
在人工智能领域,DeepSeek无疑是2025年最受瞩目的焦点之一。这家公司以惊人的速度和效率,利用2048张H800 GPU在短短两个月内训练出了一款能够与全球顶尖模型相媲美的大语言模型,颠覆了以往大模型训练的认知。DeepSeek的出现,让人们开始重新审视AI军备竞赛的模式,并对AI的未来发展充满期待。
对于许多像我一样的人工智能新手来说,如何快速入门DeepSeek成为了一个迫切的需求。幸运的是,清华大学新闻与传播学院新媒体研究中心元宇宙文化实验室的余梦珑博士后团队为我们带来了福音。他们精心撰写了一份详尽的学习指南——《DeepSeek从入门到精通2025》,这份报告共计104页,涵盖了DeepSeek的核心技术、应用场景、提示词优化等多个方面,甚至还分享了如何避免AI幻觉、如何精准设计提示语等实战经验。我相信,这份指南对于想要全面了解和使用DeepSeek的用户来说,无疑是一份宝贵的资源。
为了让更多人能够轻松上手DeepSeek,我特意结合这份学习指南,为大家整理了一篇入门教程。希望通过本文,能够帮助大家快速了解DeepSeek的基本概念、功能和应用,为未来的深入学习打下坚实的基础。
什么是DeepSeek?
DeepSeek,中文名为“深度求索”,既代表着一家充满活力的人工智能公司,也代表着该公司所推出的一系列先进的人工智能产品。
DeepSeek由杭州深度求索人工智能基础技术研究有限公司倾力打造。这家公司背后有着量化对冲基金幻方量化的强大支持,于2023年7月17日在杭州市拱墅区市场监督管理局正式成立。其核心团队由人工智能等领域的顶尖专家组成,他们在学术界和产业界都拥有着深厚的积累。
自成立以来,DeepSeek已经发布了多款令人瞩目的语言模型,每一款都代表着AI技术的最新进展:
DeepSeek Coder (2023年11月2日):这是一个由多个代码语言模型组成的强大工具,它在高达2万亿token的数据集上进行了训练,其中代码占比高达87%。DeepSeek Coder拥有1B到33B的不同版本,能够支持项目级别的代码补全和填充,并在多种编程语言和基准测试中展现出领先的性能。
DeepSeek LLM (2024年1月5日):这款拥有670亿参数的大型语言模型,同样在2万亿token的数据集上进行了训练,涵盖了中文和英文。DeepSeek LLM在推理、编码、数学和中文理解等方面表现出色,甚至在匈牙利国家高中考试中取得了65分的优异成绩,其中文表现超越了GPT-3.5。
DeepSeek Math (2024年2月5日):这款模型以DeepSeek-Coder-v1.5 7B为基础,在5000亿token的数学相关数据上进行了预训练。DeepSeek Math在竞赛级别的MATH基准测试中取得了51.7%的成绩,性能直逼Gemini-Ultra和GPT-4。
DeepSeek-VL (2024年3月11日):这是一个开源的视觉-语言模型,采用了混合视觉编码器,能够处理高分辨率图像。DeepSeek-VL在广泛的视觉-语言基准测试中表现出色,性能领先。
DeepSeek-V2 (2024年5月7日):这款模型拥有高达2360亿的参数,其中文综合能力在众多开源模型中堪称最强,英文综合能力也与LLaMA3-70B处于同一水平。DeepSeek-V2的训练效率非常高。
DeepSeek-Coder-V2 (2024年6月17日):这是一个开源的混合专家代码语言模型,它以DeepSeek-V2的中间检查点为起点,进一步预训练了6万亿token的数据。DeepSeek-Coder-V2的编码和数学推理能力得到了显著增强,支持多达338种编程语言,上下文长度扩展到了惊人的128K。
DeepSeek-V2.5 (2024年9月5日):这款模型由DeepSeek Coder V2和DeepSeek V2 Chat合并升级而成,在评测中与GPT-4-Turbo等闭源模型处于同一水平。DeepSeek-V2.5的英文综合能力与LLaMA3-70B相当,并在写作任务、指令跟随等方面进行了优化。
DeepSeek-VL2 (2024年12月13日):这是一个大型的混合专家视觉-语言模型,在视觉问答、光学字符识别等多种任务中表现卓越。DeepSeek-VL2有Tiny、Small和无后缀三个变体。
DeepSeek-V3 (2024年12月26日):这款模型拥有高达6710亿的参数,是一个混合专家模型,激活参数为370亿,在14.8万亿token上进行了预训练。DeepSeek-V3在多项评测中超越了Qwen2.5-72B和Llama-3.1-405B等开源模型,知识类任务能力得到了显著提升。
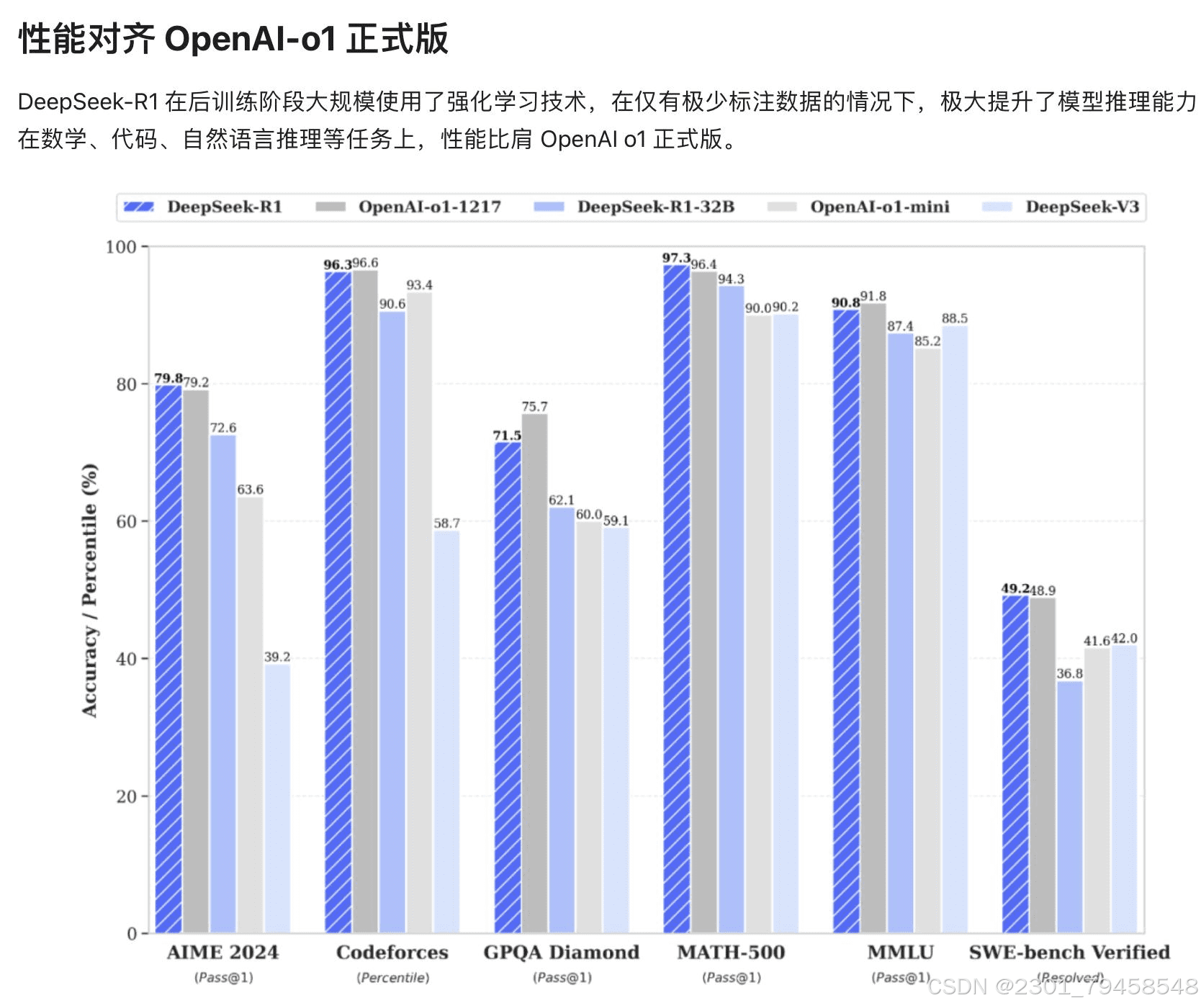
DeepSeek-R1 (2025年1月20日):这款模型在数学、代码、自然语言推理等任务上的性能可以与OpenAI的o1正式版相媲美。通过大规模强化学习和冷启动技术,DeepSeek-R1专注于推理和多模态任务。
Janus-Pro (2025年1月):这是一款多模态大模型,标志着DeepSeek正式进军文生图领域。
在了解了DeepSeek的众多产品之后,一个关键的问题浮出水面:我们现在要学习的DeepSeek究竟指的是哪一款产品呢?
答案是DeepSeek-R1,这款在性能上能够与OpenAI o1相媲美的大语言模型。接下来,我们将深入了解DeepSeek-R1。
什么是DeepSeek-R1?
DeepSeek-R1是幻方量化旗下大模型公司DeepSeek研发的首代开源推理大型语言模型,它的出现无疑为人工智能领域注入了新的活力。
发布时间:
2024年11月20日,DeepSeek-R1-Lite预览版在网页端上线,让用户能够提前体验其强大的功能。
2025年1月20日,DeepSeek正式发布DeepSeek-R1模型,并同步开源模型权重,为研究者和开发者提供了宝贵的资源。
模型架构:
- DeepSeek-R1采用了深度Transformer架构,并以DeepSeek-V3-Base模型为基础。它使用了V3的数十亿参数的密集Transformer Base子模型进行初始化,并利用自研的“群组相对策略优化”(GRPO)算法进行强化学习训练,从而实现了性能的飞跃。
训练方法:
- DeepSeek-R1的训练流程采取了多阶段逐步增强策略,包括冷启动监督微调、第一阶段强化学习、拒绝采样与二次监督微调、第二阶段强化学习。这种精细化的训练方法,确保了模型能够不断提升自身的性能。
主要功能:
- DeepSeek-R1通过强化学习训练,推理过程包含了大量的反思和验证,思维链长度可达数万字。在数学、代码以及各种复杂逻辑推理任务上,DeepSeek-R1取得了媲美OpenAI o1-preview的推理效果,并能够为用户展现o1没有公开的完整思考过程。这使得用户能够更好地理解模型的推理过程,并从中学习。
DeepSeek-R1 能够做什么?
DeepSeek-R1的应用场景非常广泛,它可以直接面向用户或者支持开发者,提供智能对话、文本生成、语义理解、计算推理、代码生成补全等多种服务。
更令人兴奋的是,DeepSeek-R1还支持联网搜索与深度思考模式,同时支持文件上传,能够扫描读取各类文件及图片中的文字内容。这使得DeepSeek-R1能够更好地理解用户的需求,并提供更加个性化的服务。
以文本生成为例,我们可以通过下面的UML图来进行展示:
#mermaid-svg-0AI3KwMQ863LOtkP {font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;fill:#333;}#mermaid-svg-0AI3KwMQ863LOtkP .error-icon{fill:#552222;}#mermaid-svg-0AI3KwMQ863LOtkP .error-text{fill:#552222;stroke:#552222;}#mermaid-svg-0AI3KwMQ863LOtkP .edge-thickness-normal{stroke-width:2px;}#mermaid-svg-0AI3KwMQ863LOtkP .edge-thickness-thick{stroke-width:3.5px;}#mermaid-svg-0AI3KwMQ863LOtkP .edge-pattern-solid{stroke-dasharray:0;}#mermaid-svg-0AI3KwMQ863LOtkP .edge-pattern-dashed{stroke-dasharray:3;}#mermaid-svg-0AI3KwMQ863LOtkP .edge-pattern-dotted{stroke-dasharray:2;}#mermaid-svg-0AI3KwMQ863LOtkP .marker{fill:#333333;stroke:#333333;}#mermaid-svg-0AI3KwMQ863LOtkP .marker.cross{stroke:#333333;}#mermaid-svg-0AI3KwMQ863LOtkP svg{font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;}#mermaid-svg-0AI3KwMQ863LOtkP .actor{stroke:hsl(259.6261682243, 59.7765363128%, 87.9019607843%);fill:#ECECFF;}#mermaid-svg-0AI3KwMQ863LOtkP text.actor>tspan{fill:black;stroke:none;}#mermaid-svg-0AI3KwMQ863LOtkP .actor-line{stroke:grey;}#mermaid-svg-0AI3KwMQ863LOtkP .messageLine0{stroke-width:1.5;stroke-dasharray:none;stroke:#333;}#mermaid-svg-0AI3KwMQ863LOtkP .messageLine1{stroke-width:1.5;stroke-dasharray:2,2;stroke:#333;}#mermaid-svg-0AI3KwMQ863LOtkP #arrowhead path{fill:#333;stroke:#333;}#mermaid-svg-0AI3KwMQ863LOtkP .sequenceNumber{fill:white;}#mermaid-svg-0AI3KwMQ863LOtkP #sequencenumber{fill:#333;}#mermaid-svg-0AI3KwMQ863LOtkP #crosshead path{fill:#333;stroke:#333;}#mermaid-svg-0AI3KwMQ863LOtkP .messageText{fill:#333;stroke:#333;}#mermaid-svg-0AI3KwMQ863LOtkP .labelBox{stroke:hsl(259.6261682243, 59.7765363128%, 87.9019607843%);fill:#ECECFF;}#mermaid-svg-0AI3KwMQ863LOtkP .labelText,#mermaid-svg-0AI3KwMQ863LOtkP .labelText>tspan{fill:black;stroke:none;}#mermaid-svg-0AI3KwMQ863LOtkP .loopText,#mermaid-svg-0AI3KwMQ863LOtkP .loopText>tspan{fill:black;stroke:none;}#mermaid-svg-0AI3KwMQ863LOtkP .loopLine{stroke-width:2px;stroke-dasharray:2,2;stroke:hsl(259.6261682243, 59.7765363128%, 87.9019607843%);fill:hsl(259.6261682243, 59.7765363128%, 87.9019607843%);}#mermaid-svg-0AI3KwMQ863LOtkP .note{stroke:#aaaa33;fill:#fff5ad;}#mermaid-svg-0AI3KwMQ863LOtkP .noteText,#mermaid-svg-0AI3KwMQ863LOtkP .noteText>tspan{fill:black;stroke:none;}#mermaid-svg-0AI3KwMQ863LOtkP .activation0{fill:#f4f4f4;stroke:#666;}#mermaid-svg-0AI3KwMQ863LOtkP .activation1{fill:#f4f4f4;stroke:#666;}#mermaid-svg-0AI3KwMQ863LOtkP .activation2{fill:#f4f4f4;stroke:#666;}#mermaid-svg-0AI3KwMQ863LOtkP .actorPopupMenu{position:absolute;}#mermaid-svg-0AI3KwMQ863LOtkP .actorPopupMenuPanel{position:absolute;fill:#ECECFF;box-shadow:0px 8px 16px 0px rgba(0,0,0,0.2);filter:drop-shadow(3px 5px 2px rgb(0 0 0 / 0.4));}#mermaid-svg-0AI3KwMQ863LOtkP .actor-man line{stroke:hsl(259.6261682243, 59.7765363128%, 87.9019607843%);fill:#ECECFF;}#mermaid-svg-0AI3KwMQ863LOtkP .actor-man circle,#mermaid-svg-0AI3KwMQ863LOtkP line{stroke:hsl(259.6261682243, 59.7765363128%, 87.9019607843%);fill:#ECECFF;stroke-width:2px;}#mermaid-svg-0AI3KwMQ863LOtkP :root{--mermaid-font-family:"trebuchet ms",verdana,arial,sans-serif;} 用户 DeepSeek - R1 输入处理 知识库 输出处理 发送文本生成请求 转请求 返回处理后输入 查询相关知识 返回知识数据 进行文本生成 传递生成结果 返回格式化结果 用户 DeepSeek - R1 输入处理 知识库 输出处理
在整个文本生成的过程中,R1主要进行以下三个核心步骤:
需求理解与处理:精准捕捉用户输入的文本需求,并进行深入解析与处理,为后续操作奠定基础。
知识库检索:在庞大的知识库中迅速查找与处理结果高度匹配的知识数据,确保信息的准确性和相关性。
结果呈现:将检索到的知识数据以用户友好的格式返回,满足用户的信息需求。

R1在实际应用中,能够灵活应对多种场景,主要体现在以下几个方面:
1. 日常生活
智能生活助手:R1可以根据用户需求,量身定制旅行攻略,无论是景点推荐、交通指南还是住宿预订,都能轻松搞定。此外,它还能充当“翻译官”,帮助用户解读外文菜单,甚至可以化身“麻将大师”,教你玩转地方麻将规则,让生活更加丰富多彩。
人生决策参谋:R1能够深入分析用户提供的信息,在事业发展、学业规划等方面提供独到的见解和决策参考。例如,它可以根据用户的生辰八字,结合运势走向,提供个性化的建议。
创意灵感源泉:对于网络文学作者来说,R1是提升写作效率的得力助手,帮助他们快速生成高质量的内容。更有趣的是,一些用户还开发出了“AI对联生成”等创新玩法,让R1在创意领域大放异彩。
2. 工作场景
科创情报分析:智慧芽接入DeepSeek-R1后,能够帮助用户更精准、快速地获取专利、论文等多维度的科创信息,从而深入把握技术演进的脉络和竞争格局,优化知识产权布局,提升企业的创新竞争力。
医疗辅助:智云健康将DeepSeek-R1接入其医疗AI系统“智云大脑”,显著提升了医院和药店SaaS的慢病管理效率,助力医疗机构更好地服务患者。
金融分析:R1可以用于分析股市走势等金融数据,为投资者提供有价值的参考信息,辅助他们做出更明智的投资决策。
3. 学习助手
数学解题:R1能够轻松解决高中及以上难度的数学问题,并详细展示逐步解题的过程,帮助用户深入理解数学原理,提升解题能力。
编程辅助:R1可以胜任代码生成、代码纠错等编程相关任务,例如,根据用户需求编写Python脚本,提高编程效率。
语言学习:R1提供语言翻译、语法讲解、语言表达润色等功能,全方位辅助用户学习各种语言,让语言学习变得更加轻松有趣。
4. 通用功能
信息检索与整合:R1具备类似ChatGPT的网络搜索功能,能够快速检索并整合互联网上的海量信息,为用户提供全面、准确的答案,满足用户的信息需求。
文本处理与分析:R1可以对输入的文本进行深入的理解、分析、总结和生成等操作,例如,它可以提取和分析PDF文件中的内容,帮助用户高效获取关键信息。








