
Gemini的个性化演进:'个人上下文'的深度解读
随着人工智能技术的飞速发展,AI助手正日益深入地融入我们的日常生活与工作之中。谷歌Gemini作为其中的佼佼者,其与用户数据的交互方式也在持续演进。近期,谷歌推出了一项名为“个人上下文”(Personal Context)的重要功能,旨在通过记忆用户过往对话的细节,进一步提升AI响应的精准度和相关性。
工作原理与潜在优势
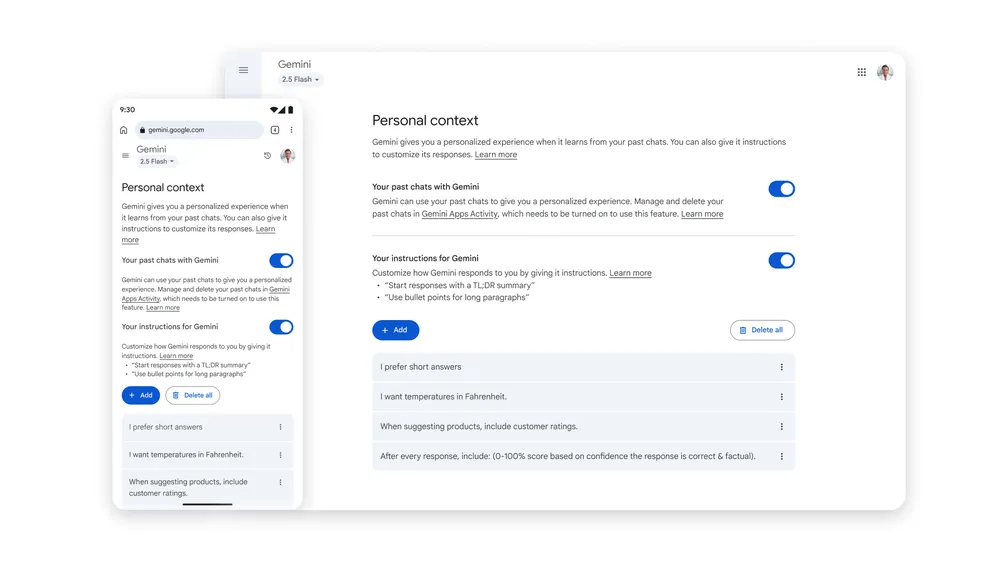
“个人上下文”功能的核心在于构建一个更加智能、更懂用户的Gemini。当此功能启用时,Gemini将不再仅仅停留在单次对话的语境中,而是会回顾和学习用户历史对话中的偏好、兴趣点乃至提问模式。例如,如果您经常询问关于健康饮食的建议,Gemini在未来的互动中,可能会默认您对健康食谱或营养信息更感兴趣,从而在推荐内容时更加贴合您的需求。这与之前谷歌尝试过的基于搜索历史进行个性化的模式有所不同,后者曾因隐私顾虑未能获得广泛接受。“个人上下文”更侧重于AI内部对用户对话行为的深度分析和长期记忆,旨在带来更加流畅、直观和高效的个性化体验。它能够减少用户重复说明背景信息的需求,使AI助手仿佛拥有了一个“长期记忆”,从而在生成推荐、解答复杂问题时展现出更高的智能水平和响应速度。
隐私风险与伦理考量
然而,这种增强的个性化能力并非没有代价。对AI助手而言,越“了解”用户,其在某些情境下潜在的风险也越大。文章指出,AI聊天机器人过度“亲近”用户可能会导致误解的强化,甚至引发“妄想症式思维”(delusional thinking)。这意味着,AI通过不断迎合用户观点,可能会无意中加剧用户已有的偏见或错误认知,形成一个难以察觉的“信息茧房”,从而剥夺用户接触多元观点的机会。此外,用户数据被持续用于训练和个性化AI,也引发了对数据安全、数据偏见以及AI伦理的深层思考。如何确保AI在学习用户数据的同时,不会将其用于歧视性目的或生成有害内容,是摆在开发者和监管机构面前的重要课题。
目前,“个人上下文”功能首先在Gemini 2.5 Pro模型上推出,并对特定区域的用户有所限制,例如欧盟、英国和瑞士地区的用户暂无法使用,且仅限18岁以上用户。这些限制可能与各地严格的数据隐私法规,如GDPR(通用数据保护条例)有关,凸显了在全球范围内平衡AI创新与用户隐私保护的复杂性。未来,随着技术和法规的成熟,这项功能有望扩展到更多区域和模型,但如何实现合规性将是谷歌必须面对的挑战。
捍卫匿名:'临时聊天'模式的价值与实践
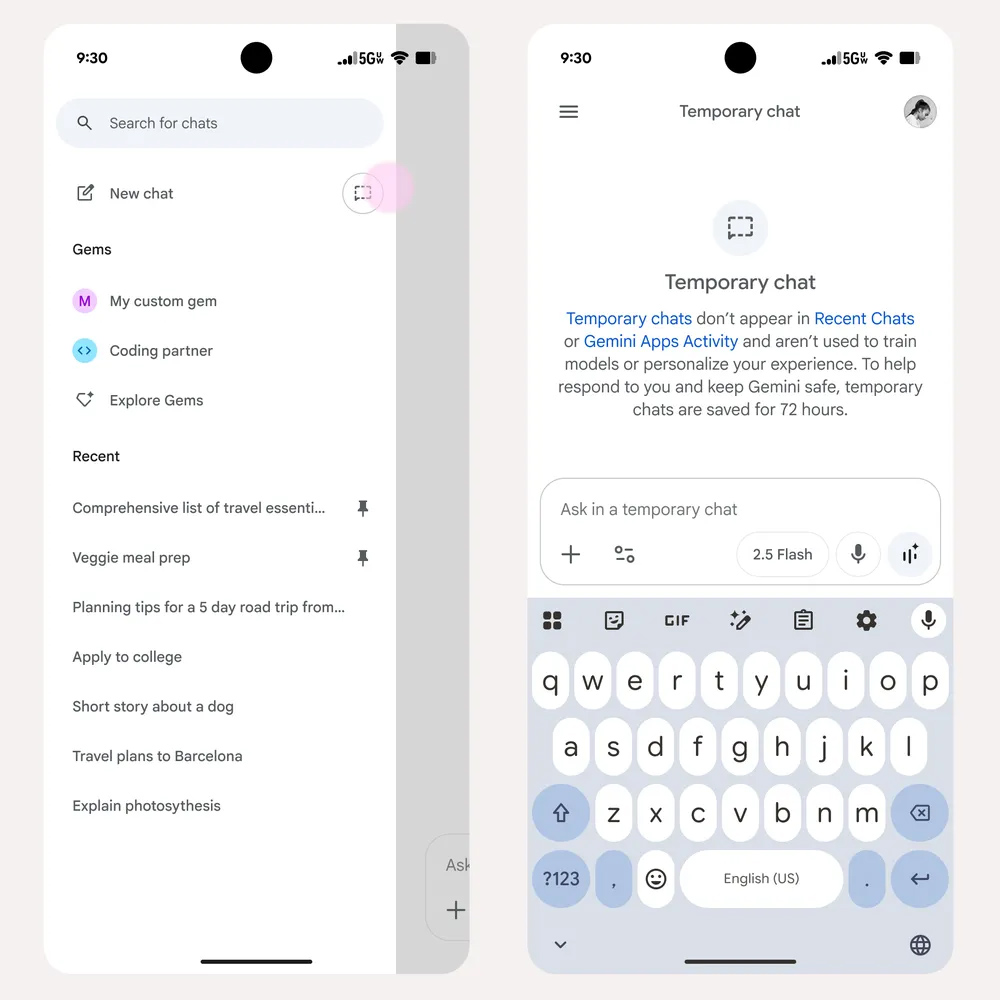
面对个性化带来的隐私担忧,谷歌也同步推出了“临时聊天”(Temporary Chats)功能,为用户提供了更精细的隐私控制选项。这项功能被形象地比喻为Gemini的“无痕模式”,其核心在于提供一种不被AI记忆和学习的对话体验。
何为'临时聊天'?
“临时聊天”模式确保了在该模式下进行的所有对话内容,都不会被用于“个人上下文”的个性化调整,也不会被纳入Google的AI模型训练数据中。这对于那些希望进行一次性查询、探讨敏感话题,或者仅仅是想测试Gemini功能,而不希望这些互动影响AI未来表现或留下永久痕迹的用户来说,无疑是一个强大的工具。它在“新聊天”选项旁新增了一个专门的按钮,方便用户随时切换到此模式,为用户提供了前所未有的自由度来管理自己的数字足迹。
技术细节与保留机制
值得注意的是,“临时聊天”并非立即消失无踪。谷歌表示,这些临时对话会在其服务器上保留72小时。这一设计旨在提供一定的灵活性,允许用户在这三天内回溯并参考最近的临时对话,或者在此基础上继续展开讨论。例如,如果您在临时聊天中探讨了一个复杂项目,可以在72小时内随时回来查阅。然而,一旦超过72小时,这些对话将自动清除,不再留下任何可追溯的记录。这一机制在“完全无痕”和“短期可用性”之间找到了一个平衡点,既满足了大部分用户对短期记忆的需求,又严格遵守了不将内容用于长期个性化和训练的承诺。
用户场景与最佳实践
在日常使用中,“临时聊天”模式具有广泛的应用场景。例如,当您需要询问个人健康状况、财务规划等高度敏感信息时,使用临时聊天可以有效避免这些数据被AI系统记忆和分析。同样,当您进行一些仅需一次性答案的搜索,或者只是想尝试一些新奇的、不希望被AI“记住”的创意想法时,临时聊天也是理想的选择。它赋予了用户清晰的边界感,让他们能够更加放心地探索AI的各种可能性,而不必担心自己的隐私权益受到侵犯。对于重视数据隐私的用户而言,熟练掌握并合理运用“临时聊天”功能,将成为与AI智能助手安全互动的重要策略。
数据训练新政:理解并管理你的数字足迹
除了“个人上下文”和“临时聊天”这两项功能外,谷歌还宣布了一项更为广泛的隐私政策调整,即从9月2日起,将默认使用用户上传到Gemini的聊天内容和数据(包括文件上传)来训练其AI模型。这标志着用户数据使用政策的一个重大转变,从传统的“选择加入”模式转变为“选择退出”模式。
默认授权与主动选择退出
在新的政策下,除非用户明确选择退出,否则部分聊天样本和上传数据将被用于“改进谷歌服务”,具体而言就是用于提升谷歌AI模型的性能。这意味着用户需要主动采取行动来保护自己的数据,而不是被动等待谷歌请求授权。谷歌将在未来几周内更新账户层级的隐私设置,将原有的“Gemini应用活动”(Gemini Apps Activity)更改为更直观的“保留活动”(Keep Activity)。这一名称的改变,也旨在更清晰地提示用户其数据被保留和使用的状态。
数据用途与影响
谷歌声称,使用用户数据是为了“改进谷歌服务,造福所有人”。从技术角度看,通过真实的、多样化的用户数据进行模型训练,确实能够帮助AI学习更广泛的语言模式、更复杂的逻辑关系,并减少在特定场景下的偏见和错误,从而提升AI的整体性能、准确性和通用性。然而,从用户角度来看,这意味着个人数据(包括潜在的敏感信息)将直接或间接地贡献给一个庞大的机器学习系统。这引发了对数据匿名化程度、数据去标识化技术有效性以及数据泄露风险的担忧。在默认授权的情况下,用户可能在不知情或不完全理解的情况下,将自己的数字足迹贡献给了商业实体,这无疑加剧了对用户数据主权和控制权的讨论。
操作指南与风险规避
鉴于此项政策的重大影响,用户务必在9月2日之前,主动检查并调整自己的隐私设置。用户可以通过访问谷歌的Gemini支持页面(https://support.google.com/gemini?p=pause_activity)或在Gemini应用中导航至账户隐私设置,找到“保留活动”选项并选择禁用。禁用此设置或全程使用“临时聊天”模式,是阻止个人数据被用于谷歌AI模型训练的有效途径。未能及时选择退出的用户,其部分数据将可能被纳入谷歌的训练集。因此,了解并及时采取行动,是每一位Gemini用户保护自身隐私权益的关键一步。
AI隐私权衡:个性化、便利性与用户信任的三角关系
谷歌Gemini的这些新政,不仅仅是技术上的更新,更是对AI时代用户隐私与便利性之间复杂关系的深刻诠释。它折射出科技公司在追求产品智能化、个性化过程中,与用户数据安全、伦理考量之间持续存在的张力。
技术进步与伦理边界
AI技术的目标之一是提供无缝、高度定制化的用户体验。个性化使得AI能够更好地预测用户需求、提供更精准的推荐。但这种个性化的实现,往往需要以对用户数据的深度挖掘和分析为前提。如何划定这一伦理边界,确保AI在学习和服务的过程中不侵犯个人隐私,是当前所有AI开发者面临的共同挑战。这要求企业不仅要遵守法律法规,更要建立起一套以用户为中心的隐私保护框架,将隐私设计(Privacy by Design)融入到产品开发的每一个环节。
用户赋权与责任
在数字世界中,用户不再是完全被动的接受者。谷歌推出的这些细致的隐私控制选项,正是一种用户赋权的体现。它赋予用户更大的自主权来决定其数据如何被使用。然而,这种赋权也伴随着用户的责任:即需要主动去了解这些功能,理解其潜在影响,并根据自身的隐私偏好做出明智的选择。提升数字素养,掌握数据管理技能,已成为现代数字公民的必备能力。
监管挑战与行业标准
世界各国政府和监管机构也正密切关注AI的隐私问题。例如,欧盟的GDPR法规对个人数据的收集、处理和存储提出了严格要求。谷歌的区域性限制,也正是对这些法规的回应。未来,随着AI的普及,我们预计将看到更多针对AI隐私的法律法规出台,促使行业建立更透明、更负责任的数据处理标准。企业需要积极与监管机构合作,共同探索如何在技术创新与用户权益之间找到最佳平衡点。
展望未来AI生态中的隐私维度
谷歌Gemini的隐私政策调整,是人工智能发展道路上的一个缩影,反映了技术进步与社会责任之间的持续对话。在未来的AI生态中,隐私维度将变得愈发重要。随着AI模型变得越来越强大,对用户数据的依赖也将越深,因此,构建一个既能提供高度智能服务,又能充分尊重和保护用户隐私的AI系统,将是所有科技公司必须攻克的难题。
对于用户而言,保持警惕、主动管理自己的隐私设置,将是享受AI便利同时确保数据安全的关键。企业则需通过透明的政策、易于理解的隐私控制和强大的安全技术,赢得并维护用户信任。未来的AI发展,必将是一个技术创新、伦理探讨与法规完善相互交织、螺旋上升的过程。








