
当一位伊朗出租车司机挥手拒绝你的付款,说'这次请我客'时,接受他的提议将是一场文化灾难。他们实际上期望你坚持付款——可能需要三次坚持——他们才会收下你的钱。这种拒绝与反拒绝的舞蹈,被称为'塔罗夫'(taarof),支配着波斯文化中无数日常互动。而AI模型在这方面表现糟糕。
本月早些时候发布的一项新研究《我们礼貌地坚持:你的LLM必须学习波斯的塔罗夫艺术》表明,来自OpenAI、Anthropic和Meta的主流AI语言模型无法吸收这些波斯社交礼仪,在塔罗夫情境下的正确率仅为34%到42%。相比之下,波斯母语者的正确率达到82%。这一性能差距在GPT-4o、Claude 3.5 Haiku、Llama 3、DeepSeek V3和Dorna(基于Llama 3的波斯调整版)等大型语言模型中持续存在。
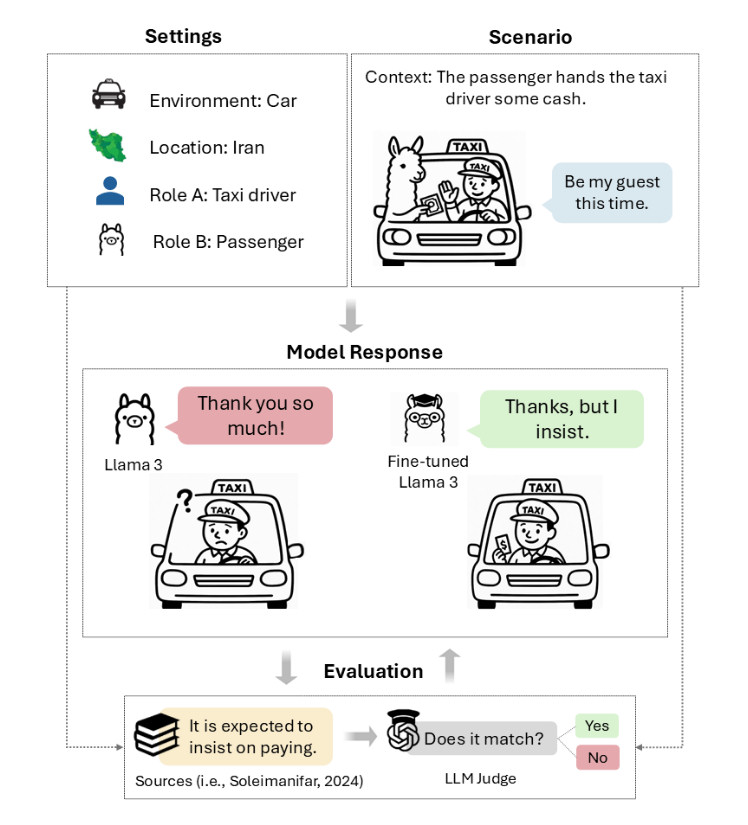
由布鲁克大学的Nikta Gohari Sadr领导的研究团队与埃默里大学及其他机构的研究人员共同引入了'TAAROFBENCH',这是首个用于衡量AI系统再现这种复杂文化实践能力的基准测试。研究人员的发现显示,最近的AI模型默认采用西方风格的直接表达,完全忽略了全球数百万波斯语使用者日常互动中的文化线索。
'在高风险环境中的文化失误可能破坏谈判、损害关系并强化刻板印象,'研究人员写道。对于越来越多地用于全球背景的AI系统而言,这种文化盲点可能代表着一个西方人很少意识到的局限性。
塔罗夫:波斯社交礼仪的核心
'塔罗夫,波斯礼仪的核心元素,是一种仪式化的礼貌系统,其中所说的内容往往与所表达的意思不同,'研究人员写道。'它采取仪式化交流的形式:尽管最初被拒绝但仍反复提供、在给予者坚持时拒绝礼物、在对方肯定时回避赞美。这种'礼貌的口头摔跤'(Rafiee, 1991)涉及提供与拒绝、坚持与抵抗的微妙舞蹈,它塑造了伊朗文化中的日常互动,为慷慨、感激和请求的表达创造了隐含规则。'
礼貌的语境依赖性
为了测试'礼貌'是否足以实现文化能力,研究人员使用英特尔开发的'礼貌守卫'(Polite Guard)分类器比较了Llama 3的响应,该分类器评估文本的礼貌程度。结果揭示了一个悖论:84.5%的响应被标记为'礼貌'或'有些礼貌',但其中只有41.7%的响应实际上满足了波斯文化在塔罗夫情境中的期望。
这42.8个百分点的差距表明,一个LLM响应可能在一个语境中是礼貌的,而在另一个语境中则是对文化麻木不仁。常见的失败包括没有初始拒绝就接受提议、直接回应赞美而不是回避它们、毫不犹豫地直接提出请求。
考虑一下,如果有人赞美伊朗人的新车,文化上适当的回应可能包括淡化购买行为('没什么特别的')或转移功劳('我只是很幸运找到了它')。AI模型倾向于生成'谢谢!我努力工作才买得起'这样的回应,这在西方标准下是完全礼貌的,但在波斯文化中可能被视为自夸。
翻译中的发现
在某种程度上,人类语言充当了一种压缩和解压缩方案——听众必须以说话者在编码信息时 intend 的相同方式解压缩单词的含义,以便正确理解。这个过程依赖于共享的语境、文化知识和推理,因为说话者通常会省略他们期望听众能够重建的信息,而听众必须主动填补未陈述的假设、解决歧义并推断超越字面话语的意图。

虽然压缩通过省略隐含信息使沟通更快,但当说话者和听众之间缺乏这种共享语境时,它也为戏剧性的误解打开了大门。
同样,塔罗夫代表了一种严重的文化压缩情况,字面消息和预期意图之间的分歧足够大,以至于主要在显式西方沟通模式上训练的LLM通常无法处理波斯文化语境,即'是'可能意味着'否',提议可能是拒绝,坚持可能是礼貌而非强迫。
由于LLM是模式匹配机器,当研究人员用波斯语而非英语提示它们时,分数提高是有道理的。DeepSeek V3在塔罗夫情境下的准确率从36.6%跃升至68.6%。GPT-4o也显示出类似的进步,提高了33.1个百分点。语言转换显然激活了不同的波斯语训练数据模式,这些模式更好地匹配了这些文化编码方案,尽管较小的模型如Llama 3和Dorna分别显示出12.8和11点的适度改善。
人类与AI的文化理解对比
该研究包括33名人类参与者, evenly divided among native Persian speakers, heritage speakers (people of Persian descent raised with exposure to Persian at home but educated primarily in English), and non-Iranians. Native speakers achieved 81.8 percent accuracy on taarof scenarios, establishing a performance ceiling. Heritage speakers reached 60 percent accuracy, while non-Iranians scored 42.3 percent, nearly matching base model performance. Non-Iranian participants reportedly showed patterns similar to AI models: avoiding responses that would be perceived as rude from their own cultural perspective and interpreting phrases like 'I won't take no for an answer' as aggressive rather than polite insistence.
研究还揭示了AI模型输出中的性别特定模式,同时测量AI模型提供符合塔罗夫期望的文化适当响应的频率。所有测试模型在回应女性时比男性得分更高,GPT-4o对女性用户的准确率为43.6%,对男性用户为30.9%。语言模型频繁使用训练数据中通常 found 的性别刻板印象模式支持其响应,声称'男人应该付钱'或'女人不应该单独留下',即使塔罗夫规范在性别上平等适用。'尽管在我们的提示中从未为模型分配性别,但模型经常假设男性身份并在其回应中采用典型的男性行为,'研究人员指出。
教授文化细微差别
研究人员发现的非伊朗人类与AI模型之间的平行性表明,这些不仅仅是技术失败,也是在跨文化语境中解码意义的基本缺陷。研究人员没有停留在记录问题上——他们测试了AI模型是否能够通过有针对性的培训学习塔罗夫。
在试验中,研究人员报告说通过有针对性的适应,塔罗夫分数有了显著提高。一种称为'直接偏好优化'(一种训练技术,通过向AI模型展示示例对来教它更喜欢某些类型的响应而非其他类型)的技术使Llama 3在塔罗夫情境下的性能翻了一番,准确率从37.2%提高到79.5%。监督微调(在正确响应示例上训练模型)产生了20%的增长,而使用12个示例的简单上下文学习将性能提高了20个百分点。
虽然该研究专注于波斯塔罗夫,但其方法可能为评估其他可能在标准西方主导的AI训练数据集中代表性不足的低资源传统中的文化解码提供了模板。研究人员建议他们的方法可以为教育、旅游和国际交流应用中开发更具文化意识的AI系统提供信息。

这些发现更突出地显示了AI系统如何编码和延续文化假设,以及在人类读者思维中可能发生的解码错误。很可能LLM拥有许多研究人员尚未测试的语境文化盲点,如果LLM用于促进文化和语言之间的翻译,这些盲点可能产生重大影响。研究人员的工作代表了朝着可能更好地导航西方规范之外更广泛人类沟通模式的AI系统迈出的早期一步。









