
在AI技术迅猛发展的今天,一款名为OiiOii的AI动画生成工具悄然走红,其内测邀请码在闲鱼上被炒到30元,2万多人排队等待体验。这款工具通过模拟真实动画工作室的协作流程,让普通用户也能在30分钟内生成70分以上的动画作品。本文将深入探讨OiiOii如何重塑动画创作生态,以及AI动画与专业动画电影的本质差异。
不是工具,是导演团队
传统AI视频工具如同教一个笨徒弟:用户输入Prompt,机器生成视频,效果不理想则需反复修改Prompt。而OiiOii彻底颠覆了这一模式,用户不再是与单个AI交互,而是拥有一支完整的"动画团队":艺术总监、场景设计师、编剧、分镜师等7个AI Agent各司其职。
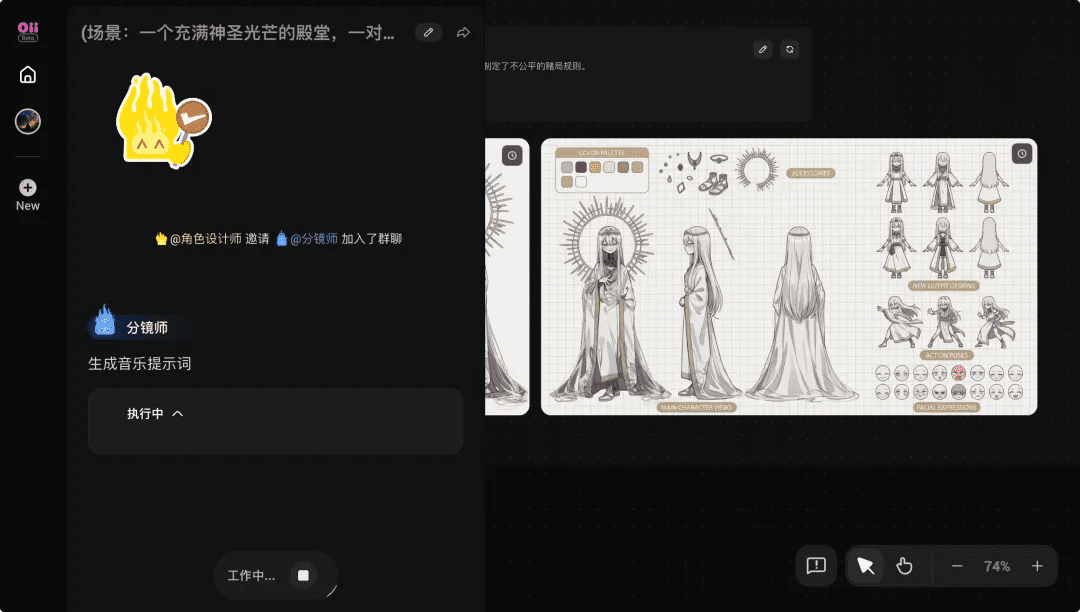
当用户输入一个充满神圣光芒的殿堂,一对兄妹与自称神的对手进行赌局的提示词后,系统首先启动编剧Agent拆解需求,编写剧本;随后角色设计师和分镜师Agent介入,设计角色和规划音乐。整个流程模拟了真实短剧公司的作业方式,用户只需在关键节点确认即可,大大降低了创作门槛。
几分钟后,一段包含音频、画面、转场的60秒短片便生成完成。无论是史诗感动漫,还是音乐MV,OiiOii都能保持画风一致性,展现出专业的镜头语言设计。
惊艳与遗憾并存
OiiOii生成的动画作品有两个显著特点:一是强烈的"导演感",二是明显的"粗糙感"。在镜头语言方面,OiiOii能够实现推拉摇移、景别变化、景深与焦点转换等符合影视逻辑的设计,这是大多数AI视频工具难以企及的。
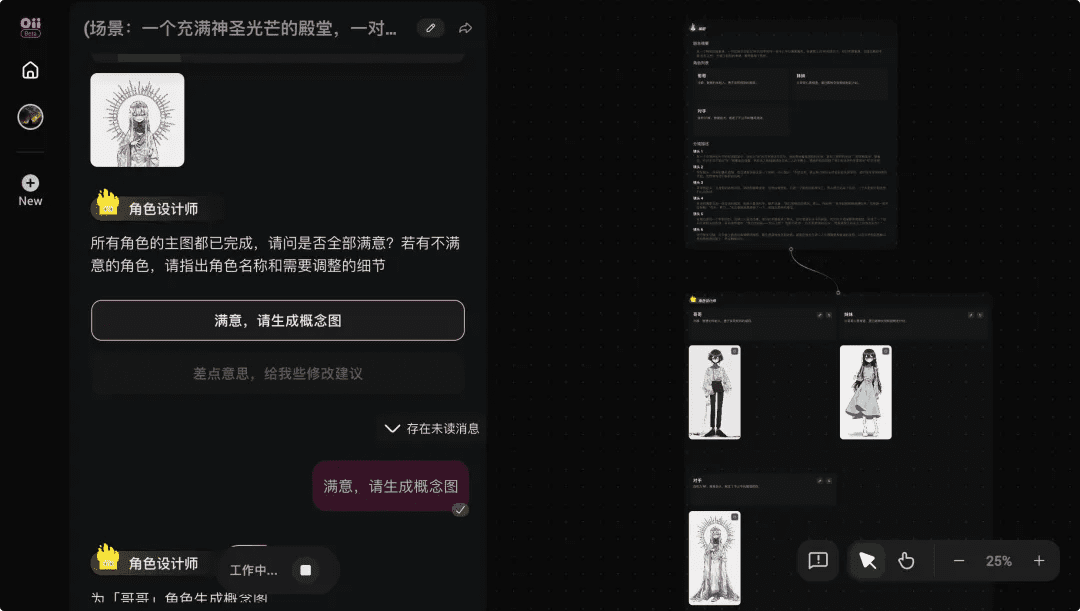
人物一致性是OiiOii的另一大亮点。以往使用Midjourney制作短片时,角色特征在不同镜头间容易发生变化,而OiiOii通过Agent协同和Sora2的能力,有效锁定了角色特征。
然而,目前的OiiOii作品仍存在画质不够高、创作时间较长等问题。在工业级动画电影面前,这些作品可能不及格;但在自媒体短视频、MV概念片领域,却能打出80分以上的成绩。这种"刚好够用"的质量,恰恰切中了广大创作者的需求痛点。
选择赛道比努力更重要
OiiOii的爆火验证了一个AI创业铁律:Agent创业必须垂直深耕。如果选择通用视频生成赛道,如Sora这类产品,将面临大众对真实世界100分的期待,而技术能力可能只有80分,任何人物扭曲或变化都会导致用户体验断崖式下跌。
而OiiOii聪明地选择了"动画"这一垂直赛道。在动画世界中,观众对夸张、变形的宽容度极高,这些被视为"艺术风格"而非技术缺陷。目前市场上同类产品让普通用户只能做出40分作品,而OiiOii通过Agent流程化封装,让小白也能稳定输出70分以上的作品。
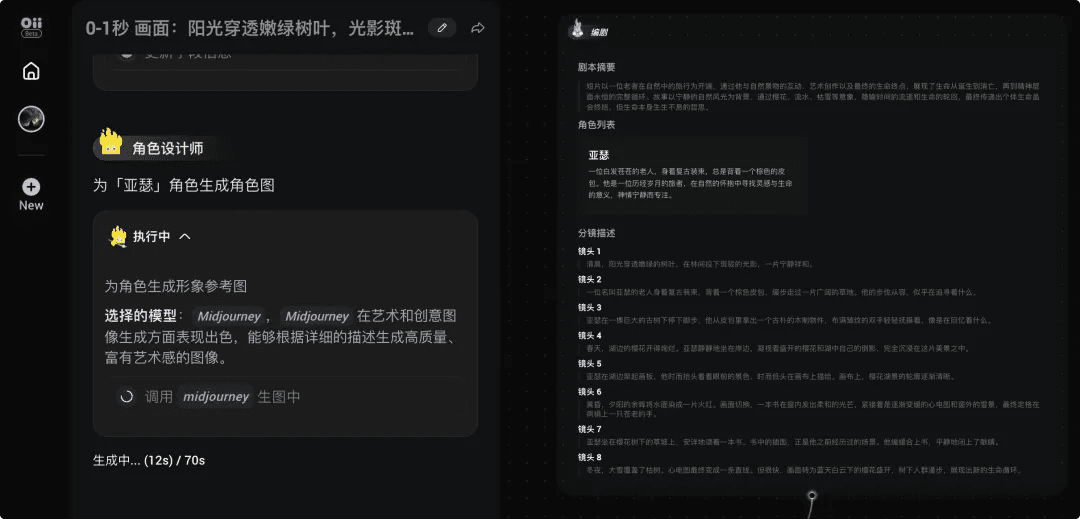
OiiOii将原本需要懂分镜、懂三视图、懂Prompt的专业门槛降至"会打字"即可,极大降低了创作门槛。同时,成本的大幅降低(从几十几百到免费体验)更是对自媒体创作者的生产力革命。
距离《疯狂动物城》,不是技术的距离
OiiOii生成的动画与《疯狂动物城》的差距,不仅仅是技术层面的。后者核心在于角色、情节和故事:朱迪与尼克的角色张力,关于偏见的隐喻,以及艺术家团队共同打磨的审美。
但如果对比的是"让普通人也能像迪士尼导演一样指挥团队讲故事",OiiOii已经推开了那扇门。它让非专业人士在30分钟内,通过对话将想法变成70-80分的动画。
AI动画正在创造新的内容形态。小红书上,越来越多博主开始用AI制作15秒的治愈、搞笑甚至猎奇故事,这些作品虽然画面不够精致,但胜在快速、个性化且能精准击中小众群体。AI动画的意义不在于替代皮克斯,而在于让每个人都能成为自己创意的导演。
真正的护城河,还是Know How
OiiOii的技术壁垒不在底层模型API,而在于行业Know-how。这些藏在创作团队脑海中的隐性知识,包括:
- 镜头语言:何时使用特写、全景等导演技巧
- 节奏感:30秒视频的前10秒抓眼球、中间10秒讲清楚、后10秒留钩子
- 角色一致性:确保同一角色在不同镜头中保持特征统一

这些Know-how才是OiiOii真正的壁垒。AI Agent的竞争,不是谁的人更多或接入的模型更强,而是谁更懂行业。模型会越来越开源,算力会越来越便宜,真正稀缺的是"懂动画+懂AI+懂产品"的复合型团队。
内测2万人,说明了什么?
OiiOii的爆火背后,反映了两个深层原因:
- AI视频动画的技术窗口已打开:Sora2和nanobanana2等模型解决了人物一致性的痛点,为AI动画发展提供了技术基础
- 需求侧的变化:短视频时代,每个人都需要视觉表达,但专业工具和人才供给不足
OiiOii填补了这一缺口,将原本1万人的专业创作圈扩大到20万人的泛创作者圈,预示着人人都可以创作动画时代的到来。
产品不免费还会有热度吗?
OiiOii面临的真正挑战不是技术,而是找到产品市场契合度(PMF)。内测期的免费策略吸引了大量用户,但当产品开始收费,用户付费意愿如何仍是未知数。
以字节最新发布的doubao-seedance-1.0-pro-fast模型为例,一条10秒的720p视频成本接近1元,20秒则接近2元。若产品定价5元,用户能否接受?只有当用户真正愿意为视频效果付费时,OiiOii才真正验证了PMF。
未知,更让人兴奋
OiiOii的意义在于它重新定义了"专业"的边界。以前,做动画需要专业知识、工具和大量时间投入;现在,OiiOii将门槛降至"会打字",让更多人获得"刚好够用"的专业能力。
AI动画打开了动画表达不再是少数人特权的大门。这扇门后面是什么?新形态的内容?甚至诞生新的"动画"品类?这种未知,才是最让人兴奋的部分。
纵观技术发展史,摄影从胶片时代到数码时代再到手机时代,没有让专业摄影师失业,反而让专业创作更容易,同时丰富了整个视觉内容生态。AI动画可能也会带来同样的变革:专业人才依然存在,而普通人也能参与创作,共同构建更丰富的动画内容生态。








