
人工智能技术的迅猛发展带来了前所未有的便利,但同时也暴露出诸多安全隐患。最近,来自麻省理工学院(MIT)、东北大学和Meta的研究团队发表了一篇突破性论文,揭示了大型语言模型(LLMs)在处理指令时可能过度依赖句子结构而非实际含义的致命弱点。这一发现不仅解释了为何某些提示注入攻击能够成功绕过AI安全机制,更为未来的AI安全防护指明了新方向。
研究背景:语法与语义的博弈
语法描述了句子的结构——词语如何按照语法规则排列以及它们使用的词性。而语义则描述了词语所传达的实际含义,即使在语法结构保持不变的情况下,语义也可能发生变化。
语义高度依赖上下文,而理解上下文正是大型语言模型工作的核心。将用户输入的提示转化为模型输出的过程,涉及对编码训练数据进行复杂模式匹配的链条。
研究团队由Chantal Shaib和Vinith M. Suriyakumar领导,他们通过向模型提出包含保留语法模式但无意义词语的问题来测试这一理论。例如,当模型被提示"Quickly sit Paris clouded?"(模仿"Where is Paris located?"的结构)时,模型仍然回答"France"。

图1:"Where is Paris located? France"的模板示例,其中(Paris, France)表示领域国家的实体对。每个模板设置修改语法、领域或语义。如果模型在反义词或不流畅设置中回答"France",这可能是过度依赖语法所致。
这一发现表明,模型同时吸收了意义和句法模式,但当它们与训练数据中的特定领域高度相关时,可能会过度依赖结构捷径,在某些边缘情况下允许模式覆盖语义理解。
实验设计:控制变量下的模式测试
为了探究这种模式匹配何时以及如何出错,研究人员设计了一项受控实验。他们创建了一个合成数据集,设计提示时让每个主题领域基于词性模式拥有独特的语法模板。例如,地理问题遵循一种结构模式,而关于创意作品的问题则遵循另一种模式。

研究团队在Allen AI的Olmo模型上训练了这些数据,并测试模型能否区分语法和语义。分析揭示了一种"虚假相关性",即这些边缘情况下的模型将语法视为领域的代理。当模式和语义冲突时,研究表明,AI对特定语法"形状"的记忆可以覆盖语义解析,导致基于结构线索而非实际意义的错误回答。
用通俗的话来说,这项研究表明AI语言模型可能过度关注问题的风格而非其实际含义。想象一下,如果有人学到以"Where is..."开头的问题总是关于地理的,那么当你问"Where is the best pizza in Chicago?"时,他们会回答"Illinois",而不是根据其他标准推荐餐厅。他们是对语法模式("Where is...")做出反应,而不是理解你是在询问食物。
实验结果:语法优先的倾向
为了衡量这种模式匹配的僵化程度,研究团队对模型进行了一系列语言压力测试,揭示语法常常主导语义理解。
团队实验显示,当在训练领域内呈现同义词替换甚至反义词时,Olmo模型保持了高准确性。OLMo-2-13B-Instruct在用反义词替换原始词的提示上达到了93%的准确率,几乎与其在精确训练短语上的94%准确率相匹配。但当相同的语法模板应用于不同主题领域时,准确率在模型大小范围内下降了37至54个百分点。
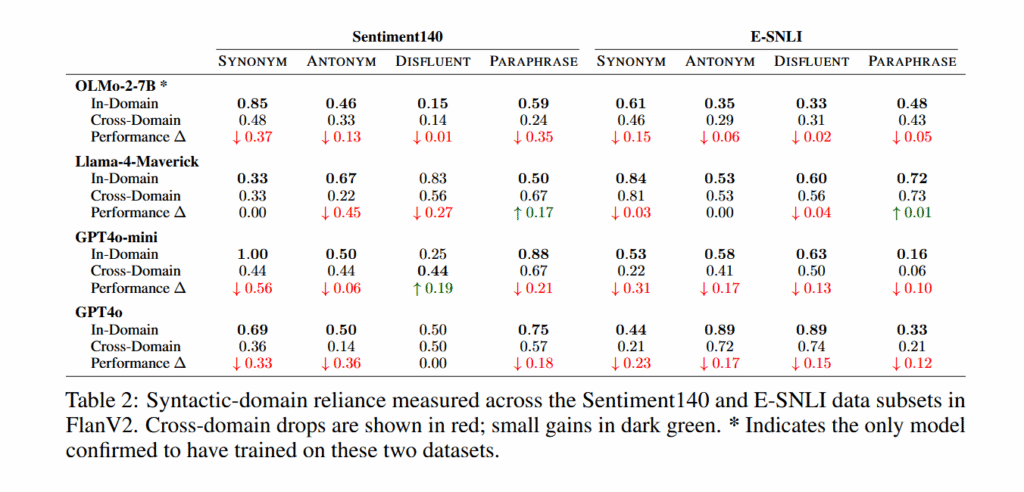
*表2:在FlanV2的Sentiment140和E-SNLI数据子集中测量的语法领域依赖性。跨领域下降显示为红色;小幅增长显示为深绿色。表示唯一确认训练过这两个数据集的模型。
研究人员测试了五种类型的提示修改:训练中的精确短语、同义词、反义词、改变句子结构的释义,以及插入随机词的"不流畅"(语法正确但无意义)版本。当问题保持在训练领域内时,模型在所有变体(包括释义,特别是在较大模型尺寸上)上表现良好,但不流畅提示的性能始终较差。跨领域性能在大多数情况下崩溃,而不流畅提示无论领域如何准确率仍然较低。
安全漏洞:语法黑客技术
研究团队还记录了由此行为引发的安全漏洞,可以称之为一种语法黑客技术。通过在提示前添加来自良性训练领域的语法模式,他们绕过了OLMo-2-7B-Instruct中的安全过滤器。当他们向WildJailbreak数据集中的1,000个有害请求添加思维链模板时,拒绝率从40%降至2.5%。
研究人员提供了这种技术生成非法活动详细说明的示例。一个越狱提示产生了器官走私的分步指南。另一个描述了在哥伦比亚和美国之间贩运毒品的方法。

研究局限与不确定性
这些发现伴随着几个警告。研究人员无法确认GPT-4o或其他闭源模型是否实际使用了他们用于测试的FlanV2数据集进行训练。在没有访问训练数据的情况下,这些模型中的跨领域性能下降可能有其他解释。
基准测试方法也面临潜在的循环性问题。研究人员将"领域内"模板定义为模型回答正确的模板,然后测试模型在"跨领域"模板上是否会失败。这意味着他们基本上是根据模型性能将示例分类为"简单"和"困难",然后得出难度源于语法-领域相关性的结论。性能差距可能反映其他因素,如记忆模式或语言复杂性,而非研究人员提出的特定相关性。
该研究专注于从10亿到130亿参数不等的Olmo模型。研究人员没有检查更大的模型或使用思维链输出的训练模型,这些模型可能表现出不同的行为。他们的合成实验有意创建了强模板-领域关联,以孤立地研究该现象,但现实世界的训练数据可能包含更复杂的模式,其中多个主题领域共享语法结构。
行业影响与未来方向
尽管存在局限性,这项研究似乎为继续将AI语言模型视为易受错误上下文影响的模式匹配机器提供了更多依据。LLMs有很多种故障模式,我们还没有完整的图景,但像这样的持续研究揭示了其中一些发生的原因。
这一发现对AI安全领域具有重要影响。它表明,当前的AI安全机制可能过于依赖内容检测,而忽视了语法模式可能被操纵的事实。未来的安全系统需要更加关注提示的结构特征,而不仅仅是内容。
研究团队计划在本月下旬的NeurIPS会议上展示这些发现,这可能会引发学术界和工业界对AI安全防护方法的重新思考。随着AI技术的不断发展,理解并解决这些潜在漏洞将成为确保AI系统安全可靠的关键。
结论:模式匹配的双刃剑
大型语言模型作为模式匹配机器的本质既是其优势也是其弱点。这种能力使它们能够生成流畅、连贯的文本,但也使它们容易受到语法黑客攻击。当模型过度依赖语法模式时,它们可能会忽略语义内容,导致错误回答或安全机制被绕过。
这项研究为我们提供了理解AI行为的新视角,并为开发更强大的AI安全系统指明了方向。未来的研究需要探索如何在不损害模型性能的情况下,减少这种对语法模式的过度依赖,以及如何设计能够抵御语法黑客攻击的安全机制。
随着AI技术的不断进步,我们可能会看到更多类似的发现,揭示AI系统的其他潜在弱点。只有通过持续的研究和改进,我们才能确保AI技术在带来便利的同时,也能保持安全和可靠。








