

在新能源汽车行业竞争白热化的2025年,理想汽车交出了一份令人「五味杂陈」的季度成绩单。当大多数车企还在为销量和市场份额展开激烈角逐时,理想汽车的掌舵人李想却做出了一个出人意料的决定——承认过去三年的「职业经理人」管理实验失败,宣布全面回归「创业公司」模式。
这一决策的背后,是一场关乎企业未来的战略豪赌。在财务数据看似「不及格」的表象下,理想汽车正试图通过组织变革和AI技术布局,重塑自身在行业中的定位。这场豪赌的成败,不仅将决定理想汽车的未来走向,也可能为整个新能源汽车行业的发展方向提供新的思考。
财务困境:表象与真相
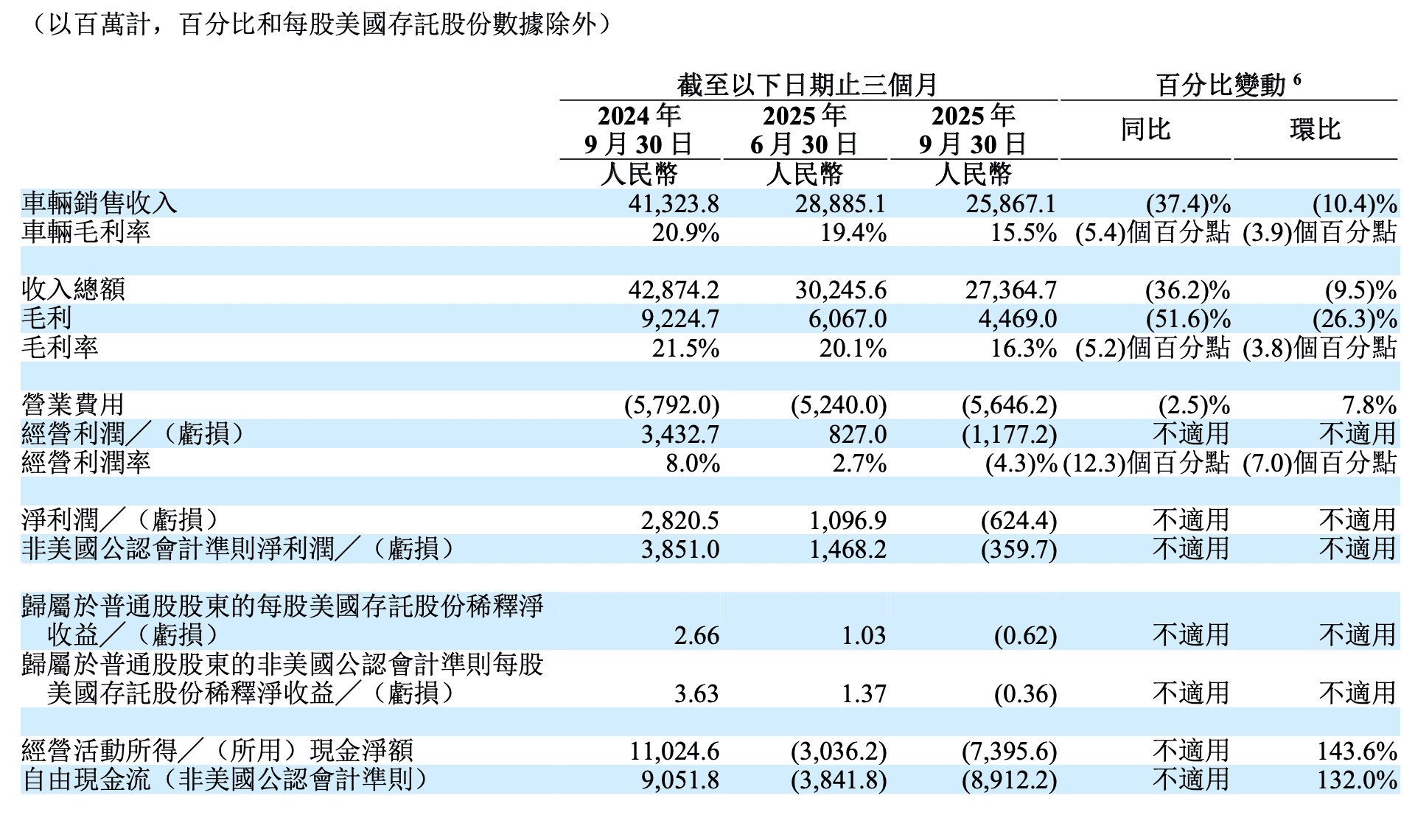
2025年第三季度,理想汽车的财务数据确实令人担忧:营收同比下滑36.2%,整车毛利率从去年同期的20.9%降至15.5%,净利润更是由去年同期的盈利28亿元转为亏损6.24亿元。更让资本市场紧张的是,曾经充沛的自由现金流也出现了89亿元的净流出。
销量下滑背后的产品切换阵痛
理想汽车的销量下滑并非偶然。数据显示,2025年Q3理想交付了9.3万辆汽车,同比下降39%,环比下降16.1%,勉强保住了此前给出的9-9.5万辆指引下限。这一表现与理想汽车在2023年和2024年分别跑出的181%和78.7%的惊人增速形成鲜明对比。
销量下滑的背后,是理想汽车正处于从「只靠增程」向「增程+纯电」转变的关键时期。曾经大杀四方的L系列车型,面对竞争对手的围剿和纯电续航技术的快速提升,市场统治力正在减弱。而新推出的纯电车型i8市场反响平平,本应走量的i6虽然订单表现不错,却受困于产能爬坡和供应链问题,未能及时转化为实际交付量。
毛利率下降的真相
车辆毛利率从20.9%降至15.5%,这一数据乍看确实令人担忧。然而,理想CFO李铁在财报电话会上揭示了背后的真相:Q3计提了约11亿元的MEGA召回预估成本。这笔费用源于10月底的一次大规模召回,涉及1.1万辆车,原因是冷却液问题可能引发电池风险。
这笔看似沉重的召回费用,实际上体现了理想汽车对品牌信誉的重视。MEGA作为理想冲击高端纯电市场的旗舰车型,虽然销量未达预期,但通过主动召回更换电池来保障用户权益,是在为品牌长远发展「填坑」。
更具启发性的是,如果剔除这笔一次性计提,理想的车辆毛利率实际上依然维持在19.8%的高位。在营收大幅下滑、纯电车型(通常毛利率较低)占比提升的情况下,能够守住接近20%的毛利率,充分证明了理想汽车那套强悍的成本控制体系仍然具有极强的韧性。
现金流管理的挑战
单季度89亿元的自由现金流净流出,确实值得警惕。尽管理想汽车账上仍拥有近千亿元(989亿元)的现金储备,看似「家底厚实」,但如此大规模的现金流出速度,无疑给公司的财务健康带来了挑战。
然而,从战略角度看,这种现金流状况可能与理想汽车当前的AI战略投入密切相关。在技术研发、芯片自研、组织变革等方面的大规模投入,短期内必然会对现金流产生压力。关键在于,这些投入能否在未来转化为可持续的竞争优势。
组织变革:从职业经理人到创业模式
在财报电话会上,李想关于「组织」的大段复盘和规划,或许比财务数据更值得关注。他直言不讳地承认,过去三年学习苹果、微软的「职业经理人」管理模式是一个错误。「我们努力学习,却变成了越来越差的自己。」这句话从一位千亿市值公司掌门人口中说出,分量极重。

职业经理人模式的局限性
李想对职业经理人模式的批判有着清晰的逻辑。他认为,职业经理人模式——强调流程、汇报和风险规避——适用于行业格局已定、技术迭代缓慢的成熟期。然而,当下的汽车行业正处于AI技术日新月异、淘汰赛如火如荼的「乱世」。
在这样一个快速变化的环境中,层层汇报的流程反而成为效率的毒药。「当一个决策需要经过三层PPT汇报才能落地时,市场机会早就没了。」李想敏锐地观察到,英伟达和特斯拉这两家全球最强的科技公司,依然保持着「创业公司」的管理模式,这绝非偶然。
创业模式回归的核心转变
从2025年Q4开始,理想汽车将全面回归创业模式。这一转变并非简单的口号,而是管理颗粒度的剧变,主要体现在三个方面:
从「汇报」到「对话」:减少PPT,增加面对面的深度碰撞。在快速变化的市场环境中,直接、高效的沟通比层层汇报更为重要。
从「资源占有」到「效率提升」:去年花10块钱做的事,今年必须花8块钱,省下来的2块钱去投未来。这种资源约束将迫使团队更加专注于效率和创新。
从「避责」到「解决关键问题」:职业经理人倾向于制造信息不对称来保护自己,而创业者必须直面血淋淋的问题,这种文化转变将激发团队的战斗力。
「否定之否定」的战略意义
在我看来,李想的这次组织变革实际上是一次「否定之否定」。他试图亲手剥离掉大公司滋生的「赘肉」,让这个拥有数万名员工的庞然大物,重新找回2019年那种「向死而生」的战斗力。
这场变革注定是痛苦的,但对于当下的理想汽车来说,想要在AI时代的牌桌上活下去,这或许是必要的「手术」。正如管理学大师彼得·德鲁克所言:「动荡时代最大的危险不是动荡本身,而是仍然用过去的逻辑做事。」
AI战略:从移动沙发到具身智能
在财报电话会上,李想几乎用了一半的时间在阐述「AI」、「具身智能」和「端到端」的战略构想。这表明,尽管面临财务压力,理想汽车对AI技术的投入和布局不仅没有减弱,反而更加坚定。

跳出同质化竞争的困局
李想敏锐地意识到,目前的电动车竞争已经陷入了「红海」:续航多20公里、屏幕大2寸、价格便宜5000块……这种同质化竞争没有尽头。他试图跳出这个维度,将汽车重新定义为「具身智能机器人」——不再是被动等待指令的机器,而是具备感知、思考、执行能力的「主动智能体」。
这一战略定位的转变,意味着理想汽车将不再满足于成为「移动的沙发」,而是要打造「移动的机器人」。这种定位上的升维,或许能够帮助理想汽车在激烈的市场竞争中找到差异化优势。
技术底牌:自研芯片与算法革新
为实现「具身智能」的愿景,理想汽车亮出了藏在桌下的底牌:
感知层面:抛弃现有的BEV(鸟瞰图)技术,转向3D ViT(视觉Transformer)。这一技术路线能够提供更精确的环境感知能力,为高级别自动驾驶奠定基础。
算力方面:理想自研M100芯片。CTO谢炎透露,这款专为具身智能设计的芯片,配合自研OS,性价比是目前高端芯片的3倍。预计2026年上车。
通过软硬件全栈自研,理想汽车希望实现真正的端到端智能。这也是特斯拉正在走的路径,理想汽车正在从「也是特斯拉的学徒」变成「最像特斯拉的对手」。
AI生态的拓展野心
更有意思的是,李想的AI野心似乎不止于汽车本身。他在社交平台上透露将发布「理想AI眼镜」,并称其为「理想最好的人工智能附件」,甚至连AI音箱也在考虑范围内。
这些举措表明,李想希望理想的AI能力能够渗透到用户生活的每一个角落,而不仅仅局限于驾驶舱。这种「汽车+AI生态」的布局,可能为理想汽车带来全新的商业模式和增长点。
战略豪赌:短期阵痛与长期价值
综合来看,理想汽车当前的处境可以概括为「短期阵痛,长期布局」。从财务数据看,Q3的业绩报告确实是一份「不及格」的答卷:营收下滑、利润亏损、自由现金流流出……但从企业经营的底层逻辑看,却可以看到一种难得的「清醒」。
在大多数车企还在为「多卖几辆车」而疯狂打价格战、堆配置的时候,李想选择了在财务最困难的时候,做最难的事情:重塑组织、自研芯片、押注具身智能。
战略定力的价值
在商业史上,许多伟大的企业都是在行业低谷期进行战略布局,从而在下一轮增长周期中占据先机。正如亚马逊创始人贝索斯所言:「当你把所有资源都投入到短期业绩时,你实际上是在赌未来不会改变。而当未来真的改变时,你就输了。」
李想显然深谙此道。尽管面临短期业绩压力,但他依然坚持在AI和组织变革上投入资源,这种战略定力在当今急功近利的商业环境中尤为难得。
风险与挑战并存
当然,理想汽车的AI战略也面临着诸多挑战:
技术不确定性:AI技术发展日新月异,今天的领先技术可能明天就被颠覆。理想汽车能否持续保持技术领先地位,存在很大不确定性。
组织变革阻力:从职业经理人模式向创业模式转变,将面临巨大的组织惯性和文化阻力。这种变革能否真正落地,还有待观察。
财务可持续性:在AI研发和组织变革上的大规模投入,短期内将继续对现金流产生压力。如何在投入与回报之间找到平衡,是一个难题。
行业启示意义
无论理想汽车的AI战略最终成败如何,其探索过程都为整个新能源汽车行业提供了有价值的启示:
AI将成为汽车行业的新赛道:在电动化同质化严重的背景下,AI和智能化可能成为下一个差异化竞争的关键领域。
组织能力决定技术落地:先进的技术需要与之匹配的组织能力才能发挥最大价值。理想汽车的「创业模式」回归,或许正是为了解决这一匹配问题。
长期主义的价值:在行业低谷期坚持战略投入,可能为企业在下一轮增长周期中赢得先机。这种长期主义思维值得行业借鉴。
结语:向死而生的勇气
李想在赌,赌AI时代汽车的终局不是「移动的沙发」,而是「移动的机器人」;他在赌,只有回归创业公司的敏捷,才能在巨头环伺的下半场活下来。这场豪赌的结局尚未可知,但至少,他没有选择在温水中慢慢沉没。
在商业史上,每一次重大技术变革都会催生新的行业格局。AI技术正在重塑各行各业,汽车行业也不例外。理想汽车的转型阵痛,或许正是这一变革浪潮中的必然过程。正如管理学大师汤姆·彼得斯所言:「不创新,就灭亡。」
对于理想汽车而言,当前的困境既是挑战,也是机遇。能否通过组织变革和AI战略突破重围,不仅关系到企业自身的命运,也可能为整个新能源汽车行业的发展方向提供新的思路。无论结果如何,这种「向死而生」的勇气,都值得行业尊重。








