
在人工智能技术持续渗透各行各业的今天,Google再次展示了其'AI无处不在'的战略雄心。最新宣布的Google Finance更新将Gemini Deep Research功能正式引入这一广受欢迎的金融平台,并与Kalshi和Polymarket两大预测市场领导者合作,引入预测市场数据作为AI分析的基础。这一创新不仅提升了金融信息的获取效率,更开创了AI与金融分析深度融合的新范式。
Gemini Deep Research:金融分析的新维度
Google此次更新的核心是将Gemini Deep Research功能整合到Google Finance的聊天机器人中。这一功能将使用户能够提出远比以往复杂的问题,并获取'完全引用'的研究报告。与简单的查询不同,Deep Research特别适合处理需要深入分析的多维度问题,如复杂的市场趋势分析、跨行业影响评估等。
Google明确表示,Deep Research并非旨在取代简单的信息查询,而是针对那些需要深度挖掘和综合分析的问题。用户输入提示后,系统将在后台进行处理,并在稍后提供结构化的研究报告。这种'异步处理'模式既保证了分析质量,又不会让用户长时间等待。
使用场景与限制
Google Finance的Deep Research功能将对所有美国用户开放,并在未来几周内扩展至印度。虽然具体的免费使用限额尚未明确,但可以预见的是,与Gemini应用中的设置类似,免费用户可能会面临每月几次的使用限制,而AI Pro和AI Ultra订阅用户将享有更高的配额——分别为每天20份和200份深度研究报告。
值得注意的是,生成一份深度研究报告需要相当长的时间,这使得即使对于高级订阅用户而言,每天200次的限额也几乎难以达到。这种设计既考虑了系统负载,也确保了分析质量不会因过度使用而下降。
预测市场数据:AI预测的'群体智慧'
此次更新的另一大亮点是Google与Kalshi和Polymarket两大预测市场平台的合作。这些平台允许用户对几乎任何未来事件进行投注,从产品发布时间到政策变化,再到社交媒体活动等,无所不包。据统计,尽管只有12.7%的Polymarket加密钱包显示盈利,但这些平台确实汇聚了大量基于真实资金投入的预测信息。
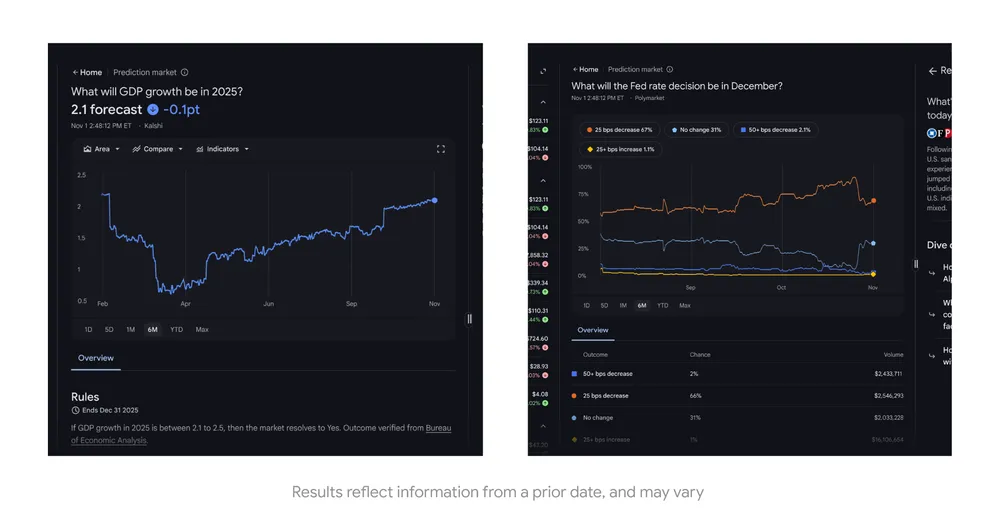
Google将从这两个平台获取实时预测数据,利用'群体智慧'原理,让AI能够基于市场共识回答关于未来的问题。例如,用户可以询问'2025年的GDP增长率会是多少?',系统将提取Kalshi和Polymarket上的最新概率数据,生成包含图表和预测分析的回应。
预测市场的价值与局限
预测市场之所以受到Google的青睐,是因为它们反映了参与者基于经济激励的集体判断。当人们需要用真金白银为自己的预测下注时,他们往往会更加谨慎和理性,这种机制产生的数据往往比传统调查或专家预测更为准确。
然而,Google也明确表示不对这些预测的准确性做出承诺。毕竟,金融市场瞬息万变,即使是基于'群体智慧'的AI预测也存在不确定性。这种诚实透明的态度反而增强了用户对系统的信任。
技术实现与用户体验
从技术角度看,Google Finance的这次更新代表了AI与金融数据融合的前沿实践。Deep Research功能需要处理大量结构化和非结构化数据,包括历史财务数据、市场新闻、研究报告以及预测市场数据等。这些数据需要经过清洗、标准化和关联处理,才能生成有价值的分析报告。
在用户体验方面,Google保持了其一贯的简洁直观风格。用户只需在搜索框中输入问题,系统会自动判断是否需要使用Deep Research功能。对于需要预测的问题,系统会自动整合预测市场数据,并以易于理解的可视化方式呈现结果。
行业影响与未来展望
Google Finance的这次更新可能会对金融信息行业产生深远影响。传统金融数据提供商如Bloomberg和Reuters可能面临来自AI驱动的免费或低成本平台的竞争压力。同时,这一创新也可能改变投资者获取信息和分析决策的方式,使更广泛的人群能够获得专业级的金融分析能力。
未来,我们可以预见更多AI驱动的金融分析工具将涌现,它们可能会整合更多类型的数据源,如卫星图像、社交媒体情绪分析等,提供更加全面和及时的金融洞察。Google此次的尝试无疑为这一趋势奠定了基础。
挑战与考量
尽管前景广阔,Google Finance的AI功能仍面临诸多挑战。首先是数据质量和准确性的问题,预测市场数据虽然有价值,但并非总是可靠。其次是系统解释性的问题,AI生成的预测需要足够的透明度,让用户理解其依据和局限性。最后是伦理考量,如何确保AI不会放大市场偏见或导致过度依赖,也是Google需要谨慎处理的。
结语
Google将Gemini Deep Research与预测市场数据引入Google Finance,不仅是对其'AI无处不在'战略的又一次实践,更是金融科技领域的一次重要创新。通过结合AI的分析能力和预测市场的'群体智慧',这一功能为用户提供了前所未有的金融分析工具。虽然仍面临挑战,但这一探索无疑为AI与金融的深度融合指明了方向,可能彻底改变未来人们获取和理解金融信息的方式。










