
在数字内容创作领域,面部动画一直是一项既耗时又复杂的工作。传统方法需要动画师逐帧调整角色的面部表情和口型,不仅效率低下,而且难以达到自然流畅的效果。然而,随着人工智能技术的飞速发展,这一局面正在被彻底改变。英伟达(NVIDIA)推出的Audio2Face开源AI面部动画生成模型,正是这场变革的核心驱动力之一。本文将深入探讨这项革命性技术的原理、功能、应用及其对数字内容创作行业的深远影响。
Audio2Face:重新定义面部动画生成
Audio2Face是英伟达开发的一款基于深度学习的AI面部动画生成模型,它能够通过分析输入的音频,自动生成与之匹配的逼真面部动画。这项技术的核心价值在于,它能够将音频中的语音内容、情感特征和节奏变化,精确地转化为角色的口型动作和表情变化,实现前所未有的自然度和真实感。
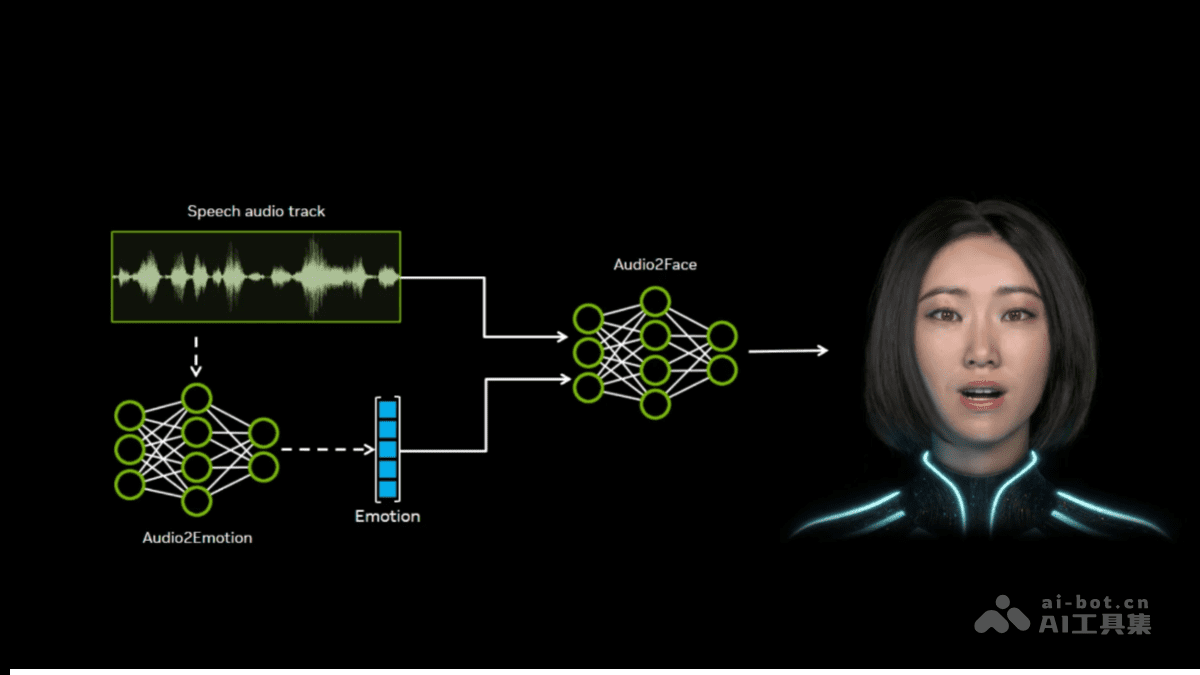
与传统的面部动画制作方法相比,Audio2Face具有显著优势。传统方法通常需要动画师具备专业的技能和丰富的经验,通过逐帧调整来创建面部动画,这个过程不仅耗时,而且对动画师的艺术素养和技术能力要求极高。而Audio2Face则通过自动化和智能化的方式,大幅简化了这一流程,使不具备专业动画技能的开发者也能创建出高质量的面部动画。
Audio2Face的核心技术原理
Audio2Face的强大功能背后,是一套复杂而精密的技术体系。理解这些技术原理,有助于我们更深入地认识这项技术的价值和潜力。
音频特征提取:从声音到数据的转化
Audio2Face的第一步是从输入音频中提取关键特征。这些特征包括音素(语音的基本单元)、语调、节奏等,它们是生成面部动画的基础。例如,不同的音素对应不同的口型形状,而语调和节奏则会影响表情的变化和强度。通过先进的信号处理技术,Audio2Face能够精确地识别和提取这些特征,为后续的动画生成提供准确的数据基础。
深度学习模型:音频到面部动作的桥梁
在提取音频特征后,Audio2Face使用预训练的深度学习模型将这些特征映射到面部动画。这些模型通常基于生成对抗网络(GANs)或Transformer架构,通过大量的音频和对应的面部动画数据进行训练,学习如何将音频特征与面部动作关联起来。这种端到端的训练方式,使得模型能够自动学习到复杂的映射关系,无需人工设计规则。
生成对抗网络(GANs):提升动画真实性的关键技术
GANs是Audio2Face技术架构中的核心组件之一。它由生成器(Generator)和判别器(Discriminator)两部分组成。生成器负责根据音频特征生成面部动画,而判别器则评估生成的动画是否逼真。通过这种对抗训练的方式,生成器能够不断改进其输出结果,生成越来越逼真的面部动画。这种技术特别适合用于生成具有高度细节和自然变化的面部动画。
情感分析:让数字角色拥有情感表达能力
Audio2Face的另一项关键技术是情感分析。通过分析音频中的情感特征,如语调的高低、节奏的快慢等,模型能够将这些情感特征映射到相应的情感表情上。这使得生成的数字角色不仅能够准确表达语音内容,还能够传达情感,大大增强了角色的表现力和感染力。这种情感表达能力是传统面部动画技术难以实现的。
Audio2Face的主要功能特点
Audio2Face不仅技术先进,而且功能全面,能够满足不同场景和需求。以下是它的主要功能特点:
精确的口型同步
Audio2Face最核心的功能是根据音频中的语音内容生成与之匹配的口型动作。通过精确的音素识别和映射,模型能够确保角色说话时的嘴唇运动自然且准确,实现完美的口型同步。这一功能对于虚拟主播、游戏角色对话等场景尤为重要,能够显著提升用户体验。
情感表达
除了口型同步,Audio2Face还能够根据音频中的情感特征生成相应的情感表情。例如,当音频中表达喜悦时,模型会生成微笑的表情;表达困惑时,则生成皱眉的表情。这种情感表达能力使得数字角色更加生动和真实,能够更好地与观众或用户建立情感连接。
实时动画生成
Audio2Face支持实时渲染,能够快速将音频转换为动画。这一特点使其非常适合实时交互场景,如虚拟客服、直播、实时游戏对话等。在这些场景中,用户与数字角色的互动需要即时响应,而Audio2Face的实时性能恰好满足了这一需求。
多平台支持
Audio2Face提供与主流3D软件的集成插件,包括Autodesk Maya、Unreal Engine 5等。这意味着开发者可以在自己熟悉的工具中使用Audio2Face,无需学习新的软件或工作流程。这种多平台支持大大降低了技术的使用门槛,促进了技术的普及和应用。
可定制性
Audio2Face不仅提供了预训练的模型,还允许开发者使用自己的数据集对模型进行微调。这种可定制性使得开发者能够根据特定项目或角色的需求,调整模型的输出风格和表现方式。例如,可以针对特定年龄、性别或种族的角色进行训练,使生成的面部动画更加符合角色的设定。
Audio2Face的应用场景
Audio2Face的强大功能和灵活性使其在多个领域都有广泛的应用前景。以下是几个主要的应用场景:
游戏开发
在游戏制作中,面部动画是角色表现力的重要组成部分。传统方法需要动画师花费大量时间制作角色的口型和表情,而Audio2Face可以快速生成高质量的动画,大大缩短开发周期。此外,Audio2Face的实时性能使其非常适合动态对话系统和玩家交互场景,能够提升游戏的沉浸感和真实感。
虚拟客服
虚拟客服是另一个重要的应用场景。通过Audio2Face,虚拟客服角色可以拥有自然的口型和表情,使其看起来更像真人,提升用户体验。研究表明,具有自然面部表情的虚拟客服能够显著提高用户的满意度和沟通效果,这对于企业提升服务质量具有重要意义。
动画制作
在动画电影或短片中,Audio2Face可以帮助动画师快速创建角色的面部动画,提高制作效率。特别是对于需要大量对话的场景,Audio2Face可以大幅减少人工工作量,同时保持高质量的表现效果。此外,Audio2Face的可定制性也使其适合不同风格的动画项目。
虚拟直播
虚拟直播是近年来兴起的一种新型直播形式,通过虚拟形象进行直播互动。Audio2Face可以帮助主播在虚拟直播中实时生成与语音匹配的面部表情和口型,增强直播的趣味性和互动性。这种技术特别适合虚拟偶像、游戏主播等场景,能够吸引更多观众参与互动。
教育与培训
在虚拟教学场景中,Audio2Face可以为虚拟教师生成生动的表情和口型,使教学内容更加吸引学生。研究表明,具有丰富面部表情的教学虚拟形象能够提高学生的注意力和学习效果。此外,Audio2Face还可以用于语言学习应用,帮助学习者更好地掌握发音和口型。
Audio2Face的技术优势与挑战
技术优势
高效性:相比传统方法,Audio2Face能够大幅缩短面部动画的制作时间,提高生产效率。
高质量:基于深度学习的模型能够生成高度逼真的面部动画,达到专业水准。
易用性:提供友好的SDK和插件,使不具备专业动画技能的开发者也能轻松使用。
灵活性:支持实时生成和多平台集成,适应不同场景和需求。
可扩展性:允许开发者使用自己的数据集进行微调,适应特定项目需求。
面临的挑战
尽管Audio2Face具有诸多优势,但在实际应用中仍面临一些挑战:
数据依赖:模型性能很大程度上依赖于训练数据的质量和数量,获取高质量的面部动画数据仍然具有挑战性。
计算资源:高质量的实时面部动画生成需要强大的计算资源,这对普通开发者可能构成一定门槛。
文化差异:不同语言和文化背景下的面部表情表达存在差异,模型需要针对特定文化进行优化。
个性化需求:对于高度个性化的角色设计,可能需要更多的定制工作和专业知识。
Audio2Face的未来发展趋势
随着人工智能技术的不断进步,Audio2Face及其相关技术也将持续发展和完善。以下是几个可能的发展趋势:
更高的真实感和表现力
未来的Audio2Face版本可能会进一步提升面部动画的真实感和表现力,实现更加细微和复杂的表情变化。这将使数字角色更加生动和真实,能够更好地传达情感和意图。
多模态融合
未来的系统可能会融合多种输入模态,如文本、视频、生物信号等,而不仅限于音频。这种多模态融合将使面部动画生成更加丰富和准确,能够捕捉到更多细微的表情变化。
实时性能的进一步提升
随着硬件技术的发展,Audio2Face的实时性能将进一步提升,使其能够在更多设备和平台上实现高质量的面部动画生成。这将进一步拓展其应用场景,使更多实时交互场景受益于这项技术。
更强的个性化能力
未来的Audio2Face可能会提供更强大的个性化能力,使开发者能够更轻松地创建具有独特风格的面部动画。这可能包括特定年龄、性别、种族或艺术风格的定制选项。
行业标准的形成
随着Audio2Face等技术的普及,可能会形成一套行业标准,规范面部动画生成的流程和质量。这将有助于技术的推广和应用,促进行业的健康发展。
Audio2Face对数字内容创作行业的影响
Audio2Face的出现,对数字内容创作行业产生了深远的影响。首先,它大幅降低了面部动画制作的技术门槛,使更多创作者能够参与到数字内容的制作中。其次,它提高了生产效率,缩短了开发周期,使创作者能够更快地将创意转化为现实。此外,它还提升了数字角色的表现力和真实感,使用户体验得到显著改善。
对于游戏开发公司而言,Audio2Face可以帮助他们更快地开发出高质量的游戏角色,提升游戏的竞争力。对于影视动画行业,这项技术可以加速制作流程,降低成本,同时保持高质量的表现效果。对于教育和培训领域,Audio2Face可以创建更加生动和吸引人的教学虚拟形象,提高学习效果。
如何开始使用Audio2Face
对于想要尝试Audio2Face的开发者,可以按照以下步骤开始:
访问项目官网:首先访问Audio2Face的官方项目页面(https://developer.nvidia.com/blog/nvidia-open-sources-audio2face-animation-model/),了解技术详情和最新动态。
获取GitHub仓库:从GitHub仓库(https://github.com/NVIDIA/Audio2Face-3D)下载源代码和相关资源。
阅读文档:仔细阅读项目文档,了解系统的要求和安装步骤。
安装依赖:按照文档要求安装必要的依赖和环境。
运行示例:尝试运行项目提供的示例,体验系统的基本功能。
集成到工作流:根据需要,将Audio2Face集成到现有的工作流中,或使用提供的SDK开发自己的应用。
定制模型:如有需要,可以使用自己的数据集对模型进行微调,以适应特定需求。
结论
Audio2Face作为英伟达推出的革命性AI面部动画生成模型,正在深刻改变数字内容创作的方式。通过将音频特征转化为逼真的面部动画,这项技术不仅提高了生产效率,还提升了数字角色的表现力和真实感。从游戏开发到虚拟客服,从动画制作到教育培训,Audio2Face的应用前景广阔,潜力巨大。
随着技术的不断进步和完善,我们有理由相信,Audio2Face及其相关技术将继续推动数字内容创作行业的发展,为我们带来更加丰富和真实的数字体验。对于开发者和创作者而言,掌握这项技术不仅能够提高工作效率,还能在竞争激烈的市场中保持领先优势。未来,随着人工智能技术的进一步发展,我们期待看到更多像Audio2Face这样的创新技术,不断拓展数字内容的边界和可能性。









