人工智能领域近日迎来重大技术突破,月之暗面(MoonshotAI)发布了革命性的"Kimi Linear"混合线性注意力架构。这项创新技术不仅在理论上对传统注意力机制提出了挑战,更在实际应用中展现出惊人的性能提升,为AI模型效率优化开辟了全新路径。
技术革新:Kimi Linear的核心架构
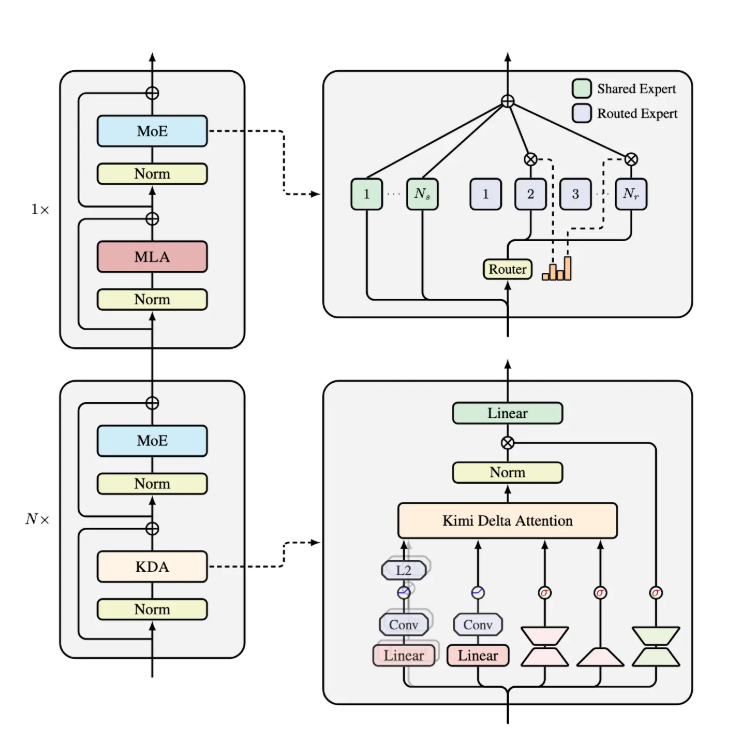
Kimi Linear架构的设计理念源于对传统注意力机制的深度反思与创新。该架构由三份Kimi Delta Attention(KDA)和一份全局多层感知机(MLA)组成,形成了一个高效的信息处理框架。这一设计的独特之处在于,它不是简单地堆叠计算层,而是通过精心设计的组件协同工作,实现了计算效率与模型性能的完美平衡。
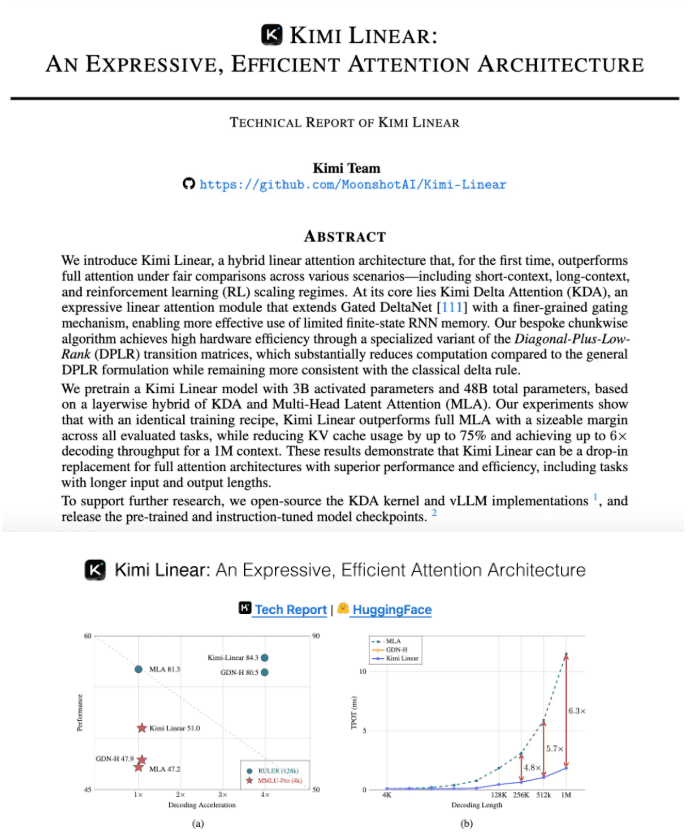
Kimi Delta Attention作为该架构的核心组件,实际上是对Gated DeltaNet的优化升级。传统Gated DeltaNet虽然在处理序列数据时表现出一定优势,但在内存使用和计算效率方面仍有较大提升空间。月之暗面的研发团队通过引入更高效的门控机制,显著提升了有限状态RNN(递归神经网络)记忆的使用效率,使得模型能够在保持高性能的同时,大幅降低资源消耗。
性能飞跃:数据说话的革新成果
技术革新的价值最终需要通过实际性能来验证。Kimi Linear架构在多项关键指标上实现了突破性进展,这些数据不仅令人印象深刻,更重新定义了业界对AI模型效率的认知标准。
在内存优化方面,Kimi Linear表现出色。官方测试数据显示,在处理1M token的大型场景下,该架构的KV缓存占用量相较于传统方法减少了惊人的75%。这一成果意味着模型在处理长文本时不再需要庞大的内存支持,大大降低了硬件门槛,使得更广泛的设备能够运行高性能AI模型。
计算速度的提升同样令人瞩目。Kimi Linear的解码吞吐量最高提升了6倍,这意味着在相同硬件条件下,AI模型的响应速度可以达到原来的6倍以上。对于需要实时处理的AI应用场景,如语音识别、实时翻译等,这一提升将带来用户体验的根本性改变。
在模型训练速度方面,Kimi Linear同样实现了质的飞跃。相较于传统MLA方法,该架构在TPOT(训练速度)指标上实现了6.3倍的加速。这一成果不仅意味着AI模型开发周期的显著缩短,还将大幅降低研发成本,加速AI技术的迭代与创新。
技术深度:Kimi Delta Attention的创新机制
Kimi Linear架构的核心优势在于其创新的Kimi Delta Attention机制。这一技术并非简单的参数调整或架构微调,而是对注意力计算范式的根本性重构。
传统注意力机制在处理长序列时面临计算复杂度高、内存消耗大的挑战。随着序列长度的增加,注意力矩阵的大小呈平方级增长,导致计算资源和内存需求急剧上升。这一问题在处理长文档、高分辨率图像或长时间序列数据时尤为突出,严重限制了AI模型的应用范围。
KDA机制通过引入细粒度门控机制,有效解决了这一难题。该机制不是简单地对所有信息进行平等处理,而是根据信息的重要性和相关性动态分配计算资源。对于关键信息,投入更多计算资源进行深入处理;对于次要信息,则采用更高效的处理方式。这种"智能分配"策略使得模型能够在保持重要信息处理质量的同时,大幅降低整体计算复杂度。
此外,KDA对有限状态RNN记忆的优化也值得关注。传统RNN在处理长序列时容易出现梯度消失或爆炸问题,导致模型难以学习长距离依赖关系。KDA通过改进门控机制,增强了RNN记忆的利用效率,使得模型能够更好地捕捉和利用序列中的长距离依赖信息。
应用前景:多场景适配的广泛可能性
Kimi Linear架构的优异性能使其在多种AI应用场景中展现出巨大潜力。无论是短距离处理、长距离处理还是强化学习等复杂任务,该架构都表现出优于传统全注意力方法的性能。
在自然语言处理领域,Kimi Linear有望彻底改变大语言模型的运行模式。当前,大语言模型受限于KV缓存大小,难以处理超长文本。Kimi Linear通过大幅减少KV缓存占用,使得模型能够一次性处理数十万甚至上百万token的文档,这将极大提升法律文件分析、学术论文研究、长篇小说创作等应用场景的效率。
在计算机视觉领域,该架构同样具有广阔应用前景。高分辨率图像处理需要处理大量的像素信息,传统方法往往受限于内存和计算能力。Kimi Linear的高效注意力机制可以显著降低图像处理的资源需求,使得在移动设备上实时处理高清图像成为可能。
对于强化学习等需要长期记忆和决策能力的AI系统,Kimi Linear的架构优势尤为明显。通过高效处理长序列状态信息和历史经验,该架构可以帮助智能体做出更准确的决策,在游戏AI、机器人控制、自动驾驶等领域发挥重要作用。
行业影响:重新定义AI效率标准
Kimi Linear架构的发布不仅是月之暗面的技术突破,更可能对整个AI行业产生深远影响。在AI模型规模持续扩大的今天,计算效率和内存优化已成为行业关注的核心问题。
当前,AI领域普遍存在"参数膨胀"现象,即通过不断增加模型参数规模来提升性能。这种方法虽然在一定程度上有效,但也带来了巨大的计算和能源消耗问题。据估计,训练大型AI模型的碳排放相当于多辆汽车的终身排放量,这与全球可持续发展趋势相悖。
Kimi Linear架构提供了一种全新的思路:通过算法创新而非简单堆砌参数来提升模型性能。这种"效率优先"的发展模式,可能引领AI行业从"规模竞赛"转向"效率竞赛",推动AI技术向更绿色、更可持续的方向发展。
此外,Kimi Linear显著降低的硬件需求,也有助于AI技术的民主化。当高性能AI模型不再需要昂贵的计算资源时,更多中小企业和研究者将能够参与AI创新,从而加速整个领域的技术进步和应用创新。
未来展望:技术演进与可能性
Kimi Linear架构的发布只是一个开始,而非终点。基于这一创新架构,我们可以预见AI领域将迎来一系列技术演进和应用创新。
在算法层面,KDA机制还有进一步优化的空间。随着对注意力机制理解的深入,研究人员可能会发现更高效的门控策略或更智能的信息分配机制,进一步提升模型性能。此外,Kimi Linear架构与其它AI技术(如稀疏注意力、线性注意力等)的结合,也可能产生意想不到的协同效应。
在应用层面,Kimi Linear架构有望催生一批全新的AI应用。例如,基于该架构的超长文本处理系统可以彻底改变知识工作方式;实时高精度语音识别系统将为无障碍沟通提供支持;高效的多模态AI模型可以实现更自然的人机交互。这些应用不仅将提升现有AI系统的性能,还将拓展AI技术的应用边界。
从更宏观的视角看,Kimi Linear架构代表了AI技术发展的重要趋势:从追求模型规模转向追求算法效率,从依赖硬件升级转向依赖软件创新。这一趋势将继续推动AI技术在保持高性能的同时,实现更低的资源消耗和更广泛的应用普及。
结语:算法创新引领AI新纪元
月之暗面发布的Kimi Linear架构,通过创新的Kimi Delta Attention机制,实现了KV缓存减少75%、推理速度提升6倍的惊人成果。这一技术突破不仅解决了AI领域长期面临的效率瓶颈,更为AI模型的设计与应用开辟了全新路径。
在AI技术快速发展的今天,算法创新的重要性日益凸显。Kimi Linear架构的成功证明,通过深入理解AI模型的内在机制,精心设计算法架构,我们可以在不牺牲性能的前提下,大幅提升计算效率和内存利用率。这种"效率优先"的技术路线,将成为未来AI发展的重要方向。
随着Kimi Linear架构及相关技术的不断完善和应用,我们有理由期待一个AI性能更强、能耗更低、应用更广的新时代。在这个时代,AI技术将不再局限于大型企业和研究机构,而是成为每个人都能轻松使用的工具,真正实现人工智能的普惠价值。