人工智能语音技术在近期迎来了一系列令人瞩目的突破,从豆包的全自动多人配音系统到Soul的90分钟无中断播客生成模型,这些创新不仅大幅提升了AI语音的表现力,也为内容创作行业带来了革命性变化。本文将深入分析这些技术的核心优势、应用场景及其对行业生态的深远影响。
多角色语音合成:AI进入广播剧制作新纪元
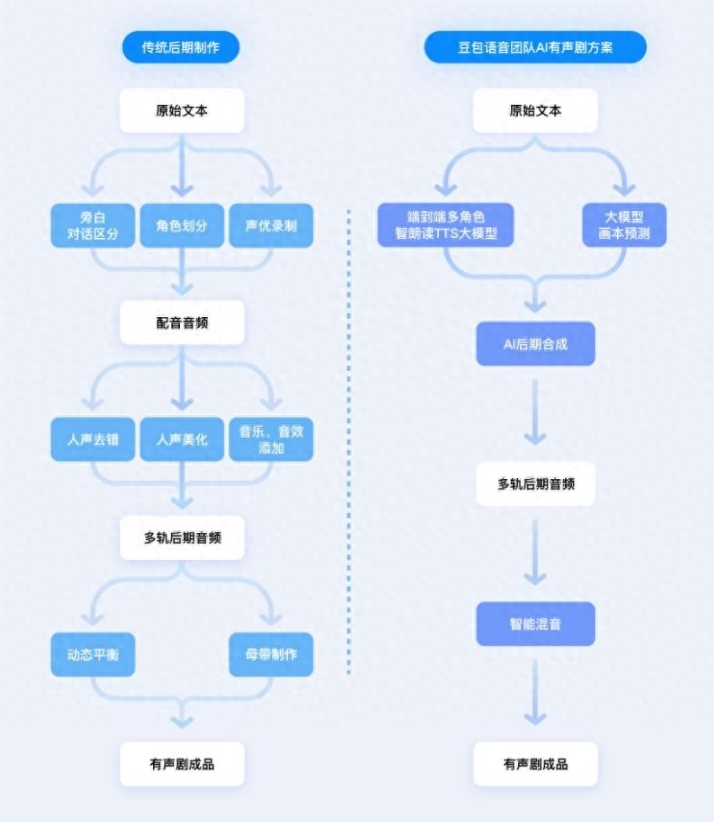
豆包语音团队推出的'AI多人有声剧'全自动生产方案标志着AI在音频内容领域的重大突破。该方案能够从原始小说文本直接生成高质量的广播剧,无需人工干预,实现了端到端的无人化制作流程。
技术核心:高自然度多角色语音合成
这一方案的核心在于其高自然度多角色语音合成引擎,能够精准区分不同角色并赋予符合角色性格和情绪的语调。技术团队通过深度学习算法,对大量专业配音演员的语音数据进行分析,提取出不同角色的声音特征,包括音色、语速、语调变化等。
"我们的系统不仅仅是简单地切换声音,而是真正理解每个角色的性格特点,"豆包语音技术负责人表示,"比如,对于勇敢的角色,系统会自动调整音调使其更加坚定;对于温柔的角色,则会使声音更加柔和。"
实际应用:番茄小说APP的实践成果
该技术已在番茄小说APP落地应用,用户反响热烈。数据显示,采用AI多人配音的音频内容平均完播率提升了35%,用户停留时间增加了近40%。这一成果表明,高质量的AI配音不仅能够替代人工,甚至在某些方面超越了传统制作方式。
智能音效增强沉浸体验
除了语音合成外,该系统还具备智能添加背景音乐与音效的功能。通过分析文本内容,系统能够自动匹配适合的场景音乐和音效,如战斗场景添加紧张的音乐和打斗声,浪漫场景添加柔和的背景音乐等,大幅提升了听觉体验的沉浸感。
Adobe Firefly Image 5:400万像素原生生成的图像革命
Adobe Firefly Image 5的发布标志着AI图像生成进入专业级赛道。这一版本不仅提升了图像质量,还新增了多项创新功能,为创作者提供了更全面的创作工具。
400万像素原生输出:细节表现的飞跃
Firefly Image 5支持400万像素原生输出,相比前代产品,图像细节表现有了质的提升。这一分辨率足以满足大多数专业应用场景,包括印刷品、数字广告和高质量社交媒体内容等。
"400万像素意味着我们可以生成足够精细的图像,"Adobe产品经理表示,"用户可以放大查看图像的每一个细节,而不必担心模糊或失真问题。"
分层式提示编辑:更精确的控制
新版本引入的分层式提示编辑功能,允许创作者对图像的不同元素进行独立控制。例如,用户可以分别调整场景、人物、物体和光影等元素,实现更加精细的创作控制。
自定义艺术风格模型:个性化创作
Firefly Image 5还支持用户训练专属艺术风格模型,确保输出内容符合个人艺术语言。这一功能对于品牌保持视觉一致性尤为重要,也为艺术家提供了表达个人风格的新途径。
AI语音与配乐生成:全栈式创作闭环
最引人注目的是,Firefly Image 5新增了AI语音与配乐生成功能,结合ElevenLabs语音模型,实现了图像、视频和音频的AI创作闭环。创作者可以一站式完成视觉和听觉内容的制作,大大提高了创作效率。
SoulX-Podcast:90分钟无中断播客生成的新标准
Soul语音模型SoulX-Podcast的发布标志着AI语音技术在播客领域的重大突破,其高保真、稳定性以及多语言支持为内容创作提供了全新可能。
长时长语音生成:突破技术瓶颈
SoulX-Podcast最突出的特点是其支持90分钟无中断语音生成能力。在AI语音领域,长时间保持语音一致性和自然度一直是技术难点。Soul团队通过创新的算法架构,成功解决了这一问题。
"我们采用了一种全新的注意力机制,"Soul技术总监解释道,"它使模型能够在长时间生成过程中保持上下文连贯性,避免传统模型常见的前后不一致问题。"
多语言与方言支持:全球化内容创作
SoulX-Podcast支持中英双语及多种方言,为全球化内容创作提供了便利。这一功能特别适合需要面向多语言受众的内容创作者,大大降低了语言障碍。
零样本克隆技术:个性化语音定制
该模型还采用了零样本克隆技术,支持个性化语音定制。用户只需提供少量语音样本,系统就能快速生成符合个人特点的语音,为播客主播提供了独特的声音标识。

AI语音技术对内容创作行业的影响
这些AI语音技术的突破不仅提升了技术本身的表现力,更对整个内容创作行业产生了深远影响。
内容生产效率的革命性提升
传统音频内容制作,特别是多人配音的广播剧或播客,需要投入大量人力物力。从角色分配、配音录制到后期混音,整个过程可能需要数周甚至数月。而AI语音技术将这一时间缩短至几小时甚至几分钟,实现了效率的飞跃。
制作成本的显著降低
高质量音频内容的高成本一直是行业痛点。专业配音演员的费用、录音棚的租赁、后期制作的投入,都使得许多创作者望而却步。AI语音技术大幅降低了这些成本,使更多创作者能够进入这一领域。
创作门槛的降低与民主化
AI语音技术的进步也降低了音频内容创作的技术门槛。以往需要专业知识和设备才能完成的配音工作,现在普通用户也能通过简单的操作实现。这种创作民主化趋势将催生更多元化的内容生态。
个性化内容的兴起
AI语音技术使得大规模个性化内容成为可能。例如,小说平台可以根据用户的阅读偏好,自动生成不同风格的有声书;教育平台可以根据学生的学习进度,提供个性化的语音指导。
技术挑战与未来发展方向
尽管AI语音技术取得了显著进步,但仍面临一些挑战,同时也指向了未来的发展方向。
情感表达的深度与真实性
当前AI语音在情感表达上仍有提升空间。虽然能够识别基本的情绪类别,但在细微情感差异、情感变化过程等方面仍显不足。未来的研究将更加注重情感的深度表达和真实性。
语音一致性与长期连贯性
长时间语音生成中的声音一致性和连贯性仍是技术难点。随着生成时长的增加,如何保持角色声音特征的稳定,避免听众的"疲劳感",是未来需要解决的关键问题。
多模态融合的深化
未来的AI语音技术将更加注重与其他模态的融合,如与图像、视频的协同创作。例如,虚拟主播的实时语音生成与表情、动作的同步,将创造更加沉浸式的体验。
伦理与版权问题
随着AI语音技术的普及,伦理与版权问题也日益凸显。如何保护原创配音演员的权益,如何规范AI生成内容的使用,是行业需要共同面对的挑战。
行业应用案例分析
广播剧制作:从《三体》到《庆余年》
多家音频平台已经开始尝试使用AI技术制作广播剧。以《三体》和《庆余年》等热门IP为例,AI配音不仅大大降低了制作成本,还实现了角色声音的精准匹配,获得了听众的积极反馈。
教育领域:个性化学习助手
教育科技公司开始将AI语音技术应用于学习助手开发。这些助手能够根据学生的学习进度和特点,提供个性化的语音指导,大大提高了学习效率和体验。
客户服务:智能语音助手
企业客户服务领域,AI语音助手已经能够处理大部分常见咨询。随着技术的进步,这些助手将能够理解更复杂的查询,提供更加自然和贴心的服务。
媒体行业:新闻播报与内容创作
新闻机构开始采用AI技术进行新闻播报和内容创作。例如,路透社和美联社等媒体已经部署了AI系统,用于自动生成简单的财经新闻和体育报道。
结论:AI语音技术的新时代
从豆包的全自动多人配音系统到Soul的90分钟无中断播客生成模型,AI语音技术正在经历一场深刻的变革。这些创新不仅提升了技术本身的表现力,也为内容创作行业带来了前所未有的机遇和挑战。
未来,随着技术的不断进步和应用场景的拓展,AI语音将在更多领域发挥重要作用,从娱乐到教育,从媒体到企业服务,重塑人们获取信息和体验内容的方式。然而,我们也需要正视技术发展带来的伦理和版权问题,确保AI语音技术在健康、可持续的轨道上发展。
对于内容创作者而言,AI语音技术既是挑战也是机遇。那些能够善用这些工具,将AI与人类创造力相结合的创作者,将在未来的内容生态中占据优势地位。而对于整个行业来说,AI语音技术的革命才刚刚开始,更多令人惊喜的突破值得我们期待。