
LLaDA,全称为Large Language Diffusion with mAsking,是由中国人民大学高瓴AI学院李崇轩、文继荣教授团队与蚂蚁集团联合推出的一种新型大型语言模型。与传统的自回归模型(ARM)不同,LLaDA采用了扩散模型框架,为大语言模型的设计提供了新的思路。
LLaDA模型的核心在于其基于正向掩蔽过程和反向恢复过程对文本分布进行建模。正向掩蔽过程中,文本中的一部分标记(tokens)会被逐渐掩盖;而在反向恢复过程中,模型则需要逐步恢复这些被掩盖的标记。这一过程类似于图像扩散模型中的噪声添加和去噪过程,但应用于文本领域。为了实现这一目标,LLaDA使用了Transformer架构作为掩蔽预测器,负责预测被掩盖的标记。通过优化似然下界(Evidence Lower Bound, ELBO),LLaDA能够在生成任务中实现高效的学习和推理。
在模型训练方面,LLaDA采用了大规模的预训练和监督微调(SFT)相结合的方法。预训练阶段,LLaDA使用了包含2.3万亿标记(tokens)的数据集进行无监督学习,使模型能够捕捉到丰富的语言知识和模式。随后,通过监督微调,LLaDA能够更好地理解和执行人类的指令,从而提升其在特定任务上的性能。LLaDA在可扩展性、上下文学习和指令遵循等方面均表现出色,并且在反转推理任务中能够有效解决传统ARM所面临的“反转诅咒”问题。所谓“反转诅咒”,指的是自回归模型在处理反向推理任务时,性能会显著下降的现象。
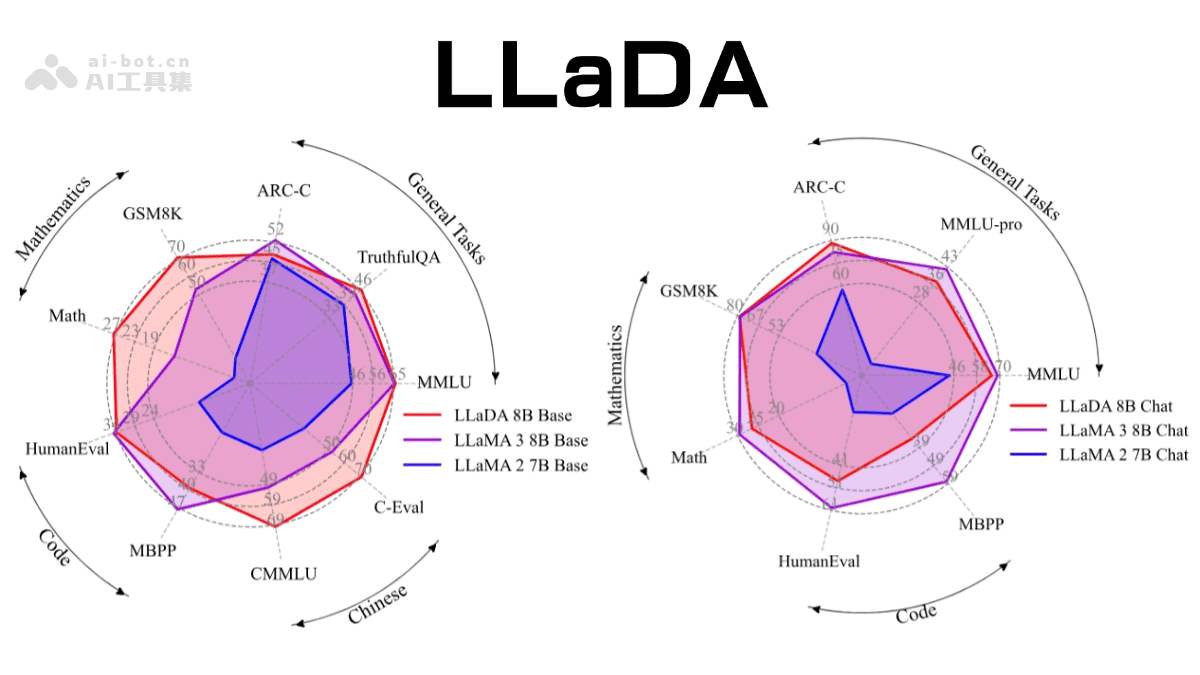
LLaDA模型的8B参数版本在多个基准测试中表现出色,与LLaMA3等强模型相媲美,展示了扩散模型作为自回归模型替代方案的巨大潜力。这一成果不仅为自然语言处理领域带来了新的思路,也为未来大语言模型的发展方向提供了有益的参考。
LLaDA的主要功能
LLaDA模型具备多项强大的功能,使其在各种应用场景中都能发挥重要作用。
首先,LLaDA能够高效生成文本。它能够生成高质量、连贯的文本内容,适用于写作、对话、内容创作等多种场景。无论是生成新闻报道、撰写产品描述,还是进行创意写作,LLaDA都能够提供强大的支持。
其次,LLaDA具有强大的上下文学习能力。这意味着模型能够根据给定的上下文快速适应新的任务。例如,在阅读了一篇关于科技的文章后,LLaDA能够更好地理解和生成与科技相关的内容;在学习了一种新的编程语言的语法后,LLaDA能够更快地掌握该语言的编程技巧。
第三,LLaDA具备出色的指令遵循能力。它能够更好地理解和执行人类的指令,适用于多轮对话、问答和任务执行等场景。用户可以通过自然语言与LLaDA进行交互,指示其完成各种任务,例如翻译文本、生成摘要、回答问题等。
第四,LLaDA拥有双向推理能力。这使得它能够解决传统自回归模型所面临的“反转诅咒”问题。在正向和反向推理任务中,LLaDA均表现出色。例如,在诗歌补全任务中,LLaDA不仅能够根据诗歌的前半部分生成后半部分,还能够根据诗歌的后半部分推断出前半部分。
最后,LLaDA具有多领域适应性。它在语言理解、数学、编程、中文理解等多个领域均表现出色,具有广泛的适用性。无论是处理自然语言任务,还是解决数学问题,亦或是生成代码,LLaDA都能够提供有力的支持。
LLaDA的技术原理
LLaDA的技术原理主要包括以下几个方面:
扩散模型框架:LLaDA基于正向掩蔽过程(逐渐将文本中的标记掩蔽)和反向恢复过程(逐步恢复被掩蔽的标记)建模文本分布。这种框架允许模型以非自回归的方式生成文本,从而避免了传统自回归模型的顺序生成限制。在正向掩蔽过程中,文本中的一部分标记会被随机地或根据一定的策略进行掩盖,从而生成一个部分被掩盖的文本序列。在反向恢复过程中,模型需要根据上下文信息,逐步恢复这些被掩盖的标记,最终生成完整的文本序列。通过这种方式,LLaDA能够学习到文本的深层结构和语义信息。
掩蔽预测器:LLaDA使用Transformer架构作为掩蔽预测器,输入部分掩蔽的文本序列,预测所有掩蔽标记。这种架构能够捕捉双向依赖关系,而不仅仅是单向的左到右生成。Transformer是一种基于自注意力机制的神经网络架构,具有强大的序列建模能力。在LLaDA中,Transformer被用作掩蔽预测器,接收部分被掩盖的文本序列作为输入,并预测所有被掩盖的标记。通过这种方式,LLaDA能够捕捉到文本中各个标记之间的双向依赖关系,从而生成更加连贯和自然的文本。
优化似然下界:LLaDA基于优化似然下界训练模型,在生成建模中是原理性的,确保模型在大规模数据和模型参数下的可扩展性和生成能力。似然下界(Evidence Lower Bound, ELBO)是一种用于近似计算模型似然函数的数学工具。在LLaDA中,通过优化似然下界,可以使得模型在训练过程中更加稳定和高效,从而提高模型的生成能力和泛化能力。
预训练与监督微调:LLaDA基于预训练和监督微调(SFT)相结合的方式。预训练阶段用大规模文本数据进行无监督学习,SFT阶段基于标注数据提升模型的指令遵循能力。预训练是指使用大规模的无标注数据对模型进行训练,使其能够学习到通用的语言知识和模式。监督微调是指使用标注数据对预训练模型进行微调,使其能够更好地适应特定的任务。通过将预训练和监督微调相结合,LLaDA能够充分利用大规模数据和标注数据,从而提高模型的性能。
灵活的采样策略:在生成过程中,LLaDA支持多种采样策略(如随机掩蔽、低置信度掩蔽、半自回归掩蔽等),平衡生成质量和效率。采样策略是指在生成文本的过程中,如何选择下一个要生成的标记。LLaDA支持多种采样策略,例如随机掩蔽、低置信度掩蔽、半自回归掩蔽等。不同的采样策略可以平衡生成质量和效率,从而满足不同应用场景的需求。
LLaDA的项目地址
以下是LLaDA项目的相关链接:
- 项目官网:https://ml-gsai.github.io/LLaDA
- GitHub仓库:https://github.com/ML-GSAI/LLaDA
- arXiv技术论文:https://arxiv.org/pdf/2502.09992
LLaDA的应用场景
LLaDA模型具有广泛的应用场景,以下列举了一些典型的应用:
- 多轮对话:LLaDA可以用于构建智能客服、聊天机器人等应用,支持流畅的多轮交流。用户可以通过自然语言与LLaDA进行交互,获取所需的信息或完成特定的任务。例如,用户可以向LLaDA询问天气情况、预订机票、查询商品信息等。
- 文本生成:LLaDA适用于写作辅助、创意文案等场景,能够生成高质量的文本。无论是生成新闻报道、撰写产品描述,还是进行创意写作,LLaDA都能够提供强大的支持。例如,用户可以向LLaDA提供一些关键词或主题,让其生成一篇相关的文章。
- 代码生成:LLaDA可以帮助开发者生成代码片段或修复错误,从而提升编程效率。开发者可以向LLaDA描述所需的功能或问题,让其生成相应的代码或提供解决方案。例如,用户可以向LLaDA描述一个算法,让其生成相应的代码实现。
- 数学推理:LLaDA可以解决数学问题,提供解题步骤,适用于教育领域。学生可以使用LLaDA来辅助学习数学,解决数学难题。例如,学生可以向LLaDA提问一个数学问题,让其提供解题步骤和答案。
- 语言翻译:LLaDA可以实现多语言翻译,促进跨文化交流。用户可以使用LLaDA将文本从一种语言翻译成另一种语言,从而方便跨语言交流。例如,用户可以将一篇英文文章翻译成中文,或者将一篇中文文章翻译成英文。








