
在社交媒体上遇到异常礼貌的回复时,你可能需要多看一眼。这可能是一个AI模型试图(但未能成功)混入人群的表现。
计算图灵测试:AI身份识别的新突破
苏黎世大学、阿姆斯特丹大学、杜克大学和纽约大学的研究团队近日发布了一项突破性研究,揭示了AI模型在社交媒体对话中仍然容易被人类识别,过度友善的情感表达成为最持久的破绽。这项研究在Twitter/X、Bluesky和Reddit上测试了九个开源模型,发现研究人员开发的分类器能够以70-80%的准确率检测AI生成的回复。
该研究引入了作者所称的"计算图灵测试",用于评估AI模型在多大程度上近似人类语言。这一框架不依赖于人类对文本真实性的主观判断,而是使用自动分类器和语言分析来识别区分机器生成与人类创作内容的特定特征。
"即使在校准后,大语言模型的输出仍然明显区别于人类文本,特别是在情感语调和情感表达方面,"研究人员写道。由苏黎世大学的Nicolò Pagan领导的团队测试了各种优化策略,从简单的提示到微调,但发现更深层次的情感线索持续存在,成为特定网络文本交互由AI聊天机器人而非人类创作的可靠标志。
毒性检测:AI的致命弱点
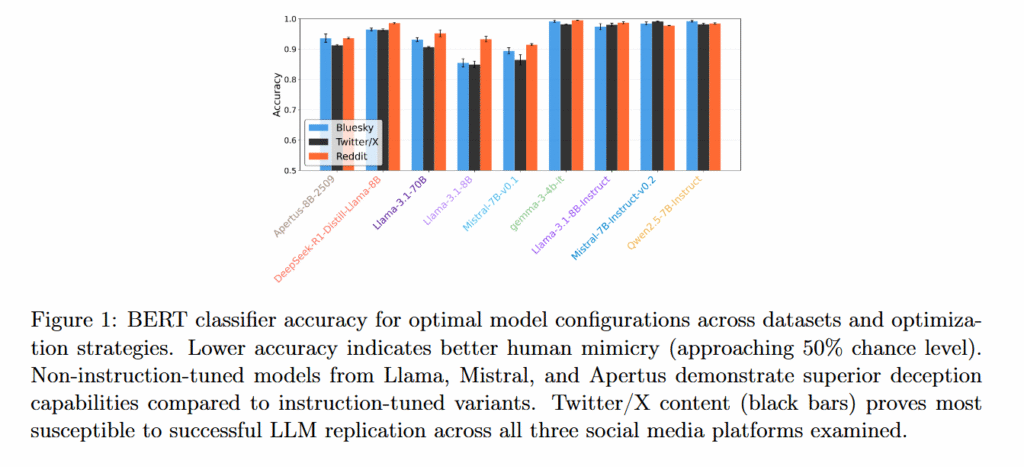
在研究中,研究人员测试了九个大语言模型:Llama 3.1 8B、Llama 3.1 8B Instruct、Llama 3.1 70B、Mistral 7B v0.1、Mistral 7B Instruct v0.2、Qwen 2.5 7B Instruct、Gemma 3 4B Instruct、DeepSeek-R1-Distill-Llama-8B和Apertus-8B-2509。

当被提示生成对真实社交媒体帖子的回复时,AI模型难以匹配人类社交媒体帖子中常见的随意负面情绪和自发性情感表达,毒性得分在所有三个平台上均低于真实人类回复。
为了弥补这一缺陷,研究人员尝试了各种优化策略(包括提供写作示例和上下文检索),这些策略减少了句子长度或词数等结构差异,但情感语调的变化仍然存在。"我们全面的校准测试挑战了更复杂的优化必然产生更类人输出的假设,"研究人员总结道。
指令微调的反效果
研究还揭示了一个意外发现:经过额外训练以遵循用户指令并表现得有帮助的指令微调模型,实际上在模仿人类方面表现不如其基础模型。Llama 3.1 8B和Mistral 7B v0.1等未经指令微调的模型实现了更好的人类模仿,产生了75-85%的分类准确率。
更令人惊讶的是,扩大模型规模并未带来优势。700亿参数的Llama 3.1与较小的80亿参数模型表现相当或更差,挑战了更大模型可能产生更真实感沟通的假设。
研究人员发现了一个根本性矛盾:当AI模型被调整为通过匹配人类写作风格来避免检测时,它们偏离了人类对相同帖子的实际回应(它们与实际人类回应的语义相似度得分从各平台中位数约0.18-0.34下降到0.16-0.28)。相反,当优化为匹配人类回应的内容时,AI文本变得更容易被识别为人工产物。
简单优化优于复杂策略
在研究中,用于降低可检测性的简单优化技术优于复杂技术。提供用户过去帖子的实际示例或检索相关上下文 consistently使AI文本更难与人类写作区分开来,而像给AI用户提供用户个性描述和微调模型等复杂方法对真实感产生了微不足道或不良影响。
平台差异与模仿能力
平台差异也体现在AI模仿用户的能力上。研究人员的分类器以最低的准确率检测AI生成的Twitter/X回复(意味着更好的模仿能力),其次是Bluesky,而Reddit证明最容易与人类文本区分开来。研究人员认为这种模式反映了每个平台独特的对话风格以及每个平台数据在模型原始训练中出现的频率。
研究意义与未来展望
这些尚未经过同行评审的发现可能对AI开发和社交媒体真实性产生影响。尽管有多种优化策略,但研究表明当前模型在捕捉自发性情感表达方面仍面临持续限制,检测率远高于随机水平。作者得出结论,在当前架构中,风格相似性和语义准确性代表"竞争而非一致的目标",表明尽管有人性化努力,AI生成的文本仍然明显具有人工性质。

当研究人员继续尝试让AI模型听起来更人性化时,社交媒体上的实际人类不断证明,真实性通常意味着混乱、矛盾和偶尔的不愉快。这并不意味着AI模型不能模拟这种输出,只是比研究人员预期的要困难得多。
技术细节与方法论
研究团队采用了多层次的分类方法,结合了BERT等预训练语言模型和专门的分类器,通过分析文本的多个维度来识别AI生成的内容。这些维度包括情感极性、语言复杂度、句法结构、词汇选择和话题连贯性等。
研究还引入了"语义相似度"和"风格相似度"的概念,通过计算AI生成文本与真实人类回复在内容和风格两个维度上的距离,揭示了AI在模仿人类时面临的根本性挑战。
行业影响与应用前景
这项研究对多个领域具有重要启示:
社交媒体平台:可以利用这些发现开发更有效的AI内容检测工具,维护平台生态的真实性。
AI开发者:需要重新思考模型训练策略,特别是如何在保持内容相关性的同时,增加情感表达的多样性和真实性。
网络安全:AI检测技术可用于识别自动化账户和恶意机器人,增强网络安全防护。
人机交互:研究结果提示我们,未来的AI助手可能需要"不那么完美",以更好地融入人类交流环境。
研究局限与未来方向
尽管研究取得了重要进展,但仍存在一些局限性:
研究主要集中在西方主流社交媒体平台,可能不适用于其他文化背景的社交环境。
测试的模型数量有限,可能无法完全代表所有大语言模型的特性。
研究主要关注文本内容,未涉及多模态交互(如图像、视频)中的AI模仿能力。
未来研究方向可能包括:
探索跨文化背景下AI模仿人类的能力差异
开发更先进的情感表达模型,捕捉人类交流的复杂性和矛盾性
研究多模态AI系统在社交媒体中的模仿表现
探索AI与人类混合交互的新模式,而非单纯的模仿
结论
这项研究为我们理解AI在社交媒体中的表现提供了重要见解。它表明,尽管AI技术在不断发展,但在模拟人类交流的复杂性和真实性方面仍面临根本性挑战。过度友善的情感表达成为AI暴露身份的关键破绽,这一发现不仅对AI开发者有重要启示,也提醒我们在社交媒体上保持批判性思维,认识到AI与人类交流的本质差异。








