
在当今快速发展的科技环境中,人工智能(AI)正以前所未有的速度重塑各行各业,电信行业也不例外。2024年6月,在TM Forum的DTW活动期间,Blue Planet(Ciena的一个部门)对其Agentic AI框架的展示,标志着电信网络运营即将迎来一场深刻的智能化变革。这一创新框架不仅解决了当前市场面临的单点式AI方案问题,更为电信运营商提供了一条通往统一、高效网络运营的清晰路径。
Agentic AI:电信行业的新机遇与挑战
Omdia业务负责人James Crawshaw指出,在Agentic AI炒作盛行的这一年里,电信运营商正面临来自网络供应商和OSS(运营支撑系统)供应商提供的单点式Agentic AI解决方案的冲击。这种碎片化的市场现状可能导致运营商陷入重复建设的风险,同时错失采用更统一整合方法的机会。
当前市场上的AI解决方案呈现出两极分化的态势:一方面,许多传统供应商的产品"将AI策略生硬地附加在传统OSS之上",缺乏真正的智能化和自主性;另一方面,来自公有云提供商的通用AI平台虽然功能强大,但往往无法理解电信网络特有的运营复杂性和业务需求。
Blue Planet敏锐地捕捉到了这一市场痛点,提出了一个专为电信网络构建的Agentic AI框架。这一框架支持智能体基于意图行动、应用上下文,并在整个网络范围内采取协调行动,其关键在于构建在清晰且组织良好的数据模型和API之上。
Blue Planet Agentic AI框架的核心优势
Blue Planet的Agentic AI框架并非简单地叠加AI技术,而是从电信网络的实际需求出发,构建了一套完整的智能化解决方案。该框架的核心优势主要体现在以下几个方面:
1. 专为电信网络设计的智能体架构
与通用AI平台不同,Blue Planet的框架专为电信网络环境构建,其智能体能够深度理解电信网络的特殊需求和复杂性。这些智能体不仅能够基于预设意图行动,还能在网络范围内进行协调,确保整体网络运营的一致性和高效性。
2. 基于数据模型和API的坚实基础
框架构建在清晰且组织良好的数据模型和API之上,这为智能体提供了可靠的工作基础。这种设计确保了AI系统能够准确理解网络状态、服务需求及运营目标,从而做出正确的决策和行动。
3. 与现有OSS系统的无缝集成
尽管AI Studio主要旨在与Blue Planet的OSS应用产品组合协同工作,但部分客户已将其视为一个通用的OSS Agentic框架。这种灵活性使得运营商能够在不彻底重构现有系统的情况下,逐步引入AI能力,降低转型风险和成本。
4. 丰富的领域知识积累
AI Studio本身已包含大量关于电信网络的领域知识,这为运营商构建自有OSS AI平台节省了大量时间和资源。通过利用这些预先积累的知识,运营商可以更快地实现AI能力的落地和应用。
AI Studio:构建Agentic AI的强大平台
Blue Planet的AI Studio是其Agentic AI框架的核心组成部分,为电信运营商提供了一套完整的AI开发和部署环境。这一平台于2024年商用发布,旨在简化AI解决方案的开发、部署和管理过程。
AI Studio的核心功能
AI Studio为Blue Planet及第三方AI模型提供全方位的支持,包括:
- 模型管理:导入、部署、更新和停用AI模型,配置模型属性
- 执行控制:实例化、启动、停止和调度模型执行
- 性能监控:实时监控模型性能,确保AI系统的稳定运行
- 代码管理:查看、编辑、版本化、回滚和调试模型代码
- API集成:调用Blue Planet及外部API,实现与系统各部分的交互
AI Studio还提供详细的仪表板,用于配置和管理AI应用,集中呈现所有AI活动。这一平台经过专门设计,以满足数据科学家、开发人员和系统管理员的需求,并为每个角色提供相应的工具和功能。
技术架构与集成
AI Studio集成了行业领先的开源框架和技术,以简化采用和集成过程。主要的技术组件包括:
- Apache Airflow:用于数据工程流水线的开源工作流管理平台
- LangChain:帮助开发者构建强大的应用程序,将大语言模型(LLM)与外部工具、API、数据源和用户工作流集成
- MLflow:用于构建AI应用程序和模型的开源开发者平台
- Redis:开源的内存键值数据库,用作分布式缓存和消息代理
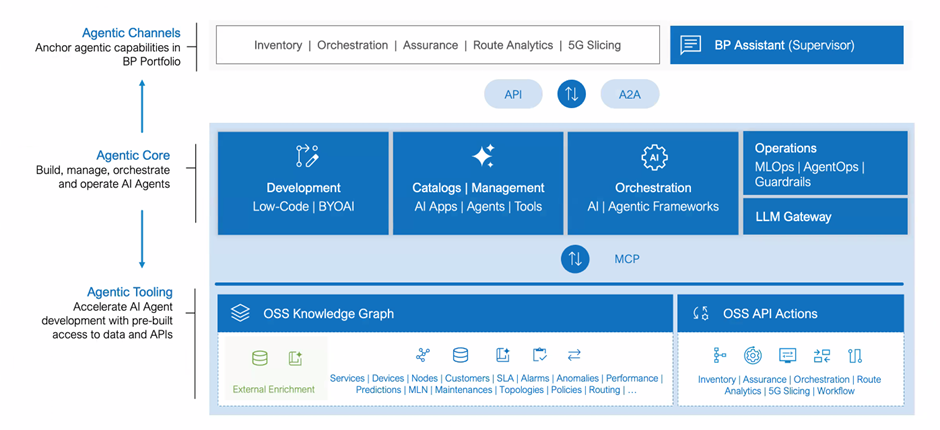 图:Blue Planet AI Studio向Agentic AI框架的技术演进
图:Blue Planet AI Studio向Agentic AI框架的技术演进
从AI Studio到Agentic框架的演进
Blue Planet的AI Studio正在不断演进,朝着更完整的Agentic AI框架方向发展。这一演进过程通过API与Blue Planet的OSS应用产品组合交互,并可通过智能体间(A2A)协议与第三方智能体进行交互。
Agentic框架的核心组件
完整的Agentic AI框架包含以下核心组件:
- 智能体开发环境:提供构建智能体的工具和平台
- "自带AI"许可模式:允许授权用户导入、部署、配置和管理第三方AI/ML模型
- 智能体目录:维护可用的智能体库,通过编排引擎调用多个智能体实现复杂任务
- 网关:允许用户集成其偏好选用的大语言模型
- 模型上下文协议(MCP):实现Agentic核心与工具的通信
未来发展方向
从2026年起,通信服务提供商(CSP)将能够使用Agentic框架的开发环境构建自己的AI智能体。这一开放性将大大促进电信行业的创新,使运营商能够根据自身特定需求定制AI解决方案。
Agentic框架还支持与符合MCP标准的外部服务进行互操作,进一步扩展了其应用范围和灵活性。这种开放性设计确保了框架能够不断适应电信行业的发展需求,保持长期竞争力。
实际应用场景与价值
Blue Planet已开始与现有客户测试其Agentic AI框架,并在多个实际应用场景中展现出显著价值。这些用例包括:
1. 网络切片自动化
5G网络切片是电信行业的关键技术之一,但手动配置和管理网络切片复杂且耗时。通过Agentic AI框架,运营商可以实现网络切片的自动化配置、优化和保障,大幅提高网络资源利用效率和服务质量。
2. 网络设备建模
在复杂的电信网络中,准确建模和管理网络设备是一项挑战。Agentic AI框架能够自动识别、分类和建模网络设备,保持网络模型的准确性和实时性,为网络规划和优化提供可靠依据。
3. 意图理解与执行
传统的网络管理系统通常需要精确的指令才能执行操作。而基于Agentic AI的系统能够理解自然语言或高级业务意图,自动转化为具体的网络操作,大大简化了网络管理流程。
4. 模板生成
网络服务模板是快速部署新服务的关键。Agentic AI框架能够根据历史数据和最佳实践,自动生成优化的网络服务模板,加速新服务的上线时间。
5. 服务保障
通过持续监控网络状态和服务质量,Agentic AI框架能够主动识别潜在问题,自动采取措施进行预防或修复,提高服务可靠性和客户满意度。
行业影响与未来展望
Blue Planet的Agentic AI框架代表了电信行业智能化转型的重要一步,其影响将深远而广泛。
对电信运营商的价值
对于电信运营商而言,这一框架提供了构建统一AI平台的理想基础,避免了单点式AI解决方案带来的碎片化问题。通过整合现有OSS系统,运营商能够以更低的成本实现网络运营的智能化,提高运营效率和服务质量。
对供应商生态的影响
这一框架的出现也将重塑电信供应商生态。那些能够提供真正整合、开放AI解决方案的供应商将获得竞争优势,而仅提供简单AI附加功能的供应商可能面临市场淘汰。
行业标准化进程
随着Agentic AI框架的普及,电信行业的AI标准化进程将加速。模型上下文协议(MCP)等开放标准的推广,将促进不同系统间的互操作性,降低整体行业的技术壁垒。
未来发展方向
展望未来,Agentic AI框架将在以下方向继续发展:
- 更强的自主性:智能体将具备更高的自主决策能力,减少人工干预
- 更广泛的集成:与更多第三方系统和API集成,形成完整的AI生态系统
- 更深入的领域知识:针对特定垂直行业的定制化解决方案
- 更高效的资源利用:通过AI优化网络资源分配,降低运营成本
结论
Blue Planet的Agentic AI框架代表了电信网络运营的未来方向。通过专为电信网络设计的智能体架构、基于数据模型和API的坚实基础,以及与现有OSS系统的无缝集成,这一框架为运营商提供了一条通往网络智能化的清晰路径。
随着AI Studio向完整Agentic框架的演进,电信行业将迎来一场深刻的智能化变革。这一变革不仅将提高网络运营效率和服务质量,还将催生新的商业模式和服务机会,为电信行业的可持续发展注入新的活力。
在Agentic AI时代,那些能够率先拥抱这一技术趋势,构建统一、开放AI平台的运营商,将在激烈的市场竞争中占据先机,引领电信行业进入智能化运营的新纪元。








