
谷歌最近发布了号称是“世界最强”的大模型 Gemini,这无疑是人工智能领域的一个重大进展,标志着AI技术发展进入了一个新的时代。Gemini 的出现,让人们对AI的未来充满想象。
Gemini:多模态AI的新纪元
Gemini 被誉为“迄今为止最强大的AI模型”之一,其独特之处在于它融合了多种模式的处理能力,可以同时理解和生成文本、代码、音频、图像和视频。这种多模态的深度融合,让 Gemini 在处理复杂任务时具有更强的优势。
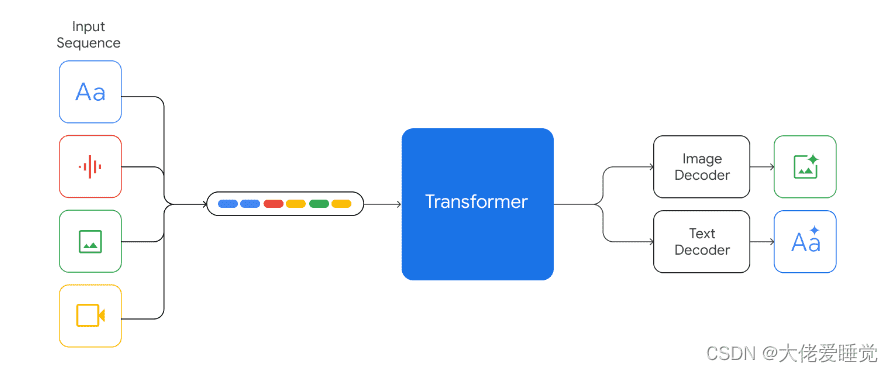
Gemini 的核心创新在于它的“原生多模态”架构。与传统的多模态模型不同,Gemini 并非简单地将文本、视觉和音频模型拼接在一起,而是从一开始就在不同模态上进行训练,实现了对各种模态输入内容的“无缝”理解和推理。简单来说,Gemini 能够直接处理音频、图片、文本、视频等多种数据类型,而无需将其转换为文本再进行处理。这种能力使得 Gemini 能够更自然、更高效地理解和处理信息。
这意味着 Gemini 能以更接近人类的方式理解我们周围的世界,无论是处理文字、代码,还是音频、图像和视频,它都能够胜任。
Gemini 的三大版本:Ultra、Pro 和 Nano
为了满足不同应用场景的需求,Gemini 被分为三个版本:Ultra、Pro 和 Nano。每个版本都针对特定的应用场景进行了优化。
- Gemini Ultra (超大杯):主要用于处理高度复杂的任务,面向数据中心和企业级应用。它是 Gemini 系列中性能最强大的版本,能够胜任各种复杂的AI任务。
- Gemini Pro (大杯):适用于广泛的任务,将成为许多 Google AI 服务的动力源。它是 Gemini 系列中性能适中的版本,适用于各种常见的AI应用。
- Gemini Nano (中杯):主要用于设备端任务,可以在移动设备上本地运行,例如 Android 设备。它是 Gemini 系列中体积最小、能耗最低的版本,适用于移动设备等资源受限的场景。
目前,我们能够体验到的是 Gemini Pro 版本。然而,官方演示中展现出碾压 GPT-4 性能的是 Gemini Ultra 版本,这无疑让人对 Gemini 的未来充满期待。
性能的突破
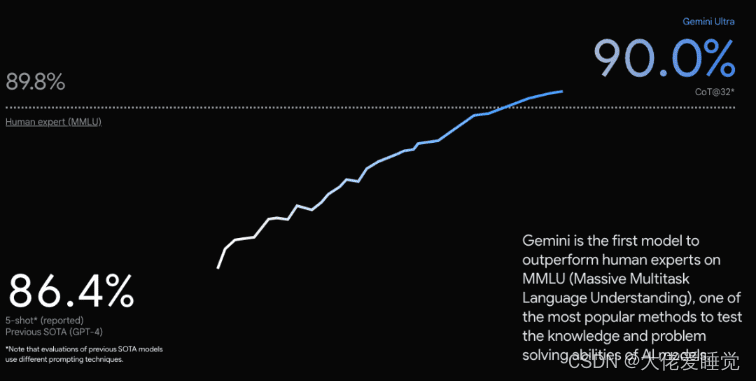
Gemini 在多个领域都实现了对现有技术的超越。它在 32 个广泛使用的学术基准测试中的 30 个上超越了现有技术,并且是第一个在大规模多任务语言理解(MMLU)测试中超越人类专家的模型。这些数据表明,Gemini 在性能方面取得了显著的突破。
应用范围
Gemini 的应用范围非常广泛,从改善 Google 自家产品(如搜索引擎、广告产品、Chrome 浏览器)到提供给开发者和企业客户的 API 服务,几乎涵盖了所有与 AI 相关的领域。其多模态能力特别适合处理复杂的科学问题,如数学和物理的推理问题,以及高质量的编程语言代码生成。
可以预见,未来我们日常使用的大部分生态都将接入 Gemini,比如最新的 Android 系统、Google 浏览器等一系列 Google 的产品。同时,Google 也会逐步开放 API,就像 GPT 的浪潮一样,Google 的 AI 浪潮才刚刚开始。
强大的训练基础

Google 利用其 AI 优化基础设施和自家设计的 Tensor Processing Units (TPUs) v4 和 v5e 对 Gemini 进行了大规模训练。此外,Google 还发布了 Cloud TPU v5p 系统,专为训练尖端 AI 模型而设计。这意味着 Google 完全有机会可以打破目前英伟达对芯片的垄断。

Gemini 的影响与展望
总的来说,Gemini 是 Google 对现有 AI 技术的一次重大提升,也是其积淀已久的一次爆发。通过其多模态融合能力,Gemini 有望在各个领域实现革命性的变革。然而,Gemini 的出现也引发了一些关于 AI 垄断的讨论。毕竟,Google 的强大地位是不容忽视的。
事实上,当初马斯克等人投资 OpenAI,部分原因就是为了打破 Google 在 AI 领域的垄断地位。如今,Gemini 的问世,无疑加剧了 AI 领域的竞争。
但具体表现如何,还需要时间来检验。让我们拭目以待,看看 Gemini 未来会给 AI 领域带来怎样的惊喜。








