
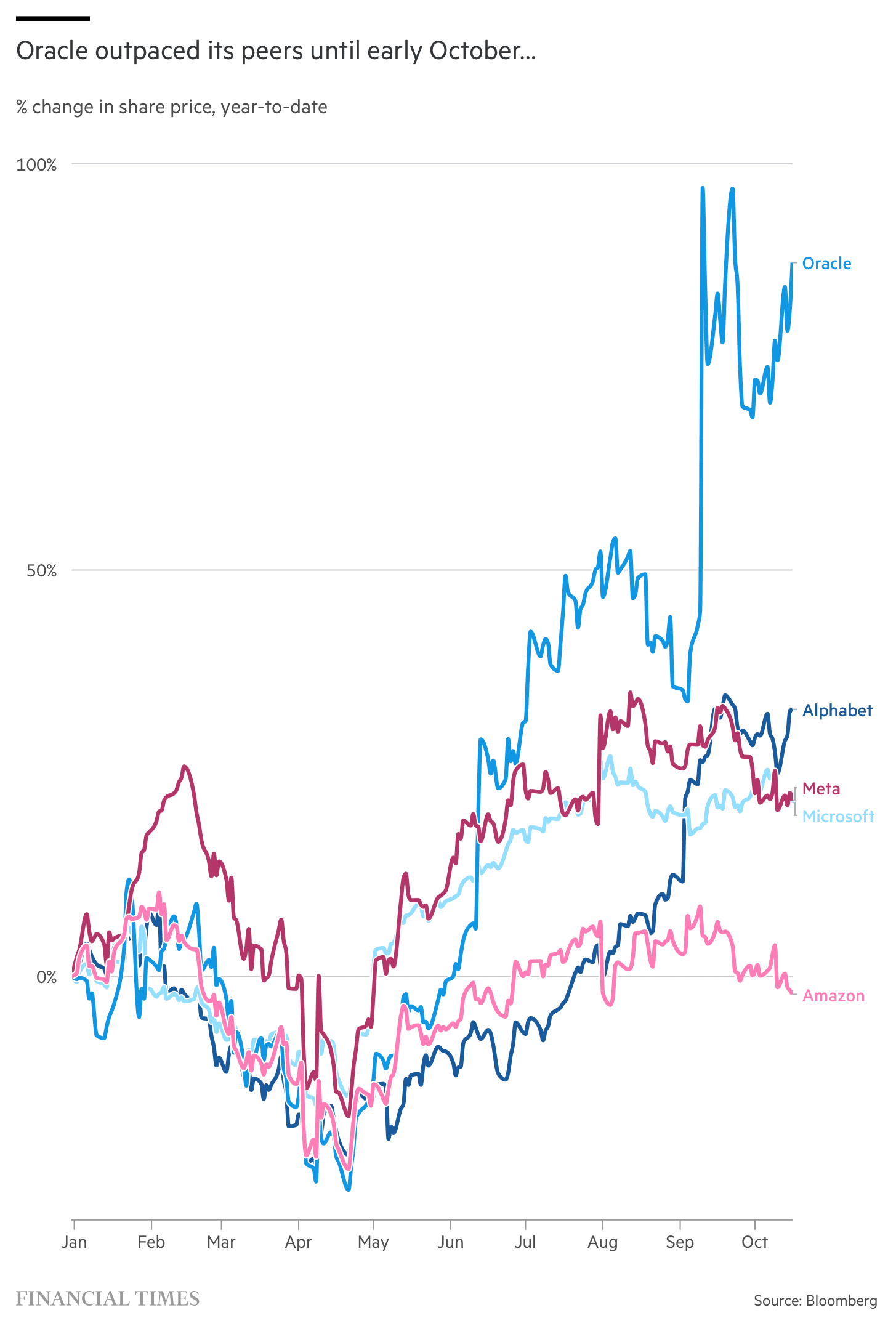
在近期科技股的集体抛售潮中,Oracle成为了最受冲击的科技巨头之一。其股价在过去一个月内下跌25%,几乎是同期表现最差的大型科技公司Meta的两倍。这一现象引发市场对Oracle激进AI投资策略的广泛质疑,投资者开始重新评估这家由Larry Ellison创立的软件巨头的商业决策。
巨额投资引发市场担忧
Oracle近期为转型人工智能领域,宣布将投入数千亿美元用于芯片和数据中心建设,主要通过与OpenAI合作提供计算能力。这种大规模、快速的投资策略在当前市场环境下引发了投资者的不安。
"这是一个与投资者在云服务领域所珍视的商业模式完全不同的模式,"Rothschild & Co Redburn的Alex Haissl表示。"从收入数字来看,这些交易看起来很棒,但它们非常资本密集,因此创造的价值很少。"
Oracle的债务规模也在急剧扩大。根据彭博数据,该公司的长期债务已从一年前的750亿美元增至约960亿美元。摩根士丹利预测,到2028年这一数字将飙升至约2900亿美元。仅在9月份,Oracle就发行了180亿美元债券,并正通过多家美国银行洽谈筹集380亿美元债务融资。
与同行的财务对比
在五大超大规模科技公司(包括亚马逊、谷歌、微软和Meta)中,Oracle是唯一一家自由现金流为负的公司。根据摩根大通的数据,其债务权益比已飙升至500%,远高于亚马逊的50%和微软的30%。
摩根大通分析师指出,"Oracle激进的AI建设雄心与其投资级资产负债表的限制之间存在紧张关系。"
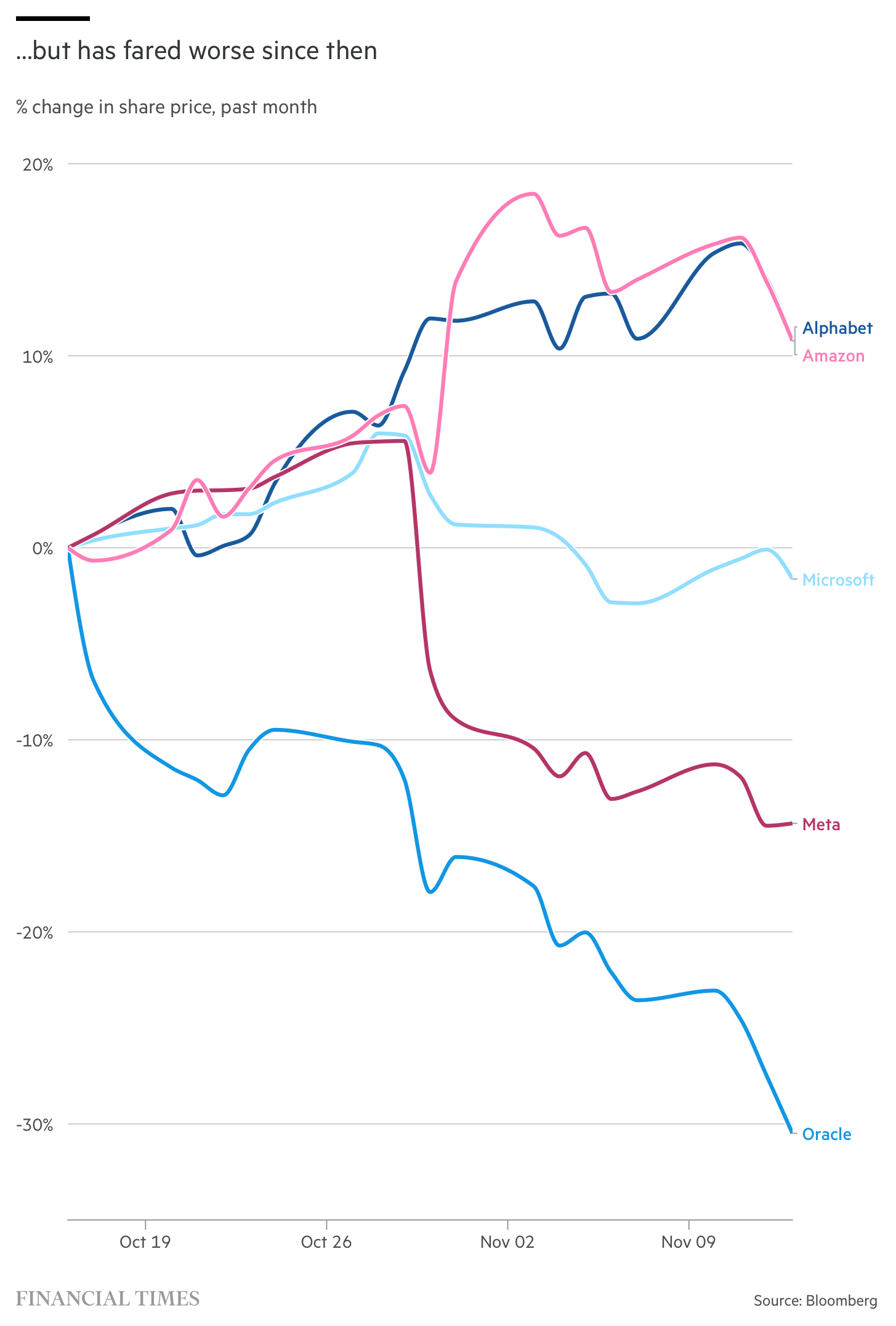
尽管所有五家公司在近年的支出激增中,现金与资产比率都显著下降,但Oracle的比率是最低的。此外,Oracle的数据中心租期比其向OpenAI出售计算能力的合同要长得多。
Oracle已签署至少五份长期数据中心租约,这些数据中心最终将由OpenAI使用,导致1000亿美元的资产负债表外租赁承诺。这些项目处于不同的建设阶段,有些预计要到明年才会动工。
市场对AI投资的集体反思
Oracle的股价下跌反映了市场对科技巨头在AI领域巨额支出的集体担忧。投资者担心,如果像OpenAI和Anthropic等少数几家亏损的AI初创公司未能兑现其技术承诺,大型科技集团的巨额估值和资本支出可能会适得其反。
标普全球警告称,到2028年,Oracle的三分之一收入将绑定于单一客户,即其对OpenAI的依赖。标普全球董事Andrew Chang表示:"这对Oracle来说是一个巨大的负债和信用风险。您的主要客户,迄今为止最大的客户,是一家风险投资支持的初创公司。"
公司高管的回应与市场反应
尽管面临市场质疑,Oracle高管坚称,由于AI需求远超现有计算能力供应,其回报将证明风险是值得的。公司表示,其与OpenAI的交易将在2027年至2032年间产生3000亿美元的收入。
根据S&P Visible Alpha汇编的估计,Oracle的基础设施业务预计到2029年将使收入增长超过10倍。此外,华尔街大多数分析师对其股票持乐观态度。
然而,市场似乎正在对这种无限烧钱投入AI的策略失去耐心。一位长期跟踪Oracle股票但对其没有做空头寸的卖空者表示:"Ellison在支出方面现在已经完全脱离常规,市场显然不再对公司在AI上无休止地烧钱感兴趣。"
领导层变动与战略调整
从2019年到9月卸任,Safra Catz是Oracle唯一的首席执行官,她因所需的大量费用而抵制扩大云业务。作为Oracle转向以AI为重点的新时代的一部分,她被联合首席执行官Clay Magouyrk和Mike Sicilia取代。
根据美国监管文件,Catz现在是Oracle董事会执行副主席,今年已行使股票期权并出售了25亿美元的股票。她曾宣布计划在2024年底行使股票期权。
行业分析师的观点
本周,巴克莱分析师将其对Oracle债券的评级从中性下调至低配,警告称其在AI基础设施上的大额支出已超过其自由现金流。
信用评级机构穆迪也指出了Oracle依赖少数几家AI公司带来的重大风险。此外,OpenAI面临着如何在未来八年实现承诺的1.4万亿美元AI基础设施支出的疑问问题,该公司已与几家大型科技集团达成交易,包括Oracle的竞争对手。
未来展望
Oracle的案例反映了科技行业在AI转型过程中面临的共同挑战:如何在追求技术创新的同时保持财务稳健。随着市场对AI投资的热情逐渐降温,科技巨头们可能需要重新平衡其战略,在创新与财务可持续性之间找到更好的平衡点。
对于Oracle而言,其AI豪赌的成败将在未来几年逐渐显现。如果OpenAI等合作伙伴能够成功兑现其技术承诺,Oracle的激进战略可能会获得丰厚回报。然而,如果AI商业化进程不及预期,Oracle可能面临更大的财务压力和市场质疑。










