在大型语言模型(LLMs)快速发展的今天,长序列处理能力已成为衡量模型性能的关键指标。传统全注意力机制在处理长文本时面临着KV缓存消耗大、计算效率低等挑战。月之暗面团队最新推出的Kimi Linear架构,通过创新的混合线性注意力设计,成功解决了这些痛点,为长文本处理领域带来了革命性突破。
Kimi Linear:重新定义长文本处理效率
Kimi Linear是月之暗面团队精心设计的新型混合线性注意力架构,专为提升大型语言模型在长序列任务中的效率和性能而打造。其核心组件Kimi Delta Attention(KDA)通过精细化的通道级门控机制和高效的块处理算法,显著提升了模型的表达能力和硬件效率。
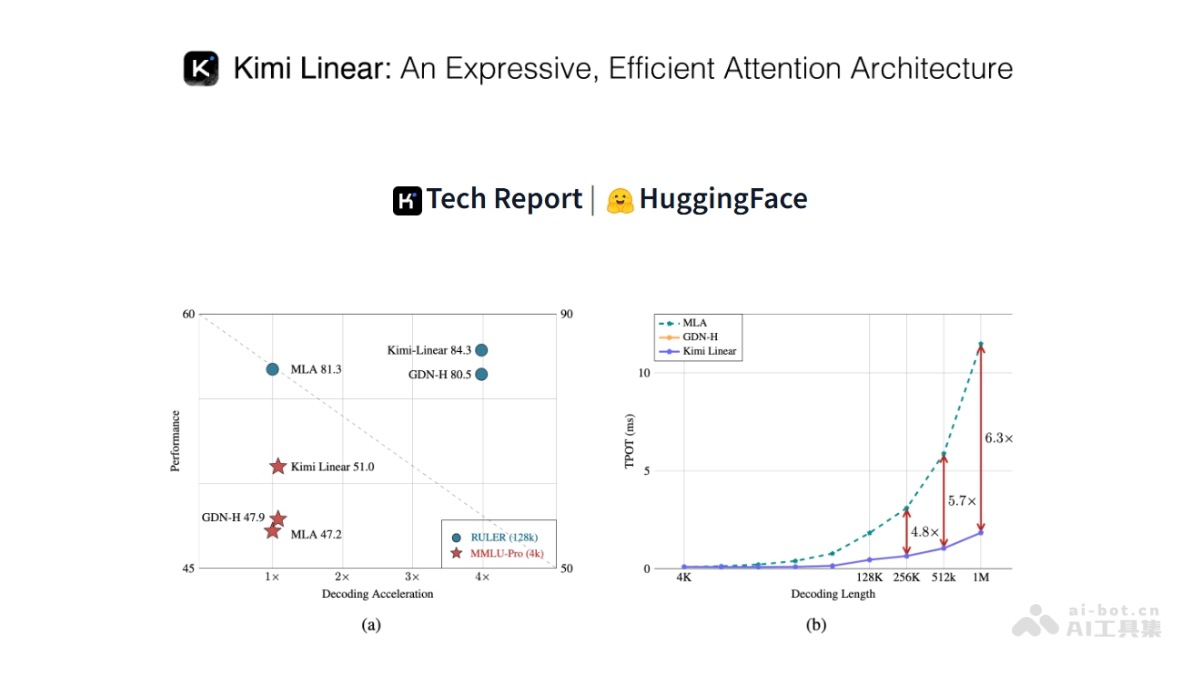
这一架构采用3:1的KDA与全注意力层(MLA)混合设计,巧妙结合了线性注意力的高效性和全注意力的强大表达能力。在实际应用中,Kimi Linear大幅减少了KV缓存的使用量(降低75%),在处理百万级长文本时实现了6.3倍的解码速度提升。这一突破性进展使得模型在保持高质量输出的同时,能够更高效地处理超长文本,为实际应用场景提供了更多可能性。
核心技术创新:Kimi Delta Attention机制
Kimi Linear架构的核心在于其创新的Kimi Delta Attention(KDA)机制。这一设计通过多种技术手段的有机结合,实现了在保持模型性能的同时大幅提升处理效率。
通道级门控机制
KDA引入了精细化的通道级门控机制,每个特征维度都有独立的遗忘率,类似于RoPE(Rotary Position Embedding)的位置编码方式。这种设计使模型能够更精确地选择性地保留关键信息、遗忘无关内容,从而显著增强长序列处理能力。通过这种方式,模型可以更好地理解文本中的位置关系,在处理长文档时保持上下文连贯性。
硬件高效的块处理算法
KDA采用创新的块处理并行算法,有效减少了计算量,提高了硬件利用率。其状态转移可以视为一种特殊的对角加低秩(Diagonal Plus Low-Rank, DPLR)矩阵,通过约束化的结构显著降低了计算复杂度。这一算法充分利用现代GPU的Tensor Cores,实现了高矩阵乘法吞吐量,从而大幅减少计算时间和资源消耗。
无位置编码设计
值得注意的是,Kimi Linear的全注意力层(MLA)不使用任何显式的位置编码(如RoPE),而是将位置信息的编码完全交给KDA层处理。这一设计简化了模型架构,同时增强了长文本任务的鲁棒性和外推能力。通过这种分工协作的方式,模型能够在不同长度的文本上保持一致的性能表现。
性能优势:全方位的突破
Kimi Linear架构在多个维度上展现出显著优势,这些优势使其在各类应用场景中都能表现出色。
计算效率的飞跃
通过KV缓存优化和高效算法设计,Kimi Linear在计算效率方面实现了质的飞跃。在处理百万级长文本时,其解码速度比传统全注意力机制提升了6.3倍,同时KV缓存使用量减少了75%。这一效率提升意味着更低的硬件成本和更快的响应时间,为大规模应用部署奠定了基础。
表达能力的保持与增强
尽管追求效率,Kimi Linear并未牺牲模型的表达能力。相反,通过创新的混合架构设计,模型在短序列和长序列任务中均优于传统的全注意力机制。特别是在需要复杂推理的强化学习任务中,Kimi Linear表现出色,训练准确率增长更快,测试集表现优于全注意力模型。
硬件友好的设计理念
Kimi Linear从设计之初就充分考虑了硬件实现因素。其高效的块处理算法充分利用现代GPU的Tensor Cores,实现了高矩阵乘法吞吐量。这种硬件友好的设计理念使得模型在实际部署时能够充分利用现有硬件资源,最大化计算效率。
与专家混合(MoE)技术的协同
Kimi Linear架构还与专家混合(Mixture-of-Experts, MoE)技术实现了有机结合。通过稀疏激活模式,模型能够扩展参数规模,进一步提升训练和推理效率。在Kimi Linear的实现中,模型总参数量达到480亿,但每个前向传播仅激活30亿参数,这种设计在保持模型容量的同时,显著降低了计算负担。
这种MoE与Kimi Linear的结合,使得模型能够在不同任务中动态选择合适的专家子网络,既提高了处理效率,又保持了模型的强大表达能力。这种协同设计为未来更大规模、更高效率的语言模型发展提供了重要参考。
广泛应用场景:从理论到实践
Kimi Linear架构凭借其卓越的性能和效率,在多个应用场景中展现出巨大潜力。无论是长文本生成、代码理解还是数学推理,这一架构都能提供出色的解决方案。
长文本生成的新突破
在长文本生成任务中,Kimi Linear的表现尤为突出。其高效的长序列处理能力使其能够轻松处理百万级长文本,解码速度提升6.3倍,使得生成长篇小说、研究报告等成为可能。这一突破对于内容创作、学术研究等领域具有重要意义。
代码生成与理解的革新
软件开发领域也是Kimi Linear的重要应用场景。其高效的长序列处理能力使其在代码生成和理解任务中表现出色,支持更复杂的代码逻辑和长代码片段的生成。这对于自动化编程、代码补全等应用具有重要价值。
数学推理能力的提升
在数学任务的强化学习训练中,Kimi Linear展现出独特优势。其训练准确率增长更快,测试集表现优于全注意力模型,使其特别适合解决复杂的数学问题。这一特性对于教育科技、科研计算等领域具有重要应用价值。
语言理解与问答的增强
Kimi Linear在短序列和长序列任务中均表现出色,使其成为语言理解与问答系统的理想选择。无论是简单问答还是需要长上下文理解的复杂问题,这一架构都能提供准确、连贯的回答。
多模态任务的潜力
除了纯文本处理,Kimi Linear还能用于多模态任务,如图像描述生成、视频内容理解等。其强大的长文本处理能力和逻辑推理能力,使其能够生成更长的文本描述和更复杂的逻辑分析,为多模态AI应用提供了新可能。
技术实现与开源价值
月之暗面团队已将Kimi Linear架构开源,为AI研究社区提供了宝贵的资源。开发者可以通过HuggingFace模型库访问预训练模型(https://huggingface.co/moonshotai/Kimi-Linear-48B-A3B-Instruct),并参考技术论文(https://github.com/MoonshotAI/Kimi-Linear/blob/master/tech_report.pdf)深入了解其实现细节。
这一开源举措不仅促进了技术的交流与进步,也为企业和研究机构在实际应用中采用这一先进架构提供了便利。通过开源,月之暗面团队希望推动整个AI社区在长序列处理领域的发展,共同探索大型语言模型的更多可能性。
未来展望:长序列处理的无限可能
Kimi Linear的出现标志着长序列处理领域的一个重要里程碑。其创新的混合线性注意力架构为解决传统注意力机制的局限性提供了全新思路。随着技术的不断发展和完善,我们有理由相信,Kimi Linear及其后续迭代将在更多领域发挥重要作用。
未来,随着硬件技术的进步和算法的持续优化,长序列处理能力将进一步增强,为AI应用开辟更广阔的空间。从智能助手到内容创作,从代码生成到科学研究,高效的长文本处理能力将成为AI系统的标配,而Kimi Linear架构无疑为此奠定了坚实基础。
结语
Kimi Linear作为月之暗面团队的重要成果,通过创新的混合线性注意力设计,成功解决了大型语言模型在长序列处理中的效率瓶颈。其核心组件Kimi Delta Attention通过精细化的通道级门控机制和高效的块处理算法,在保持模型强大表达能力的同时,显著提升了硬件效率。
这一开源架构的出现,不仅为AI研究社区提供了宝贵的资源,也为实际应用中的长文本处理问题提供了高效解决方案。随着技术的不断发展和完善,Kimi Linear有望在更多领域发挥重要作用,推动大型语言模型向更高效率、更强能力的方向发展。