
在AI技术飞速发展的今天,多模态生成领域正经历着前所未有的变革。从Sora 2.0与奥特曼对话的音画同步视频生成,到Nano Banana Pro的风格化生图热潮,AI生成技术不断刷新着我们的认知边界。而在这一波技术浪潮中,阿里的千问APP在12月初悄然完成了一次关键版本更新,接入了国内最强AI生视频模型Wan 2.5以及全球开源领先AI生图模型的特供满血版Qwen-Image 2511。更令人惊喜的是,生图功能直接拉满免费不限次,彻底降低了用户的使用门槛。
本文将通过一周时间的深度实测,从视频能力、生图效果以及国产AI的实用主义突围三个维度,全面解析千问APP这两项新功能的实际表现,探讨国产AI如何从实验室走向日常生活,以及免费模式背后阿里构建的AI生态闭环。
视频能力实测:Wan 2.5背后的国产模型实用主义路线
Wan 2.5作为为数不多能够对标谷歌Veo3的视频生成大模型,其核心突破在于音画同步、10秒长视频生成以及更精细、好看的画面。简单来说,Wan 2.5不仅是2025年国内最先进的多模态生成模型之一,也是最具性价比的一梯队AI视频生成产品。
音画同步与时长测试
音画不同步、短时长限制、细节不突出,是过去国产视频模型与国际模型的主要差距。针对这些问题,我们设计了一个复杂场景测试:让Wan 2.5生成两个不同风格人物对话的剧情。
测试提示词:
暮春午后,石质柱廊蜿蜒延伸,青灰色石板映着斑驳光影,阶前青草点缀,风拂过荀子身着玄色宽袍腰束素带,与身披浅灰亚麻袍、赤足踏石的苏格拉底相对而立。镜头先以全景定格,随即推进至荀子中近景,他广袖一扬,特写中眼神如炬,沉凝有力地掷出:「人性本恶!争则乱,乱则穷!」镜头横切至苏格拉底,中近景里他双手自然摊开,指尖轻叩石面,眉宇从容,温和却带锋芒地反驳:「人性本善,无人有意作恶。」最后镜头从两人面部拉远,回归全景,柱廊光影流转,风拂衣袂,两人对立的身影在古意场景中定格。
这段提示词埋下了三个挑战:风格冲突、音画同步和复杂画面元素保持。

测试结果显示,Wan 2.5的音画同步准确率相当出色。不仅人物挥动衣袖的动作、身体姿态与台词完美匹配,场景元素在镜头切换中也保持了高度一致性,整体画面调度达到了动画电影的水平。这种表现充分证明了国产AI在音画同步技术上已经取得了显著突破。
细节控制测试
如果说卡通测试是基础题,那电影级写实测试就是附加题。我们让Wan 2.5生成一个真实复杂场景中运动中的主角和动物。
测试提示词:
【风格设定】电影级写实风格,画面干净通透,兼具温柔氛围感与高级电影感;线条细腻,质感真实。【人物 + 动物+动作设定】 人物:20岁年轻白人女孩,轮廓分明,皮肤白皙,长发微卷,眼神清澈带一丝温柔沉思;穿着米白色棉麻长裙(领口微敞,袖口随意卷起),衣料有自然褶皱,质感轻薄透气。 动物:一只温顺的小鹿(毛色浅棕带白色斑点,鹿角短小圆润),头部轻靠女子左臂,眼神柔和,耳朵偶尔轻微晃动,与女子互动自然不僵硬。 动作:女孩牵着鹿从森林中缓缓走来 【场景设定】黄昏稀疏落叶林,树干笔直修长,树叶泛黄带绿(秋夏交替质感),地面覆盖少量浅棕色落叶;时间为日落前1小时,天色呈暖橙与淡紫渐变,空气通透无雾气。 【镜头与光影核心要求】 镜头参数:长镜头(无切换),中景构图(人物 + 小鹿占画面60%),中心构图(人物与小鹿位于画面正中心),干净单人 + 动物镜头(无多余路人 / 杂物);背景虚化(景深f/2.8),突出主体,虚化后背景呈斑驳圆形光斑。 光影层次:逆光、侧光、柔光的多层次光影效果
这次测试的结果令人惊喜。女孩的棉麻长裙袖口卷起处有自然褶皱,小鹿的头靠在女孩手臂上时耳朵会轻轻晃动,逆光的金色轮廓光精确勾勒在发丝和肩膀边缘。更令人惊讶的是,视频里甚至包含了女孩和小鹿踩过落叶时的脚步声,以及背景中清脆且有空间远近层进的鸟叫声。
这种画面审美突破的核心在于,Wan 2.5通过引入人类反馈的强化学习(RLHF),把用户对画面质感、动态效果、指令匹配度的反馈用于优化模型,从而彻底让AI视频生成摆脱了过去"诡异中带着点赛博丑陋"的标签。
场景化功能体验
不同于国际模型侧重各种技术极限,Wan 2.5更注重实用场景适配。我们进行了一个创意测试:上传一张小猫的照片,让它驮着孙悟空在非洲大草原狂奔。
这个测试的难点在于双重动态:小猫跑步时的肌肉形变、孙悟空的丝带飘动,还要保持小猫的原长相。许多AI处理图生视频+复杂动作时,容易把主体搞成橡皮泥,要么肌肉不动,要么脸崩了。

测试效果依然稳定,小猫已经驮着孙悟空在非洲大草原奔驰,肌肉运动自然,孙悟空的丝带飘向风的方向,最关键的是小猫的脸与上传的照片几乎一致——耳朵的弧度、眼睛的颜色,甚至额头的精细花纹都完整保留。
生图实测:免费工具的专业度上限有多高
原本测完视频能力后,我以为不会再有更多惊喜,但Qwen-Image 2511模型的表现同样令人印象深刻。官方资料显示,Qwen-Image 2511模型在Huggingface趋势榜登顶数周,开源生态贡献度全球第一,AI竞技场排名仅次于闭源模型Nano Banana与Seedream 4.0。
人物一致性测试
AI生图的核心痛点之一是无法在多轮生成中保持人物特征稳定性,经常是更换场景、调整动作后,人物面部特征易出现崩脸、换脸问题。这就导致AI出神图容易,但在生产环境中稳定出图反而成了难题。
我们以同一人物(动物)多场景生成为测试场景,来"嫁祸"一只小猫咪:
测试流程:
输入素材:一张金渐层小猫的照片 生成指令:给小猫穿上粉色裙子、给小猫面前放个花瓶小猫推花瓶、让花瓶碎在小猫面前
Qwen-Image 2511完整保留了金渐层的面部特征,穿上的衣服也与小猫身形完美符合。一个有趣的细节是,每次Qwen-Image 2511生图都是四张,而这四组图片中,小猫的裙子颜色、花的颜色与款式都是完全一一对应的,细节处理相当出色。
中文文字+商用场景适配
对中小商家而言,AI生图的核心价值在于降低商用素材制作成本。能否生成符合平台规范的商品图、海报图,直接决定工具的实用价值。此外,中文场景下,当前市面上的其他AI生图常出现文字乱码、字体错位问题。
我们设计了一个高难度测试:不仅要能写汉字,还要有排版,写得好看,并且搭配复杂商用级别画面。
测试提示词:
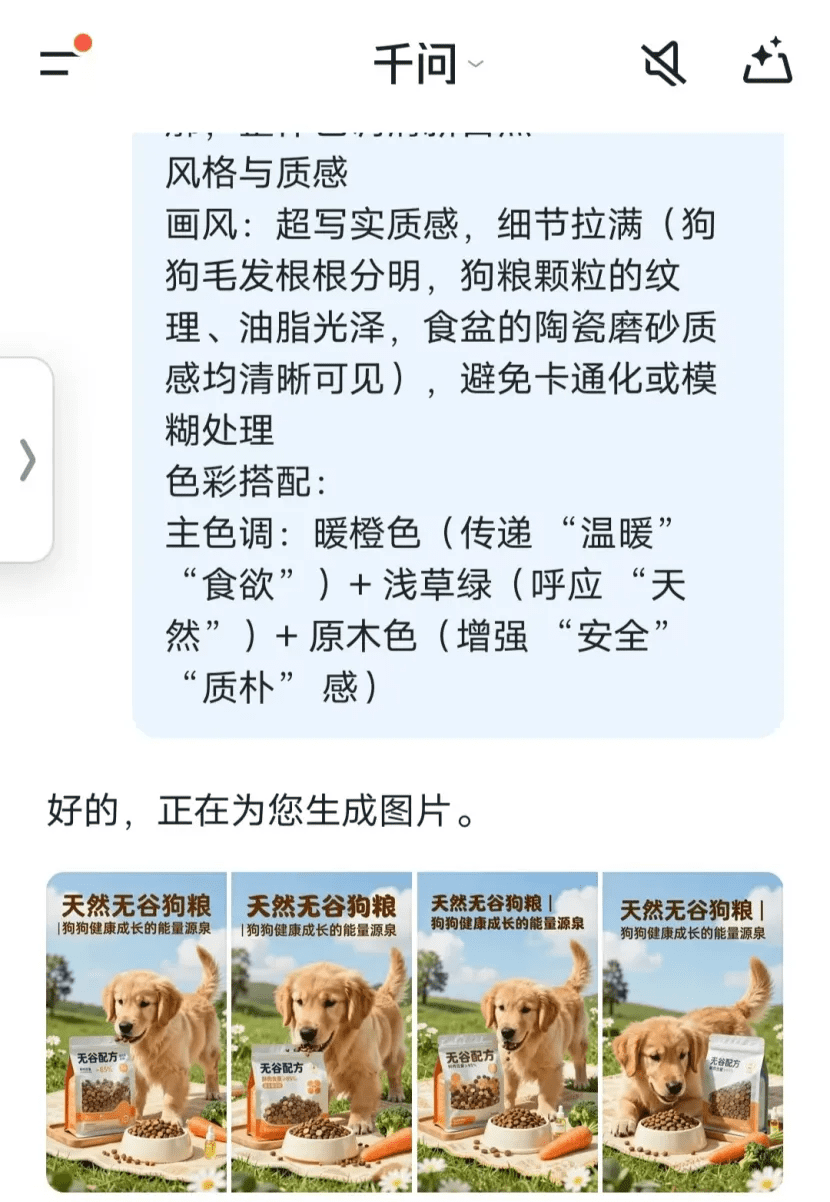
做一个海报,核心主题"天然无谷狗粮 | 狗狗健康成长的能量源泉" 视觉主体:纯种金毛,6-12个月幼犬,毛发蓬松有光泽,眼神灵动,正低头大口啃食狗粮(嘴角带少量粮屑,呈现"适口性极佳"的真实感),姿态放松愉悦(如趴在草地/地毯上,尾巴轻摇) 产品呈现:打开的狗粮包装袋(透明开窗设计,可见颗粒分明的狗粮,颗粒呈不规则六边形,颜色为浅棕+深棕渐变),袋身斜靠在木质托盘上,标注"无谷配方""鲜肉含量≥85%""益生菌添加"核心卖点 辅助元素:陶瓷食盆(装满狗粮,少量颗粒散落在食盆边缘),新鲜胡萝卜/西兰花(呼应"天然食材"),透明鱼油(暗示"美毛护肤"功效) 场景氛围:户外场景,青翠草地+蓝天白云,狗狗趴在野餐垫上进食,周围点缀几朵小雏菊 风格与质感:超写实质感,细节拉满(狗狗毛发根根分明,狗粮颗粒的纹理、油脂光泽,食盆的陶瓷磨砂质感均清晰可见) 色彩搭配:暖橙色(传递"温暖""食欲")+浅草绿(呼应"天然")+原木色(增强"安全""质朴"感)
测试结果显示,Qwen-Image 2511完全规避了文字截断、字体混淆问题,不仅实现了海报标题的精准呈现,画中画的狗粮包装袋上文字依然精准呈现。此外,画面中胡萝卜的大小、狗粮的质感,幼犬的形态、狗毛的真实毛绒质感还原也非常到位,可以直接用于电商平台上架。
更惊喜的是,Qwen-Image 2511生图时支持一键调整比例(1:1/2:3/3:4/9:16/4:3/16:9/3:2),无需借助第三方工具裁剪。在后期,Qwen-Image 2511还支持局部改字/改色、扩图、修改尺寸等等修改,这对生产级场景来说非常重要:毕竟AI生图一次性得到满意结果的概率并不大,往往需要精细、复杂的后期修改。而现在,这些工作已经可以交给AI精准完成。
对比一些付费生图工具,Qwen-Image 2511不仅在纹理还原度上表现更优,而且成本直接降为零,这对需批量制作素材的中小商家而言,具备极强的实用价值。
国产AI的实用主义突围
测完千问APP的两个新功能后,我们不难看出阿里这次升级的"野心":无论是Qwen-Image 2511解决中文生图痛点,还是Wan 2.5补齐国产视频音画同步短板,千问的此次升级背后正是国产AI模型的差异化突围范本。
Wan 2.5的环境音自适应、元素ID锁定,不仅能用于阿里电商的短视频带货场景,也能让普通人享受和家里宠物跨物种对话的神奇;Qwen-Image 2511的中文渲染以及精细控制能力,不仅能够造福各种中小商家,也能让没有作图能力的手残党感受创作的快乐。
当这些B端技术被改造成C端用户能轻松上手甚至免费的功能时,AI才真正从实验室走进了日常生活。而伴随创作成本大幅降低,国产AI工具也才有了成为新时代内容创作标准的可能,这才是真正的AI普惠。
从技术指标上看,国产AI已经达到了国际一流水平;从用户体验上看,免费模式让AI技术真正触手可及;从应用场景上看,从电商到个人创作,国产AI正在全方位渗透。千问APP的这次升级,或许标志着国产AI从"追赶者"到"引领者"的关键转折点。
未来,随着技术的不断迭代和生态的持续完善,我们有理由相信,国产AI将在更多领域实现突破,让更多人享受到技术进步带来的红利。而这,或许才是AI技术发展的终极意义——不是为了炫技,而是为了普惠。








