
科学记者每天面临的最重要任务之一就是将复杂的科学发现转化为非专业读者能够理解的内容。同时,将复杂文本生成摘要也被频繁提及为大型语言模型(LLM)的最佳应用场景之一。然而,美国科学促进会(AAAS)最新进行的一项为期一年的研究揭示了一个令人意外的发现:ChatGPT在科学论文摘要生成方面表现不佳。
研究背景与方法
从2023年12月到2024年12月,AAAS的研究团队每周选择多达两篇论文,使用三种不同详细程度的提示让ChatGPT进行摘要。研究特别关注包含技术术语、争议性见解、突破性发现、人类受试者或非传统格式等难点的论文。测试使用了研究期间最新公开的GPT模型的"Plus"版本,主要涵盖了GPT-4和GPT-4o时代。
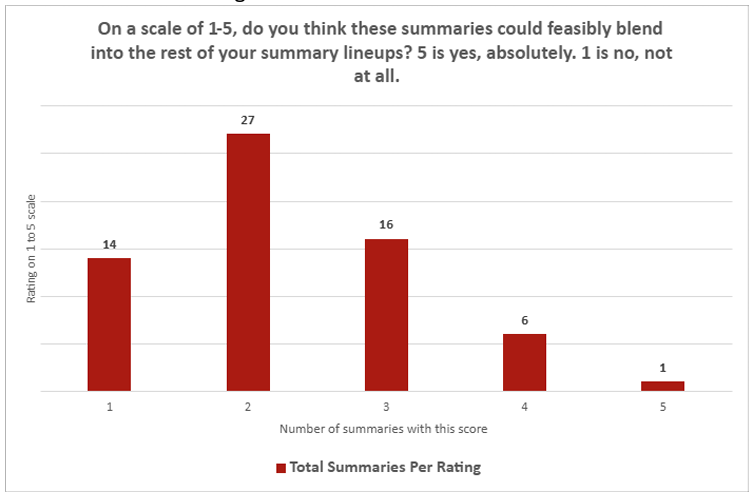
在总共64篇论文的摘要评估中,由撰写过相同论文SciPak摘要的同一批SciPak记者进行定量和定性评估。研究人员指出,这种设计"无法考虑人类偏见",这可能影响记者评估这一可能取代其核心工作职能的工具的客观性。
定量评估结果
定量调查结果相当一边倒。在ChatGPT摘要"是否能够融入您的摘要系列"的问题上,平均得分仅为2.26(1-5分制,1分为"完全不",5分为"绝对可以")。在摘要"是否引人入胜"的问题上,LLM摘要平均得分为2.14。在这两个问题上,只有一份摘要获得了人类评估员的"5"分,而"1"分的评价则高达30次。
质性评估发现
记者们对个别摘要的质性评估揭示了更具体的问题。他们抱怨ChatGPT经常混淆相关性与因果关系,未能提供背景信息(例如,软致动器往往非常缓慢),并且倾向于过度使用"突破性"和"新颖"等词汇来夸大结果(尽管当提示特别指出这一点时,这种行为有所改善)。
AI摘要的核心弱点
研究人员发现,ChatGPT通常擅长"转录"科学论文中已写的内容,特别是当论文没有太多细微差别时。但LLM在"翻译"这些发现方面表现薄弱,无法深入探讨方法、局限性或宏观影响。这些弱点在提供多个不同结果的论文中尤为明显,或者当被要求将两篇相关论文合并为一个摘要时。
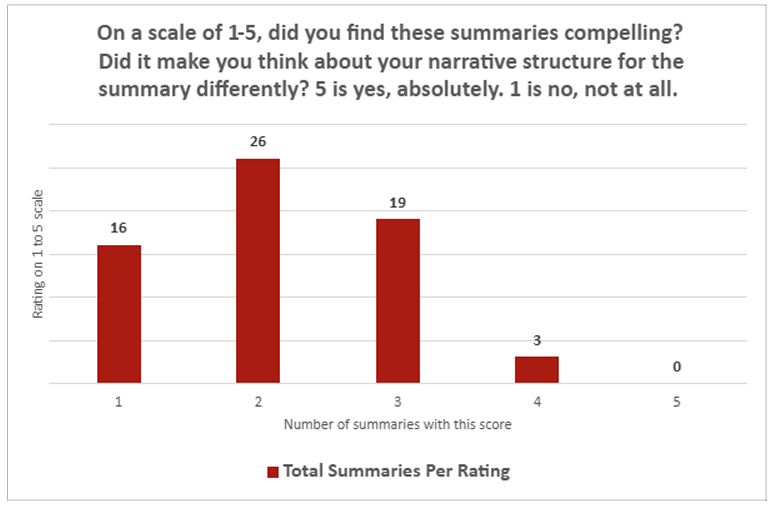
尽管ChatGPT摘要的语调和风格通常与人类撰写的内容匹配,但记者们写道,"对LLM撰写内容的事实准确性担忧"普遍存在。他们补充说,即使将ChatGPT摘要作为人类编辑的"起点",由于需要"广泛的事实核查",所需的工作量"与从头起草摘要相当,甚至更多"。
科学写作的特殊要求
考虑到先前的研究显示AI搜索引擎引用错误新闻来源的比例高达60%,这些结果可能并不令人意外。然而,在讨论科学论文时,这些具体弱点显得尤为突出,因为准确性和沟通清晰度至关重要。
科学记者的工作远不止是简单复述研究结果。他们需要理解研究的方法论局限性,将发现置于更广泛的科学背景下,并以准确且引人入胜的方式传达给非专业读者。这些技能恰恰是当前AI系统所缺乏的。
研究结论与未来展望
最终,AAAS记者得出结论,ChatGPT"不符合SciPak新闻包中简报的风格和标准"。然而,白皮书确实指出,如果ChatGPT"经历重大更新",可能值得再次进行实验。值得一提的是,GPT-5已于2025年8月向公众推出。
这项研究对科学新闻领域具有重要启示。虽然AI工具可能在某些方面辅助科学写作,但目前它们无法完全取代人类记者的专业判断和事实核查能力。科学传播的准确性和可靠性需要人类监督和专业知识。
科学写作的未来
随着AI技术的不断发展,科学记者需要学会如何有效地利用这些工具,同时保持对内容质量的严格把控。未来的科学写作可能会采用人机协作的模式,AI负责初步信息整理和结构化,人类记者则负责确保准确性、提供背景和创造引人入胜的叙事。
对于科学传播领域而言,这项研究提醒我们,技术进步不应以牺牲准确性为代价。在科学信息的传播中,精确性和可靠性始终应该是首要考虑的因素。






