
在人工智能领域,大型语言模型(LLM)如ChatGPT,已经展示了惊人的文本理解和生成能力。然而,真实世界不仅仅是文本的,视觉信息同样重要。Visual ChatGPT的出现,正是为了弥合这一鸿沟,让LLM也能“看懂”世界,实现更丰富、更智能的人机交互。
摘要
Visual ChatGPT 不仅仅是一个聊天机器人,它更像一个多模态的AI助手。它能接收和发送图像,处理复杂的视觉任务,甚至能根据用户的反馈迭代优化结果。简单来说,它赋予了ChatGPT处理视觉信息的能力,让它能理解图像、生成图像,并根据视觉内容进行推理和决策。通过巧妙地将视觉模型的信息融入到ChatGPT的提示中,Visual ChatGPT实现了多输入/输出模型和视觉反馈模型的有效集成,为解决复杂的视觉问题提供了新的途径。
引言:当ChatGPT遇见视觉世界
ChatGPT的成功在于其强大的对话能力,能够理解上下文并生成连贯的回答。而BLIP模型擅长图像描述,Stable Diffusion则擅长根据文本生成图像。Visual ChatGPT 的核心思想是将这些视觉能力“嫁接”到ChatGPT上,使其能够处理视觉相关的任务。不同于从头训练一个多模态模型,Visual ChatGPT选择直接在ChatGPT的基础上构建,并集成多种视觉基础模型(VFMs)。为了弥补ChatGPT与这些VFMs之间的差距,Visual ChatGPT引入了一个提示管理器,负责:
- 明确告知ChatGPT每个VFM的功能特性,并指定输入输出格式。
- 将不同的视觉信息(如PNG图像、深度图像和掩模矩阵)转换为语言格式,以帮助ChatGPT理解。
- 处理不同VFM的历史记录、优先级和潜在冲突。
在提示管理器的帮助下,ChatGPT可以有效地利用这些VFMs,并以迭代的方式接收它们的反馈,直到满足用户的要求或达到预设的结束条件。
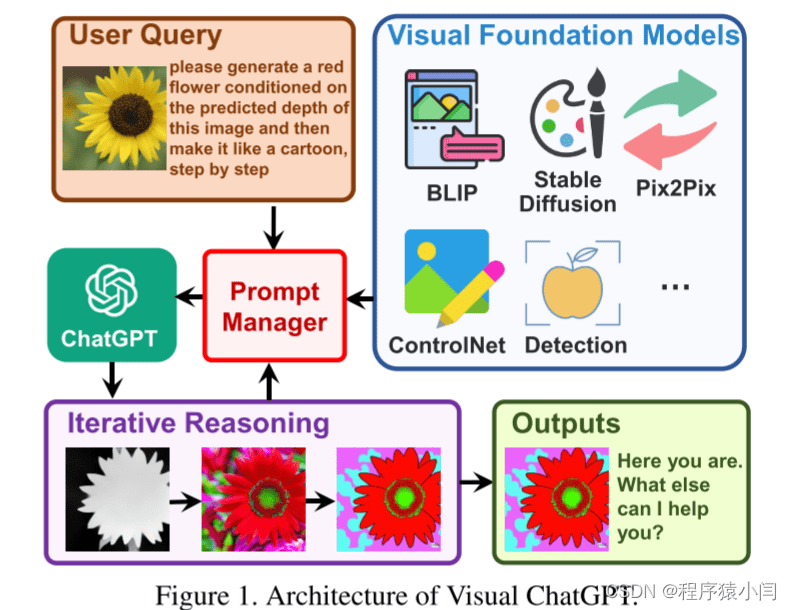
例如,用户上传一张黄花的图像,并指示:“请根据该图像的预测深度生成一朵红花,然后使其像卡通一样,一步一步地进行”。Visual ChatGPT在提示管理器的调度下,会启动一系列VFM的执行链:首先,深度估计模型检测图像的深度信息;然后,深度-图像模型生成具有深度信息的红花图像;最后,风格转移VFM将图像风格转换为卡通风格。整个过程中,提示管理器负责提供可视化格式类型,记录信息转换过程,并最终在获得“卡通”提示时结束执行流程,展示最终结果。
相关工作:站在巨人的肩膀上
Visual ChatGPT 的发展离不开以下几项关键技术:
- LiT (Locked-image Text Tuning): 一种零样本迁移学习方法,用于图像和文本的对齐。
- CLIP (Contrastive Language-Image Pre-training): 通过自然语言监督学习可迁移的视觉模型。
- ViT (Vision Transformer): 一种将Transformer架构应用于计算机视觉任务的模型。
- Frozen Pre-trained LLMs: 利用预训练的大型语言模型,避免从头开始训练的成本。
- Chain-of-Thought (CoT): 一种激发LLM多步推理能力的技术,要求LLM生成中间步骤以得出最终答案。Multimodal CoT 将语言和视觉模态结合,分阶段进行理论生成和答案推理。Visual ChatGPT 将 CoT 的潜力扩展到文本到图像生成、图像到图像翻译、图像到文本生成等大规模任务。
Visual ChatGPT 的架构
Visual ChatGPT 的核心在于其集成的VFMs以及提示管理机制。
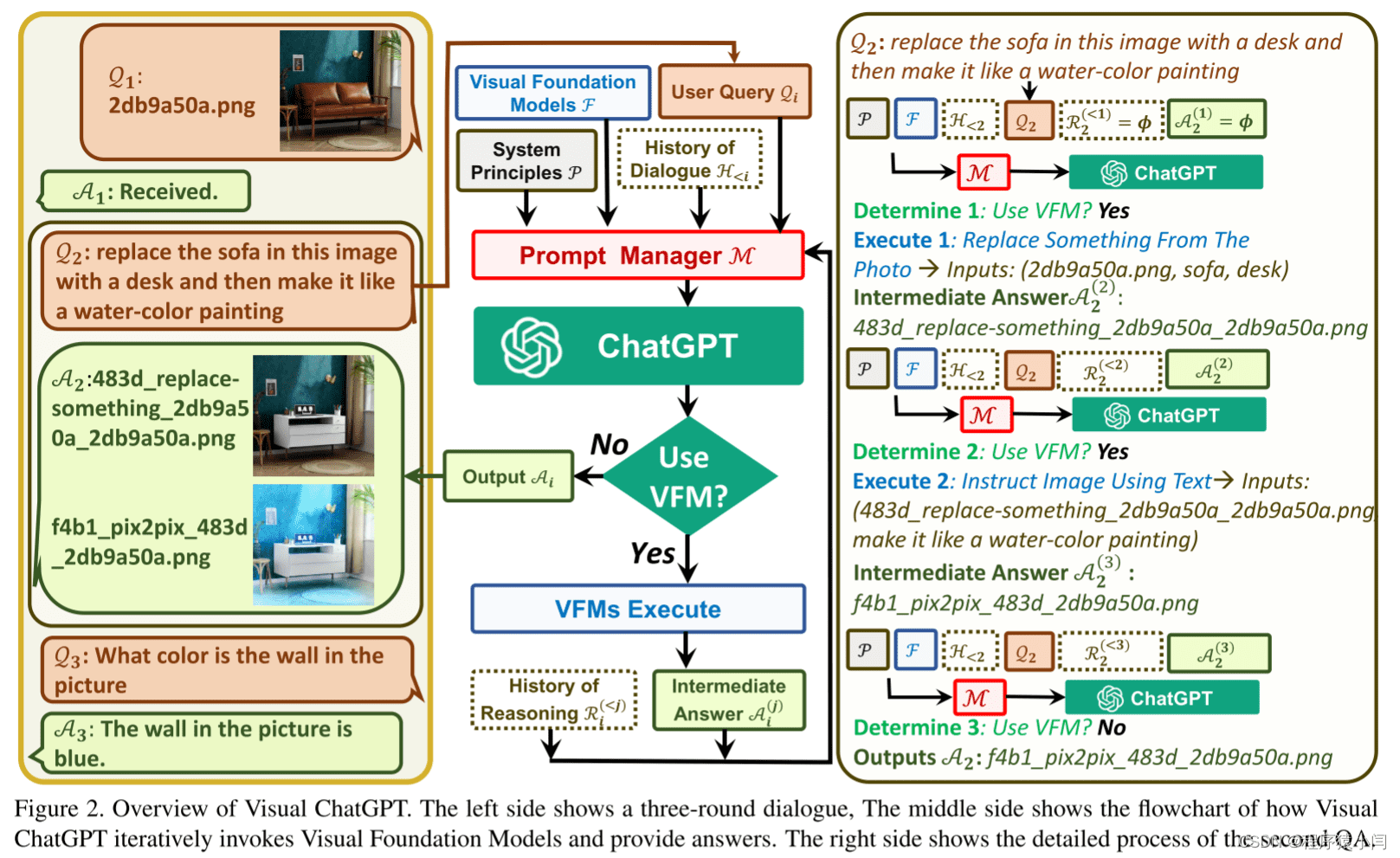
Prompt Managing of System Principles M(P):系统原则的提示管理
Visual ChatGPT 集成了不同的VFMs,以理解视觉信息并生成相应的答案。为了实现这一目标,需要定制一些系统原则,并将其转化为ChatGPT可以理解的提示。这些提示具有多种用途,包括:
- Visual ChatGPT 的角色: 明确Visual ChatGPT的目标是协助完成一系列与文本和视觉相关的任务,例如VQA(视觉问题回答)、图像生成和编辑。
- VFMs 可访问性: Visual ChatGPT 可以访问一个VFMs列表,以解决各种视觉语言(VL)任务。使用哪个基础模型的决定完全由ChatGPT模型本身做出,从而方便支持新的VFMs和VL任务。
- 文件名敏感性: Visual ChatGPT 根据文件名访问图像文件。由于一轮对话可能包含多个图像及其不同的更新版本,因此使用精确的文件名以避免歧义至关重要。Visual ChatGPT 被设计为严格使用文件名,以确保检索和操作正确的图像文件。
- 链式思维 (CoT): 处理一个看似简单的命令可能需要多个VFMs。例如,“根据图像的深度预测生成一朵红花,然后使其像卡通一样”的查询需要深度估计、深度到图像和风格转移VFMs。为了通过将查询分解为子问题来解决更具挑战性的查询,Visual ChatGPT 引入了 CoT 来帮助决策、利用和调度多个VFMs。
- 推理格式严格性: Visual ChatGPT 必须遵循严格的推理格式。详细的正则表达式匹配算法被用于解析中间推理结果,并为ChatGPT模型构造合理的输入格式,以帮助其确定下一次执行,例如触发新的VFM或返回最终响应。
- 可靠性: 作为一种语言模型,Visual ChatGPT 可能会编造虚假的图像文件名或事实,从而导致系统不可靠。为了解决这些问题,设计的提示要求Visual ChatGPT忠于视觉基础模型的输出,而不是捏造图像内容或文件名。此外,多个VFMs的协作可以提高系统的可靠性,因此构造的提示会指导ChatGPT优先利用VFMS,而不是基于会话历史生成结果。
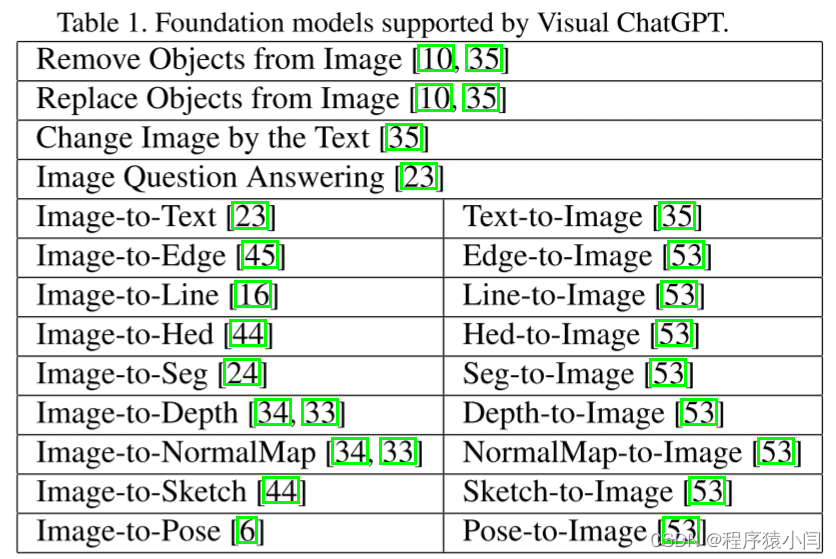
Prompt Managing of Foundation Models M(F):基础模型的提示管理
Visual ChatGPT 配备了多个VFMs来处理各种VL任务。由于这些不同的VFMs可能有一些相似之处,例如,图像中对象的替换可以被视为生成新的图像,图像到文本(I2T)任务和图像问答(VQA)任务都可以被理解为根据所提供的图像给出响应,因此区分它们至关重要。
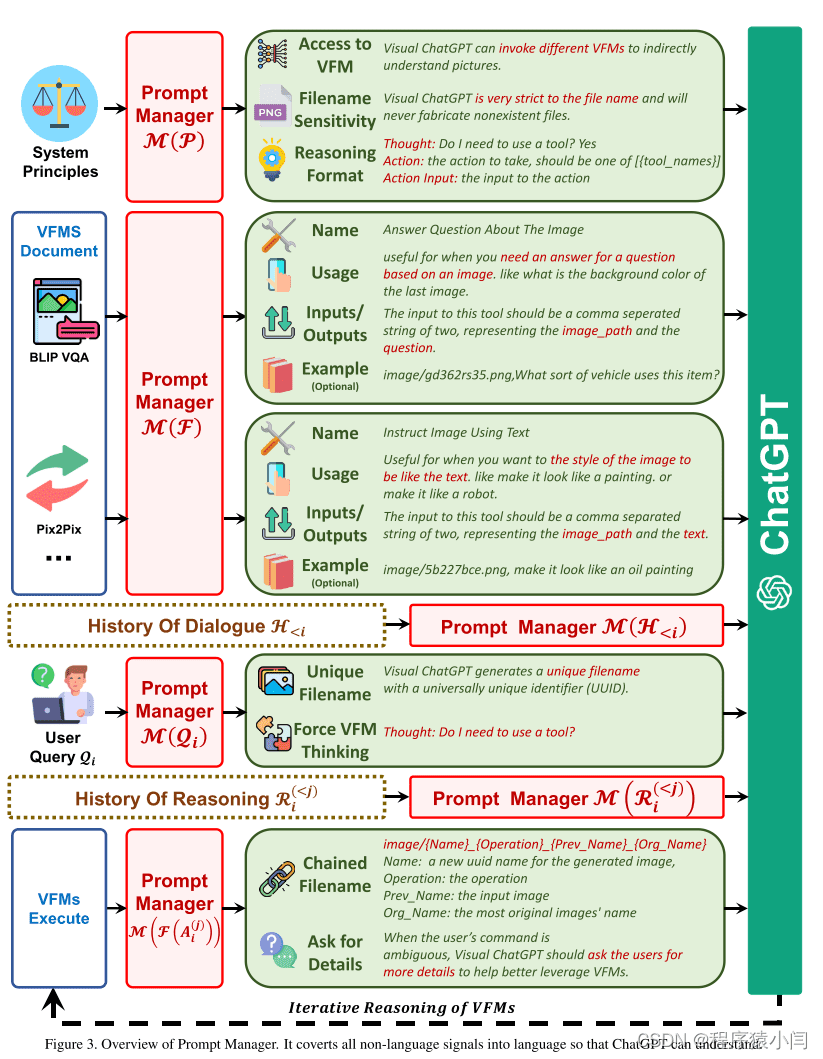
提示管理器具体定义了以下几个方面,以帮助Visual ChatGPT准确理解和处理VL任务:
- 名称: 名称提示符为每个VFM提供了总体功能的摘要,例如“回答有关图像的问题”。这不仅帮助Visual ChatGPT简明地理解VFM的目的,而且作为VFM的入口提供了帮助。
- 用法: 用法提示描述了应该使用 VFM 的具体场景。例如,Pix2Pix 模型适用于改变图像的风格。提供此信息有助于 Visual ChatGPT 做出有关将哪个 VFM 用于特定任务的明智决策。
- 输入/输出: 输入和输出提示概述了每个 VFM 所需的输入和输出格式,因为格式可能会有很大差异,并且为 Visual ChatGPT 正确执行 VFM 提供明确的指导至关重要。
- 示例 (可选): 示例提示符是可选的,但它有助于Visual ChatGPT更好地理解如何在特定的输入模板下使用特定的VFM,并处理更复杂的查询。
Prompt Managing of User Queries M(Qi):用户查询的提示管理
Visual ChatGPT 支持多种用户查询,包括语言或图像,简单或复杂的查询,以及多张图片的引用。Prompt Manager 从以下两个方面处理用户查询:
- 生成唯一文件名: Visual ChatGPT 可以处理两种类型的图像相关查询:涉及新上传图像的查询和涉及引用现有图像的查询。对于新上传的图像,Visual ChatGPT 会生成一个具有通用唯一标识符 (UUID) 的唯一文件名,并添加一个前缀字符串“image”来表示相对目录,例如“image/{uuid}.png”。虽然新上传的图像不会被输入 ChatGPT,但会生成一个虚假的对话历史记录,其中包含一个说明图像文件名的问题和一个表明图像已收到的答案。这个虚假的对话历史有助于后续对话。对于涉及引用现有图像的查询,Visual ChatGPT 会忽略文件名检查。这种方法已被证明是有益的,因为 ChatGPT 能够理解用户查询的模糊匹配,前提是它不会导致歧义,例如 UUID 名称。
- 强制VFM思考: 为保证VisualChatGPT的VFM成功触发,在(Qi)后面附加了一个后缀提示:“由于Visual ChatGPT是文本语言模型,Visual ChatGPT必须使用工具来观察图像,而不是想象。想法和观察仅对 Visual ChatGPT 可见,Visual ChatGPT 应记住在最终响应中为 Human 重复重要信息。想法:我需要使用工具吗?”这个提示有两个目的:1)提示 Visual ChatGPT 使用基础模型,而不是仅仅依靠它的想象; 2) 它鼓励 Visual ChatGPT 提供由基础模型生成的特定输出,而不是诸如“你在这里”之类的通用响应。
Prompt Managing of Foundation Model Outputs M(F(A(j)i )):基础模型输出的提示管理
对于来自不同VFMs F(A(j)i)的中间输出,Visual ChatGPT将隐式汇总并反馈给ChatGPT进行后续交互,即调用其他VFMS进行进一步操作,直到达到结束条件或反馈给用户。内部步骤可以总结如下:
- 生成链式文件名: 由于Visual ChatGPT的中间输出将成为下一轮隐式对话的输入,我们应该使这些输出更符合逻辑,以帮助LLMS更好地理解推理过程。具体地说,从Visual Foundation模型生成的图像保存在“image/”文件夹下,该文件夹提示以下表示图像名称的字符串。然后将图像命名为“{name}{operation}{prev name}{org name}”,其中{name}为上述UUID名称,以{operation}为操作名称,以{prev name}为输入图像唯一标识符,以{org name}为用户上传或VFMS生成图像的原始名称。例如,“image/ui3c edge-ofo0ec nji9dcgf.png”是输入“o0ec”的名为“ui3c”的canny边缘图像,该图像的原始名称是“nji9dcgf”。通过这样的命名规则,可以提示中间结果属性(即图像)的chatgpt,以及它是如何从一系列操作中生成的。
- 调动更多的VFMs: Visual ChatGPT的一个核心是可以自动调用更多的vfms来完成用户的命令。更具体地说,通过在每一代的末尾扩展一个后缀“though:”,使ChatGPT不断地问自己是否需要VFMS来解决当前的问题。
- 询问更多细节: 当用户的命令不明确时,Visual ChatGPT应该询问用户更多细节,以帮助更好地利用VFMS。这种设计是安全和关键的,因为LLMS不允许任意篡改或毫无根据地猜测用户的意图,尤其是在输入信息不足的情况下。
实验与评估
Visual ChatGPT 的性能可以通过各种视觉语言任务进行评估,例如视觉问题回答、图像生成和编辑等。 评估指标可以包括准确率、召回率、F1 值等。更主观的评估可以通过用户研究进行,考察用户对生成结果的满意度。
实验设置
研究人员使用LangChain引导LLM,并从HuggingFace Transformers、Maskformer和ControlNet中收集基础模型。全面部署所有22个VFMS需要4个NVIDIA V100 GPU,但也允许用户部署更少的基础型号,以灵活节省GPU资源。聊天历史记录的最大长度为2000个,并截断过多的令牌以满足chatgpt的输入长度。
局限性与未来方向
尽管 Visual ChatGPT 展现了巨大的潜力,但也存在一些局限性,例如:
- 对ChatGPT和VFMs的依赖:Visual ChatGPT的性能严重依赖于ChatGPT的任务分配能力以及VFMs的准确性和有效性。
- 提示工程的复杂性:将VFMS转换为语言,并使这些模型描述变得可区分,需要大量的提示工程,这需要计算机视觉和自然语言处理方面的专业知识。
- 实时能力:Visual ChatGPT 被设计为通用的,它试图将一个复杂的任务自动分解成几个子任务。因此,在处理特定任务时,Visual ChatGPT 可能会调用多个 VFM,与专门为特定任务训练的专家模型相比,实时能力有限。
- 令牌长度限制:ChatGPT中的最大令牌长度可能会限制可使用的基础模型的数量。 如果有数以千计或数以百万计的基础模型,可能需要一个预滤波模块来限制馈入ChatGPT的VFMS。
- 安全与隐私:轻松插入和拔出基础模型的能力可能会引起安全和隐私问题,特别是对于通过API访问的远程模型。必须仔细考虑和自动检查,以确保敏感数据不应暴露或泄露。
- 结果一致性:由于VFMS的故障和提示的不稳定,一些生成结果不能满足。因此,需要一个自校正模块来检查执行结果与人类意图之间的一致性,并据此进行相应的编辑。这种自我修正行为会导致对模型的思考更加复杂,显著增加推理时间。
未来的研究方向包括:
- 更高效的提示管理: 如何更有效地管理和组织大量的VFMs,减少提示工程的复杂性。
- 更强的实时性: 如何优化VFMs的调度和执行,提高Visual ChatGPT的实时响应能力。
- 更安全的模型集成: 如何确保模型集成的安全性和隐私性,防止敏感数据泄露。
- 自我修正能力: 如何让Visual ChatGPT具备自我修正的能力,提高生成结果的质量和一致性。
- 探索更多应用场景: 将Visual ChatGPT应用于更广泛的领域,例如智能家居、自动驾驶、医疗诊断等。
Visual ChatGPT 的出现,标志着LLM正在向多模态方向发展。随着技术的不断进步,我们有理由相信,未来的AI助手将更加智能、更加全面,能够更好地理解和满足人类的需求。








