
在人工智能技术飞速发展的今天,大型语言模型(LLM)的训练数据隐私问题日益凸显。科技公司为了构建更强大的AI模型,不断在网络中搜寻更多高质量数据,这可能导致用户敏感数据被用于训练。面对这一挑战,Google Research团队探索出新技术,使大型语言模型更不可能'记忆'任何训练内容,并于近期推出了首个采用差分隐私技术的大模型——VaultGemma。
AI模型与隐私保护的迫切需求
大型语言模型具有非确定性输出的特点,这意味着我们无法精确预测模型会生成什么内容。即使在相同输入的情况下,输出也会有所不同,但模型有时确实会复现训练数据中的内容。如果训练数据包含个人信息,这种输出可能构成用户隐私泄露。同样,当版权数据意外或有意地进入训练数据时,其在输出中的出现也会给开发者带来法律风险。
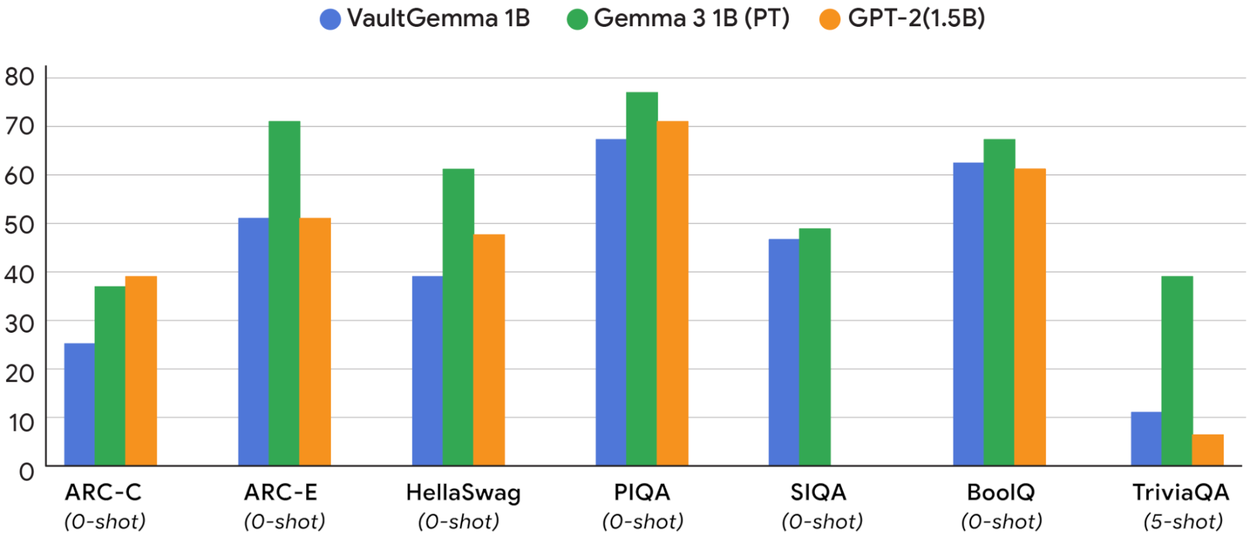
VaultGemma在测试中表现出与同规模非隐私模型相当的性能
差分隐私技术的工作原理
差分隐私技术通过在训练阶段引入校准噪声来防止模型记忆训练数据。然而,将差分隐私应用于模型会带来准确性和计算需求的权衡。在此之前,很少有人研究这种技术对AI模型扩展定律的改变程度。
Google团队从模型性能主要受噪声-批次比率影响的假设出发,该比率比较随机噪声量与原始训练数据的大小。通过在不同模型大小和噪声-批次比率下进行实验,团队建立了差分隐私扩展定律的基本理解,这是计算预算、隐私预算和数据预算之间的平衡。简单来说,更多的噪声会导致更低质量的输出,除非通过更高的计算预算(FLOPs)或数据预算(tokens)来抵消。
VaultGemma的诞生与特点
这项差分隐私研究催生了Google新的开放权重模型——VaultGemma。该模型使用差分隐私来降低记忆的可能性,这可能会改变Google在其未来AI代理中构建隐私的方式。目前,Google的首个差分隐私模型仍是一个实验性产品。
VaultGemma基于Gemma 2基础模型构建,这是Google最新开放模型家族的前一代产品。团队利用从初始测试中得出的扩展定律,以最优差分隐私训练了VaultGemma。从规模上看,这个模型并不特别大,仅有10亿参数。然而,Google Research表示,VaultGemma的性能与同规模非隐私模型相当。
差分隐私扩展定律的意义
Google团队希望这项关于差分隐私扩展定律的研究能帮助其他人高效分配资源,训练出私密的AI模型。这可能不会改变最大和最强AI模型的运作方式——在超大型通用模型中,性能至关重要。无论如何,研究表明差分隐私在小型LLM中效果更好,例如为特定AI功能提供支持的专用模型。

差分隐私技术通过添加噪声保护用户数据隐私
VaultGemma的实际应用与限制
开发者现在可以从Hugging Face和Kaggle下载VaultGemma。与其他Gemma模型一样,这个模型具有开放权重,但并非完全开源。虽然Google允许修改和分发Gemma模型,但用户必须同意不将其用于恶意目的,并在分发所有修改版本时附上Gemma许可证副本。
行业影响与未来展望
VaultGemma的发布标志着AI隐私保护领域的重要进展。随着AI技术深入各行各业,数据隐私问题日益受到关注。差分隐私技术作为一种有效的隐私保护手段,将在未来AI发展中扮演越来越重要的角色。
Google的这一创新或将推动整个行业重新思考AI模型的训练方式,在追求性能提升的同时,更加注重用户隐私保护。未来,我们可以期待更多基于差分隐私技术的AI模型出现,以及相关标准和规范的完善。
技术挑战与解决方案
尽管差分隐私技术为AI隐私保护提供了新的思路,但仍面临诸多挑战。首先是计算成本的增加,添加噪声需要更多的计算资源。其次是模型性能与隐私保护之间的平衡,如何在保证隐私的同时维持模型的高性能是关键问题。
Google团队通过建立差分隐私扩展定律,为解决这些问题提供了理论依据和实践指导。通过调整噪声-批次比率,开发者可以根据实际需求在隐私保护和模型性能之间找到最佳平衡点。
隐私保护技术的多元化发展
除了差分隐私外,AI隐私保护领域还有多种技术路线,如联邦学习、安全多方计算、同态加密等。这些技术各有特点,适用于不同的应用场景。VaultGemma的发布表明,Google正在积极探索多种隐私保护技术,以构建更安全、更可靠的AI系统。

多种隐私保护技术为AI发展提供安全保障
结论
VaultGemma的发布不仅展示了Google在AI隐私保护领域的技术实力,也为整个行业提供了宝贵的经验和参考。随着AI技术的不断发展,隐私保护将成为衡量AI系统质量的重要指标之一。我们有理由相信,在技术、政策和法规的共同推动下,AI与隐私保护将实现更好的平衡,为人类社会带来更安全、更可靠的人工智能服务。









