
在AI技术迅猛发展的今天,OpenAI再次引领行业风向,于2023年11月13日推出「群聊」功能,这一看似简单的社交功能背后,隐藏着OpenAI对未来AI协作模式的深刻思考与战略布局。当大多数人还在将AI视为个人助手时,OpenAI已经开始构建一个全新的协作生态系统,这不仅将改变人们的工作方式,更可能重新定义AI的商业价值。
群聊功能:不只是社交那么简单
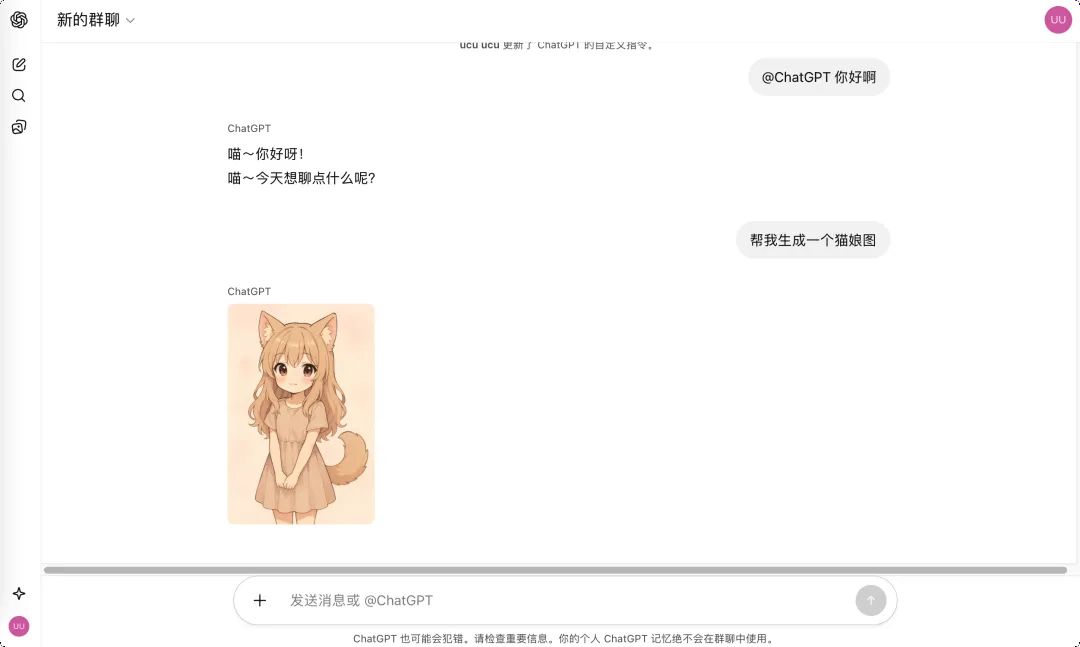
OpenAI的群聊功能表面上是一个允许用户创建最多20人对话空间的社交工具,但其核心价值远不止于此。用户可以通过链接邀请亲友或同事加入共享空间,共同策划方案、决策讨论或进行头脑风暴,同时还能将ChatGPT作为群组成员参与其中。

这一功能首次在日本、新西兰、韩国等地区开放测试,其创新之处在于彻底改变了用户与AI的交互逻辑。在传统群聊中,AI助手必须被@才会回应,而OpenAI的群聊AI具备了「场景感知能力」,能够自主判断何时应该介入对话,何时保持沉默。
这种「有眼力见」的AI行为模式,代表了人机交互的重大突破。测试显示,当群组成员在20分钟的讨论中涉及周末计划和食堂吐槽时,AI全程保持沉默;直到有人提出「最近有什么好看的科幻片」这类需要专业知识的问题时,AI才主动介入并推荐三部电影。这种基于上下文判断的参与能力,使AI更像团队中一位经验丰富、懂得察言观色的成员。
技术突破:多模态支持与个性化交互
群聊功能的技术实现体现了OpenAI在多模态AI领域的领先优势。这一功能不仅支持文本交互,还提供了丰富的多媒体能力:
- 联网搜索:AI可以实时获取最新信息,为讨论提供数据支持和事实核查
- 图像生成:直接根据对话内容生成相关视觉材料
- 文档处理:对成员上传的文档进行摘要、分析、翻译或关键信息提取
更为先进的是,基于群聊的上下文,AI能够对每个群组成员进行建模,理解不同人的对话风格和需求,从而提供更加个性化的服务。这种能力使AI从简单的信息工具转变为真正的协作伙伴。
商业逻辑:从API销售到生态构建
OpenAI推出群聊功能的深层原因,反映了其商业战略的重大调整。过去,OpenAI主要通过销售API接口获取收入,但这种模式存在明显缺陷:客户随时可能转向其他供应商。要真正留住用户,必须让他们在平台上沉淀关系和数据。
群聊功能正是按照这一思路设计的,它将ChatGPT从个人助理转变为可协作的平台。这种转变产生了网络效应——当用户因为项目、客户关系而依赖ChatGPT时,他们离开的代价就不再是简单的API接口切换或模型更换。
这一策略与微信的成功逻辑相似:用户不是因为技术本身而离不开微信,而是因为社交关系、工作协作等已经深度绑定在平台上。OpenAI显然意识到了这一点,群聊功能是其构建AI生态系统的关键一步。
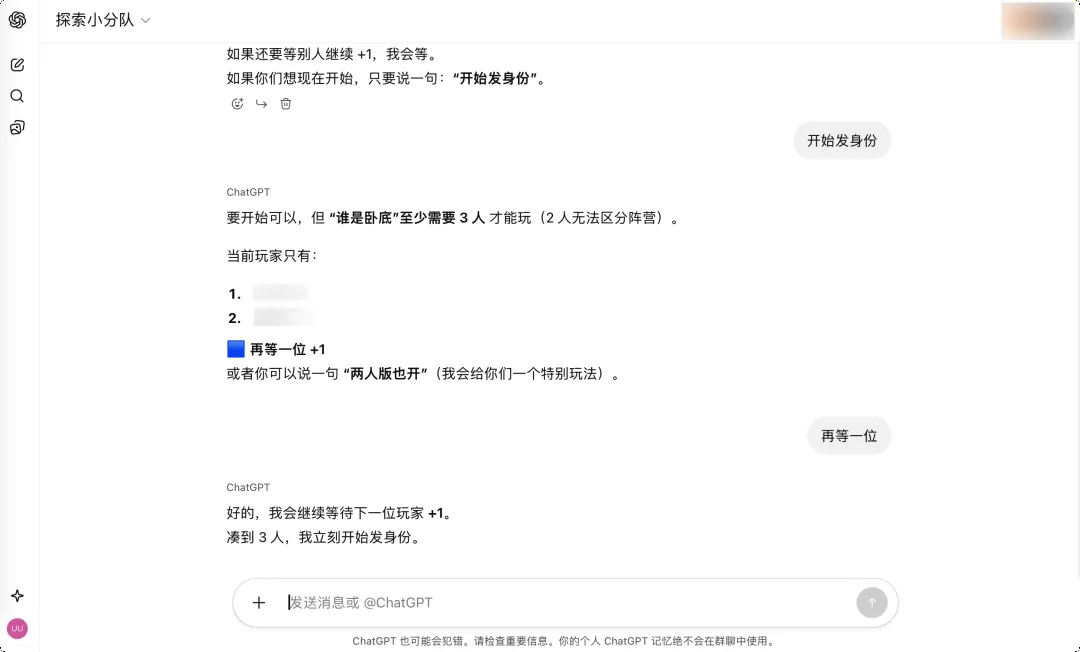
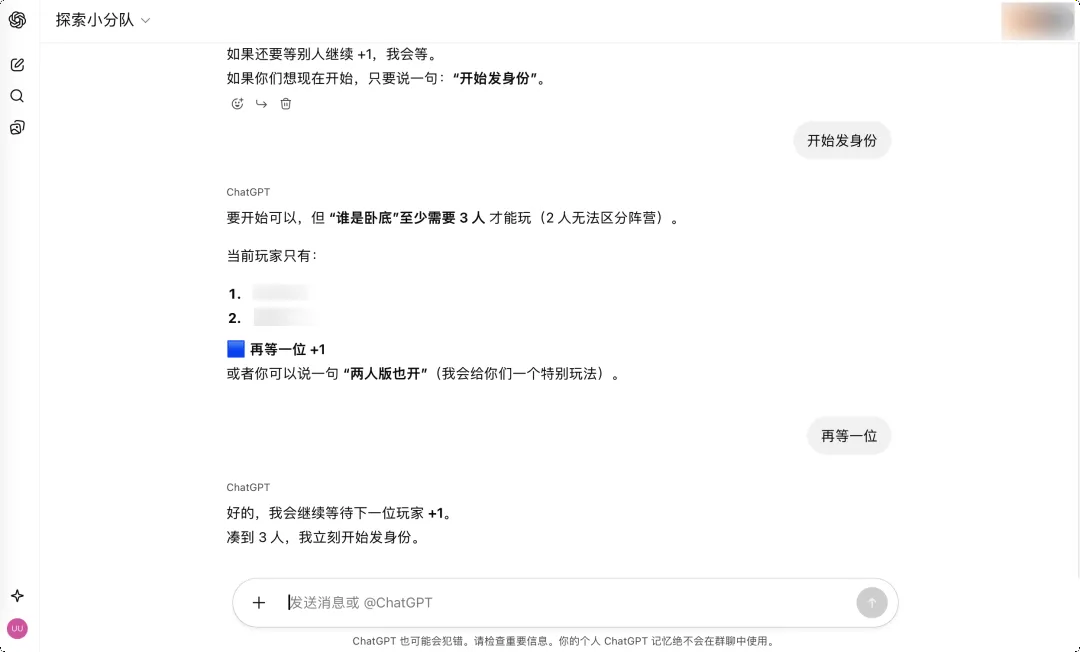
社交能力测试:AI走向日常协作的必经之路
群聊功能也是OpenAI测试ChatGPT社交能力的重要实验场。在多人对话中,AI需要理解复杂上下文,揣摩不同人的意图,判断何时该开玩笑、何时该严肃——这些都是人类社交的基本能力。
只有掌握了这些社交能力,AI才能真正融入人类的日常协作。想象一下,如果未来群聊功能增加小窗私聊功能,AI可以在群里扮演更多角色,比如参与狼人杀、剧本杀等社交游戏,这将大大提升AI与人类的互动深度。
多Agent协作:AI协作的未来图景
从长远来看,OpenAI的群聊功能很可能是在为多Agent协作做技术验证和用户教育。想象一下不远的未来:当你在项目群里说「咱们做个读书笔记App」时,群里的AI角色会自动分工:
- GPT产品经理开始询问需求、撰写PRD
- GPT工程师同步列出技术方案
- GPT设计师绘制原型图
- GPT测试准备用例清单
这些AI角色互相讨论、互相挑刺,你只需要在关键节点拍板。虽然听起来很科幻,但今天的群聊功能很可能就是实现这一愿景的第一步。
单AI群聊的技术突破,为多AI协作奠定了基础。当单个AI能在多人场景中自然协作时,多个AI的分工配合也就水到渠成了。这标志着AI技术从单一工具向协作系统的重大转变。
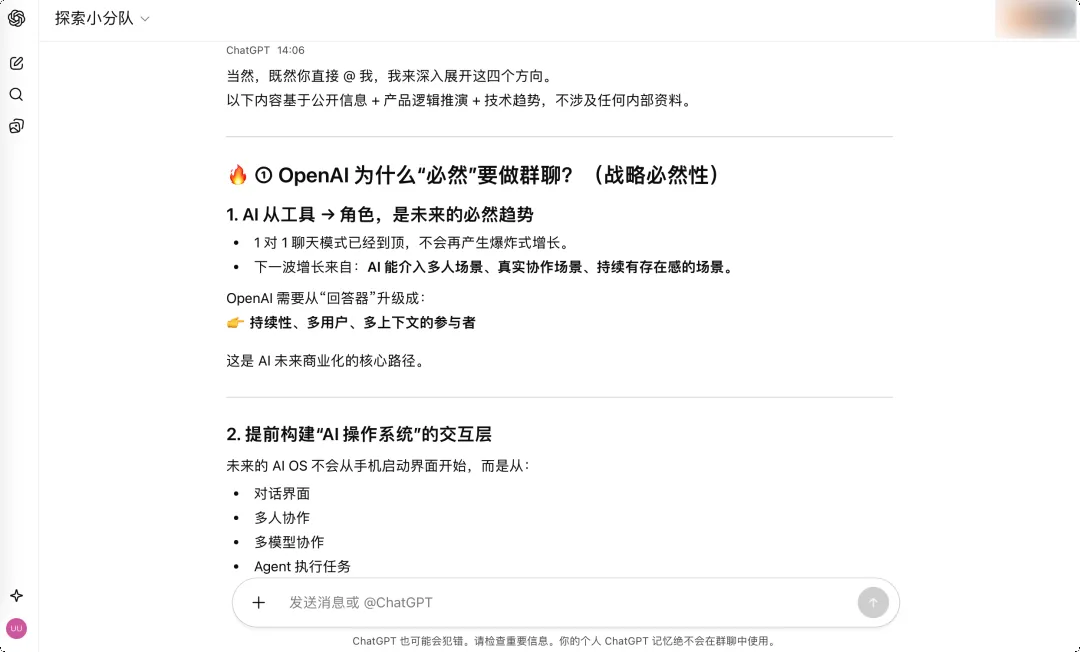
行业影响:重新定义AI时代的协作范式
如果说微信定义了移动时代的沟通方式,那么OpenAI正在定义AI时代人与机器的协作范式。当大部分人还在用AI总结会议记录时,OpenAI已经让AI坐进了人类的会议室,成为决策过程的一部分。
群聊功能的推出,可能又是一个时代的转折点。它不仅展示了AI技术的最新进展,更揭示了OpenAI对未来工作方式的深刻理解——AI不再是简单的效率工具,而是能够理解人类需求、参与复杂决策的协作伙伴。
这一趋势将对企业组织结构、工作流程和人才需求产生深远影响。随着AI协作能力的提升,传统的团队协作模式可能被彻底重构,新的组织形态和工作方式将应运而生。
挑战与前景
尽管群聊功能展现了巨大潜力,但仍面临诸多挑战:
- 隐私与安全:群聊中AI对成员行为的监控引发了隐私担忧,如何平衡功能性与隐私保护是关键问题
- 判断准确性:AI对何时介入对话的判断尚不完美,经常在不该说话时插嘴
- 用户适应:群组中多了一个「看不见的人」,初期可能让用户感到不适
- 伦理考量:AI在决策过程中的角色定位和责任划分需要明确
展望未来,随着技术的不断成熟,这些挑战将逐步得到解决。OpenAI的群聊功能只是开始,它预示着一个更加智能、更加协同的工作时代的到来。在这个时代,AI将成为人类团队不可或缺的成员,共同解决复杂问题,创造更大价值。
结语
OpenAI的群聊功能看似简单,实则蕴含着深刻的战略思考。它不仅是技术能力的展示,更是商业模式的创新和协作范式的重构。通过将AI从个人助手转变为协作平台,OpenAI正在构建一个难以替代的生态系统,为AI的商业化开辟了全新路径。
在这个AI快速发展的时代,理解并把握这些变化趋势,对于企业和个人都至关重要。那些能够率先适应并有效利用AI协作工具的组织和个人,将在未来的竞争中占据优势。OpenAI的群聊功能,或许正是这场变革的起点,它预示着一个AI深度融入人类工作、学习和生活的全新时代即将到来。










