
谷歌人工智能实验室近期揭开了其备受瞩目的“nano-banana”神秘面纱,正式发布了Gemini 2.5 Flash Image模型。这款模型在AI大语言模型竞技场LMArena上凭借卓越表现脱颖而出,被业界誉为Google迄今为止最先进的图像生成与编辑模型。它不仅以“闪电般”的速度刷新了用户体验,更在多个关键榜单上荣获SOTA地位,其核心能力预示着图像处理领域将迎来一场深刻变革。
Gemini 2.5 Flash Image的登场,是谷歌对高性能、低延迟AI模型承诺的兑现。Gemini 2.0 Flash系列已经因其高性价比和效率广受开发者青睐,而Gemini 2.5 Flash Image则在此基础上,着力提升了图像质量和创作控制力。它带来了令人惊叹的角色一致性、更精准的提示词图片编辑、自然流畅的多幅图像融合能力,以及对现实世界知识的深度理解。在我看来,这不仅仅是一次模型迭代,它更像是一个为未来爆款应用奠定基础的“原点”,让人第一次真切地感受到,AI修图的未来已触手可及。
闪电般的速度与原生多模态的融合
极速生成:效率革新的核心驱动
Gemini 2.5 Flash Image最直观的优势便是其惊人的处理速度。在使用其他开源模型时,即使在高性能计算机上,从输入提示到生成一张高质量图像也可能需要几十秒甚至更长时间。对于移动设备用户而言,这种漫长的等待无疑是一种煎熬。然而,Gemini 2.5 Flash Image将这一门槛直接拉低至几秒钟。在我的实际测试中,输入一句提示,仅需三四秒便能生成清晰且细节丰富的图像。这种即时反馈的体验,让复杂的AI图像生成变得如同使用传统修图软件应用滤镜般迅速,极大地提升了用户的工作流程效率和创作流畅度。这不仅仅是速度的提升,更是用户心理预期的重塑,让以往耗时费力的复杂任务变得触手可及。

多模态理解:超越简单的图文识别
如果说速度解决了传统P图用户的体验感,那么“原生多模态”则拓展了AI图像能力的边界。Gemini 2.5 Flash Image不仅能生成图片,还能同时理解文字和图像输入。这意味着我可以将一张照片和一段文字提示同时提供给它,模型会结合两者的信息来理解我的意图。例如,我上传一张街头照片,并指示它“把背景改成东京新宿的夜景”。结果,模型不仅准确识别并抠出了照片主体,还将背景替换为霓虹闪烁的新宿街头。更令人称奇的是,它还能保持人物光影的统一性,完全避免了传统手动抠图常常出现的“硬抠贴”效果。这种结合了“世界知识”与视觉理解的深度智能,是其生成结果自然逼真的关键,预示着AI对真实世界的认知能力达到了一个新高度。

角色一致性与直观操作的交互革命
高保真角色一致性:重塑图像主体掌控
对于人像P图这类对画面细节要求极高的场景,Gemini 2.5 Flash Image的角色一致性提供了一种前所未有的“Vibe Photoshoping”体验。它能确保在对图像进行大幅改造时,主体角色的特征、姿态乃至神韵都能高度保持。例如,我让它“把照片里的人换成微笑的表情”,结果不仅嘴角微微上扬,连眼神都做了细微调整,细节非常到位。这种精准且克制的操作,仿佛一位深谙你心意的设计师,能够在不破坏原有“氛围感”的前提下,进行精确的调整。这在很大程度上消除了以往AI生成图像中那种“玄学”的随机性,让创作者能够更直接、更可控地实现其意图。


提示词理解:从指令到意图的转化
Gemini 2.5 Flash Image对提示词的理解更为精准,也更贴近用户的直觉。这使得用户在与其交互时,不再需要绞尽脑汁地编写复杂的“咒语”,而是可以用更自然、口语化的表达来传达意图。比如,我对它说“模糊背景,突出前景人物”,几秒钟后生成的图片正是所需效果。我甚至尝试过“给黑白照上色”,结果输出的彩色图并非胡乱涂抹,而是尽可能贴近历史照片中应有的色彩氛围。这种“说到做到”的能力,代表了AI交互模式的进化,即工具开始主动适应用户的思考模式,而非反之,极大地降低了AI工具的使用门槛,让更多非专业用户也能享受到高质量的创作体验。

对比传统工具与未来应用展望
超越传统修图软件的体验维度
为了更直观地展现其能力,我将其与日常使用的移动端修图工具进行了对比。在Snapseed这类工具中,模糊背景通常需要手动选取前景区域并反复调整,耗时且繁琐。美图秀秀虽然提供一键背景模糊,但常常导致人物边缘模糊或效果不自然。而Gemini 2.5 Flash Image仅需一句话,便能自动识别人物与背景边界,生成自然、无需二次修饰的模糊效果。这种对比说明,Gemini 2.5 Flash Image将用户从复杂的修图操作中解放出来,将大量工作交由AI模型自动完成。对于普通用户,它降低了修图门槛;对于专业人士,它节省了宝贵时间。这标志着图像处理从“工具集合”向“智能助手”的根本性转变,预示着图像编辑将进入一个高度自动化与智能化的时代。
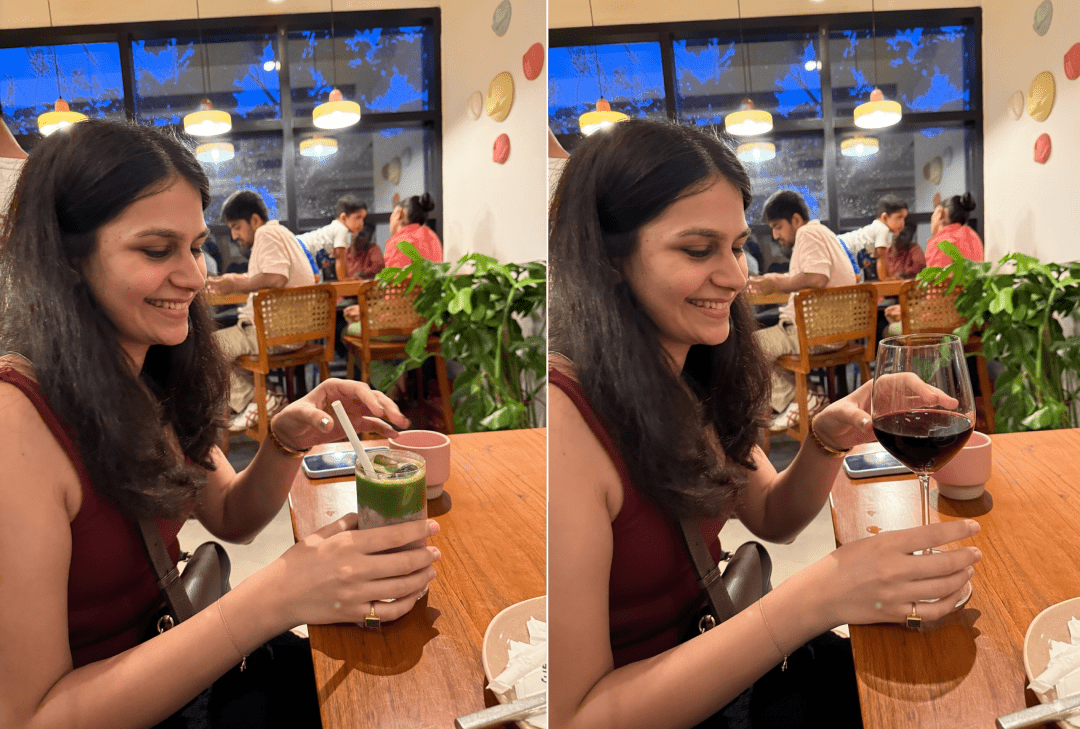
下一代应用形态的雏形与局限
体验下来,我最大的感受是,Gemini 2.5 Flash Image不再仅仅是一个修图工具,它更接近一个智能助手。它不再要求你学习工具的逻辑,而是直接理解你的需求,你只需说出来,它便替你完成。这种交互方式本身就是下一代应用形态的雏形。可以想象,如果将其与手机操作系统深度结合,未来的图片编辑将变得异常流畅:你对着手机说一句“帮我修一下这张照片,让皮肤自然一些”,几秒钟后结果便已生成;或者旅行拍照时,你指示它“把天气改成晴天”,照片立刻变得阳光明媚。尽管当前Gemini 2.5 Flash Image仍处于早期阶段,其主要目的仍是图像生成而非精细微调,且所有通过它创建或编辑的图像都将包含SynthID数字水印以标识AI生成内容,但其展现出的速度、理解力和还原度,已足以让人对未来充满无限遐想。

AI图像处理的爆发原点
回顾美图秀秀之所以能成为国民级应用,关键在于它以最简单的方式解决了所有人都想解决的问题——让照片更好看。Gemini 2.5 Flash Image正是在此基础上进一步发展,它将复杂的AI能力打磨成人人都能用的“秒出图”体验。当我第一次对它说出“帮我模糊一下背景”,几秒后画面便被自然处理好的那一瞬间,我清楚地意识到:这是爆款应用的爆发原点。它不仅仅是一个模型,更是未来无数新产品的底层能力。这种将前沿技术平民化的能力,正是定义新一代爆款产品的核心要素。
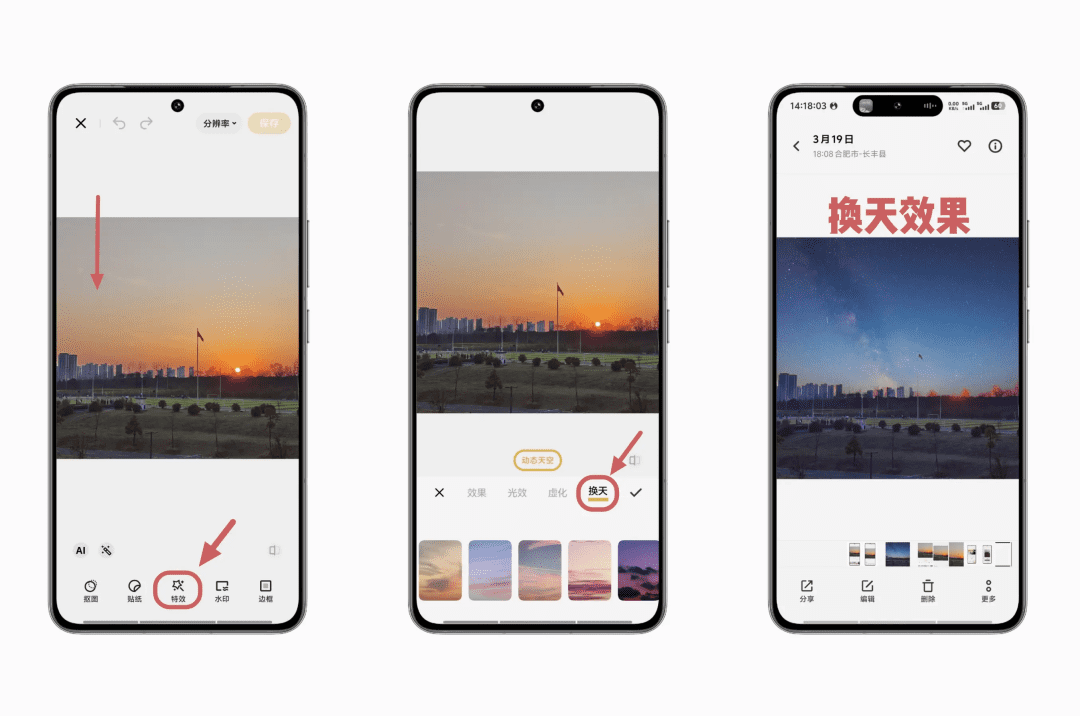
也许几年后,我们可能会淡忘“Banana”这个代号,但会看到越来越多这种让你“想要什么就说出来,立刻就能实现”的新体验的图片处理工具。它们或许会像当年的美图秀秀一样,成为一代用户的共同记忆。只不过这一次,AI将把想象力的边界推得更远,实现更个性化、更沉浸式的视觉内容创作,彻底革新我们与图像世界互动的方式。








