试中,gpt-oss系列展现出令人印象深刻的实力。大规模的gpt-oss-120b在多数测试中,其表现介于OpenAI自家的o3和o4-mini专有模型之间,尤其在数学和编码任务上表现出色。尽管在知识密集型测试(如“人类的最后一次考试”)中,它与Google的Gemini Deep Think(高达34.8%)及OpenAI的o3(24.9%)仍有差距,但考虑到其本地部署的特性和开放性,这一性能已足以满足广泛的企业级应用需求。
本地部署的战略价值与多元应用场景
OpenAI明确表示,gpt-oss模型并非旨在取代其云端的专有模型,而是作为一种互补性解决方案。这一策略反映了对AI应用场景多样性的深刻理解。对于许多企业而言,将核心业务数据上传至第三方云服务存在潜在风险,而本地部署的AI模型则能有效保障数据隐私与安全,确保敏感信息不出内网。
本地化部署还带来了显著的低延迟优势。在需要实时响应的场景,如智能客服、工业自动化或边缘计算应用中,毫秒级的延迟差异可能决定业务成败。gpt-oss模型的本地运行能力,能够显著缩短推理时间,提供近乎实时的交互体验。
此外,本地部署为深度定制化提供了无限可能。基于Apache 2.0的开放许可证,开发者可以对gpt-oss模型进行微调(fine-tuning),使其更好地适应特定领域的数据和任务。例如,一家金融机构可以利用自身独有的交易数据训练模型,使其在风险评估或市场分析上表现出超越通用模型的专业性;医疗机构则可以利用患者数据,开发出高度个性化的诊断辅助系统。这种灵活性是云端API服务难以比拟的。
OpenAI此举也意在收回一部分被其他开源模型(如Meta的LLaMA系列)占据的市场份额。许多企业出于数据安全和定制需求,已经开始转向非OpenAI的开源解决方案。通过推出gpt-oss,OpenAI现在能够为这些客户提供端到端的OpenAI产品栈,即使在需要本地处理数据时,也能保持与GPT系列模型的生态集成。这使得企业客户可以在享受OpenAI技术优势的同时,实现其数据主权和定制化目标。
开放性、安全与负责任的AI发展承诺
gpt-oss模型采用的是宽泛的Apache 2.0许可证,这意味着开发者可以自由地使用、修改、分发甚至商业化这些模型,极大地降低了AI创新的门槛。这种开放性将促进全球开发者社区的协作与创新,共同推动AI技术边界的拓展。然而,随之而来的也包括对潜在滥用的担忧,因为开放权重模型一旦发布,其控制权便不再完全由发布者掌握。
OpenAI对此并非没有预见。公司在发布这些模型前,进行了严格的安全测试,甚至尝试将gpt-oss模型“调教”成“邪恶”版本,以模拟最坏情况下的滥用情景。令人欣慰的是,OpenAI宣称即使在极端测试中,模型也未能达到高水平的“邪恶”行为能力。这主要得益于OpenAI在模型训练中融入的“审慎对齐”(deliberative alignment)和“指令层级”(instruction hierarchy)等安全机制。这些机制旨在从根本上限制模型生成有害或恶意内容的能力,即使经过恶意微调,其不良行为的质量也难以达到威胁级别。
这一安全声明,虽然不能完全消除所有担忧,但无疑为开放模型在实际应用中的安全性提供了信心基础。它表明OpenAI在推动AI技术开放的同时,并未放松对负责任AI开发的承诺,力求在开放性、能力和安全性之间找到平衡点。这种做法也有助于塑造未来开放AI模型的发展范式,即在赋予开发者更大自由度的同时,也需内置强大的安全防护措施。
获取途径与对AI生态的深远影响
gpt-oss-120b和gpt-oss-20b模型目前已可通过HuggingFace平台下载,同时OpenAI还在GitHub上提供了相关的代码仓库,方便开发者进行深入研究和二次开发。此外,OpenAI也提供了这些模型的官方托管版本,供用户进行测试和体验。这些便捷的获取方式,无疑将加速gpt-oss系列在开发者社区中的普及和应用。
OpenAI重返开源,并在本地部署领域发力,这对于整个AI生态系统而言具有深远的意义。它不仅加剧了开源AI领域的竞争,可能促使其他AI公司也考虑开放其模型,从而推动整个行业向更开放、更普惠的方向发展。对于企业和开发者而言,这意味着更多高质量、可定制的AI模型选择,能够更好地满足多样化的业务需求和技术挑战。
未来,随着AI技术与各行各业的深度融合,本地化、可控化、高安全性的AI解决方案将变得日益重要。gpt-oss系列的发布,正是这一趋势的有力印证。它不仅巩固了OpenAI作为AI领域领导者的地位,更在全球范围内为AI技术的民主化和创新,描绘了一幅更为广阔的图景,开启了本地化智能应用的新纪元。