
在人工智能领域,AI大模型正以惊人的速度发展,成为研究和应用的热点。这些拥有庞大参数和强大计算能力的模型,如BERT和GPT系列,正在深刻地改变着自然语言处理、计算机视觉等领域。本文旨在深入探讨AI大模型的发展历程、技术原理、面临的挑战与未来的应用前景,为读者提供一份全面而深入的参考。
AI大模型的意义远不止于参数规模的增长,更在于它们解决复杂现实问题的潜力。通过学习海量数据,它们能够自动发现数据间的关联,高效处理和理解文本、图像等信息。随着科技的进步和数据量的增加,AI大模型将在更多领域展现其强大的能力,推动社会进步。
AI大模型的背景与相关工作
AI大模型通常指的是参数规模达到数十亿甚至数千亿级别的神经网络模型。这些模型依赖深度学习技术,通过大规模数据训练,在各种任务中表现出卓越的性能。
深度学习的演进
AI大模型的发展离不开深度学习技术的进步。深度学习通过构建多层神经网络模拟人脑工作原理,从而实现对复杂数据的学习和理解。以下是一些深度学习发展过程中的关键里程碑:
- 多层感知机(MLP): 作为早期的神经网络模型,MLP通过堆叠多层神经元实现对复杂数据的非线性建模。
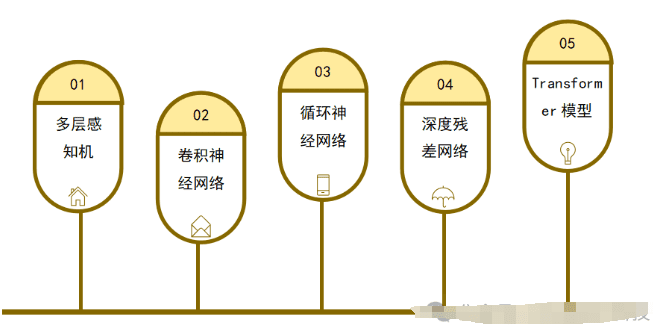
- 卷积神经网络(CNN): CNN专为图像处理任务设计,通过卷积层和池化层提取图像的局部特征,从而实现图像分类和目标检测等任务。
- 循环神经网络(RNN): RNN适用于序列数据处理,具有记忆功能,广泛应用于语言建模和机器翻译等任务。
- 深度残差网络(ResNet): ResNet通过引入残差连接,解决了深度神经网络训练中的梯度消失和梯度爆炸问题,使得训练更深层次的网络结构成为可能。
- Transformer模型: Transformer模型引入自注意力机制,用于处理序列数据,并在自然语言处理领域取得了显著成果。
随着数据量和计算资源的增加,研究人员开始构建更大规模、更复杂的神经网络模型,以提高模型的表征能力和泛化能力。这些大型模型,如BERT、GPT和T5,参数规模通常达到数十亿至数千亿级别。
AI大模型的兴起推动了人工智能领域的进步,并在自然语言处理、计算机视觉和强化学习等领域取得了一系列重要成果,使得人工智能技术在日常生活和工业生产中得到了广泛应用。
研究成果与应用案例
AI大模型在自然语言处理、计算机视觉和强化学习等领域取得了许多重要的研究成果和应用案例:
- BERT(Bidirectional Encoder Representations from Transformers): BERT是一种基于Transformer架构的预训练语言模型,通过双向编码器捕获文本中的双向上下文信息,在多个NLP任务上取得了领先成果,如文本分类、命名实体识别和文本相似度计算等。
- GPT(Generative Pre-trained Transformer): GPT系列模型是基于Transformer的生成式模型,可以生成连贯的自然语言文本,在文本生成和对话生成等任务中表现出色。
- T5(Text-to-Text Transfer Transformer): T5是一种通用的文本-文本转换模型,通过统一输入和输出形式,可应用于多种NLP任务,如翻译、摘要和问答等。
- ViT(Vision Transformer): ViT将Transformer应用于图像处理,将输入图像分割成图块,然后通过一系列线性和Transformer编码层进行处理,在图像分类任务上表现出色,甚至超越了传统的CNN模型。
- CLIP(Contrastive Language–Image Pre-training): CLIP模型通过将自然语言和图像的表示空间联系起来,实现了跨模态的视觉理解,在零样本学习和多模态任务中取得了良好表现,如图像分类和图像检索等。
- DQN(Deep Q-Network): DQN是一种利用深度学习技术实现的强化学习算法,已成功应用于玩Atarti游戏等任务。DQN结合了深度学习的表征能力和强化学习的决策能力,实现了在复杂环境中的高效决策。
- AlphaGo / AlphaZero: AlphaGo是由DeepMind开发的围棋AI,通过强化学习和深度神经网络技术,击败了世界顶级围棋选手。AlphaZero是AlphaGo的进化版,不依赖于任何人类的专家知识,只通过自我对弈学习,成为了顶级围棋、象棋和将棋AI。
面临的挑战与机遇
AI大模型面临着训练成本高昂、参数规模爆炸、泛化能力有限等挑战,但也蕴含着巨大的机遇:
- 挑战:
- 训练成本高昂: 训练大型神经网络模型需要大量的计算资源和时间。
- 参数规模爆炸: 模型规模的增大导致存储和计算复杂度急剧增加。
- 泛化能力限制: 在少样本、小样本场景下的泛化能力仍有待提高。
- 可解释性不足: 内部工作机制难以理解和解释。
- 数据隐私和安全性: 数据的隐私和安全性问题仍然是一个严峻的挑战。
- 机遇:
- 数据增长和计算能力的提升: 有望实现更好的性能。
- 模型优化和压缩技术的发展: 有效缓解模型的存储和计算压力。
- 多模态融合: 为更多复杂任务提供解决方案。
- 迁移学习和自适应学习: 进一步提高AI大模型的泛化能力。
- 领域交叉和合作创新: 有望推动AI大模型的发展迈向更高层次。
理论基础
AI大模型的理论基础对于模型构建和优化至关重要,它深刻影响着模型的性能和应用效果。
基本原理和核心技术
AI大模型的基本原理和核心技术包括:
- Transformer 架构: 一种基于自注意力机制的神经网络架构,完全采用了自注意力机制来实现序列到序列的学习。

- 自注意力机制: 允许模型在输入序列的所有位置上进行注意力计算,从而实现了对序列内部信息的全局建模。
- 预训练与微调: 通过在大规模无标注数据上进行自监督学习或者有监督学习,学习得到通用的特征表示。在微调阶段,模型在特定任务的有标注数据上进行微调,以适应任务的特定要求。
- 多头注意力: 允许模型在不同的子空间中学习不同的特征表示。
- 残差连接与层归一化: 提高深度神经网络性能的重要技术。
- 优化和正则化技术: 提高模型的性能和泛化能力。
神经网络训练与优化的基本理论
神经网络训练与优化的基本理论涵盖了许多重要概念和技术,例如:
- 损失函数(Loss Function): 衡量模型预测输出与实际标签之间差异的函数。
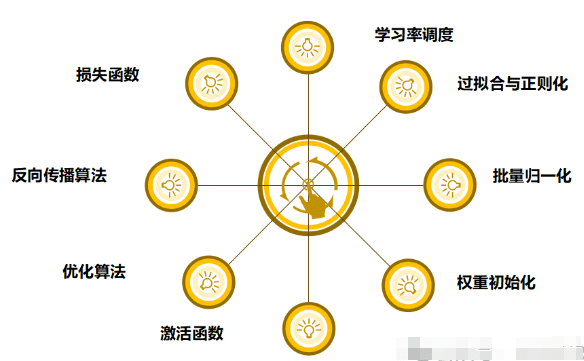
- 反向传播算法(Backpropagation): 用于计算损失函数关于模型参数的梯度。
- 优化算法(Optimization Algorithms): 用于调整模型参数以最小化损失函数。
- 激活函数(Activation Functions): 神经网络中的非线性变换,用于引入非线性因素以增加模型的表达能力。
- 权重初始化(Weight Initialization): 初始化神经网络参数的过程。
- 批量归一化(Batch Normalization): 加速神经网络训练和提高模型稳定性的技术。
- 过拟合与正则化(Overfitting and Regularization): 减少过拟合风险。
- 学习率调度(Learning Rate Scheduling): 动态调整学习率的方法。
相关的理论模型和概念
与AI大模型相关的理论模型和概念包括:
- 深度学习(Deep Learning): 一种机器学习方法,通过构建多层神经网络来模拟人类大脑的工作原理。
- 神经网络(Neural Networks): 深度学习模型的基础,它由多层神经元组成。
- Transformer 架构: 一种基于自注意力机制的神经网络架构。
- 自注意力机制(Self-Attention Mechanism): 用于捕捉序列数据中全局依赖关系的技术。
- 预训练与微调(Pre-training and Fine-tuning): AI大模型训练的常用策略。
- 多模态学习(Multi-Modal Learning): 将不同类型数据融合在一起进行联合建模的方法。
- 元学习(Meta-Learning): 让模型学会如何学习的方法。
技术方法
在研究和应用AI大模型时,技术方法的选择和运用至关重要。
训练大型模型的技术方法
训练大型模型涉及到许多技术方法和工程实践:
- 分布式训练(Distributed Training): 将模型的训练过程分布在多个计算节点上进行。
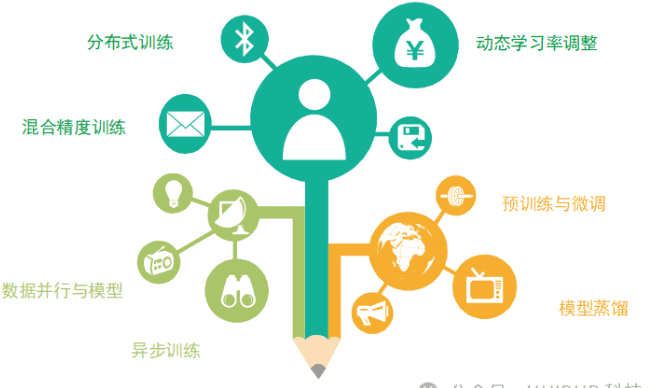
- 混合精度训练(Mixed Precision Training): 将模型参数的计算过程中使用不同的数值精度。
- 数据并行与模型并行(Data Parallelism vs Model Parallelism): 处理大型模型和大规模数据的训练。
- 异步训练(Asynchronous Training): 提高训练效率。
- 模型蒸馏(Model Distillation): 将一个大型复杂模型的知识转移到一个小型简单模型中来进行训练。
- 预训练与微调(Pre-training and Fine-tuning): 训练大型模型的常用策略。
- 动态学习率调整(Dynamic Learning Rate Adjustment): 提高模型的收敛速度和泛化能力。
大型模型的优化和压缩技术
针对大型模型的优化和压缩是提高模型效率、减少资源消耗、加速推理速度的重要手段。
- 模型剪枝(Model Pruning): 通过删除模型中冗余或不必要的参数和连接来减少模型的大小和计算量。
- 量化(Quantization): 将模型参数和激活值从浮点数表示转换为定点数或低位宽浮点数表示的过程。
- 低秩近似(Low-Rank Approximation): 通过将模型参数矩阵分解为多个较低秩的矩阵来减少模型的参数数量和计算量。
- 知识蒸馏(Knowledge Distillation): 通过将一个大型复杂模型的知识迁移到一个小型简单模型中来进行模型压缩的方法。
- 网络结构搜索(Neural Architecture Search,NAS): 自动化搜索适合特定任务的神经网络结构的方法。
- 动态模型调整(Dynamic Model Adaptation): 根据运行环境和输入数据的特性动态调整模型结构和参数的方法。
特定任务上的调参策略和实验技巧
- 选择适当的预训练模型: 选择一个适合的预训练模型作为基础。
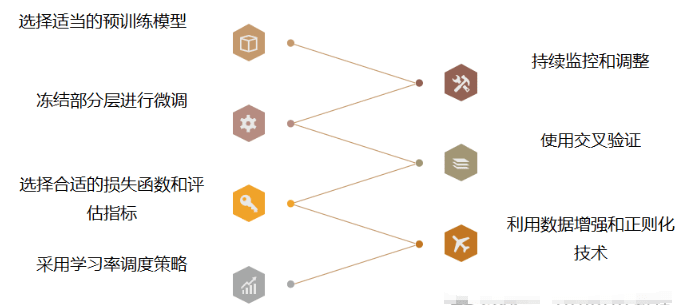
- 冻结部分层进行微调: 减少训练参数数量,加快训练速度,并降低过拟合的风险。
- 选择合适的损失函数和评估指标: 选择与任务相匹配的损失函数和评估指标。
- 采用学习率调度策略: 加速模型的收敛速度和提高性能。
- 利用数据增强和正则化技术: 提高模型的泛化能力和抗干扰能力。
- 使用交叉验证: 减少对单个验证集的依赖,提高模型评估的准确性和鲁棒性。
- 持续监控和调整: 反复迭代和实验,逐步优化模型并提高性能。
应用场景
AI大模型在各个领域展现出了巨大的潜力。
应用案例
AI大模型在不同领域的应用案例非常丰富:
- 自然语言处理(NLP): 语言理解、语言生成、机器翻译。
- 计算机视觉(Computer Vision): 图像分类和目标检测、图像生成。
- 自动驾驶与智能交通: 自动驾驶、智能交通管理。
- 医疗与生物信息学: 医学影像分析、药物设计与发现。
- 金融与风控: 信用评分、欺诈检测。
- 教育与辅助学习: 个性化教育、智能辅导。
优势和局限性
AI大模型在应用中具有许多优势,同时也存在一些局限性:
- 优势: 强大的表征能力、泛化能力强、多模态融合、自动化特征提取、持续迭代和优化。
- 局限性: 计算和存储资源需求大、可解释性差、数据隐私和安全风险、过拟合和泛化能力不足、环境依赖性。
未来发展趋势和应用场景
未来AI大模型的发展趋势将会朝着以下几个方向发展:
- 模型规模持续增大
- 跨模态融合
- 可解释性和可控性增强
- 自适应学习能力
- 个性化定制服务
- 边缘计算和端到端解决方案
- 多模态AI系统
结论与展望
本文探讨了AI大模型的理论、技术和应用,总结如下:
AI大模型具有强大的表征学习能力和泛化能力,在多个领域取得了显著成就。
在未来发展中,我们需要持续关注AI大模型的理论研究和技术创新,不断提高模型的性能和效率。同时,我们也需要探索更广泛的应用场景,将AI大模型应用于更多领域,实现人工智能技术的更大发展和应用。

