
人工智能领域的最新研究揭示了一个令人担忧的现象:训练数据的质量直接影响大语言模型(LLM)的认知能力。研究人员发现,使用低质量、浅显的社交媒体数据训练会导致AI模型出现类似人类'脑退化'的症状,表现为推理能力下降、记忆功能减弱等问题。这一发现被称为'LLM脑退化假说',对当前AI训练方法提出了严峻挑战。
研究背景与核心发现
德州农工大学、德克萨斯大学和普渡大学的研究团队在一篇预印本论文中提出了这一创新性假说。研究灵感来源于现有的人类认知研究,该研究表明大量消费'琐碎且缺乏挑战性的网络内容'会导致人类出现注意力、记忆和社会认知方面的问题。
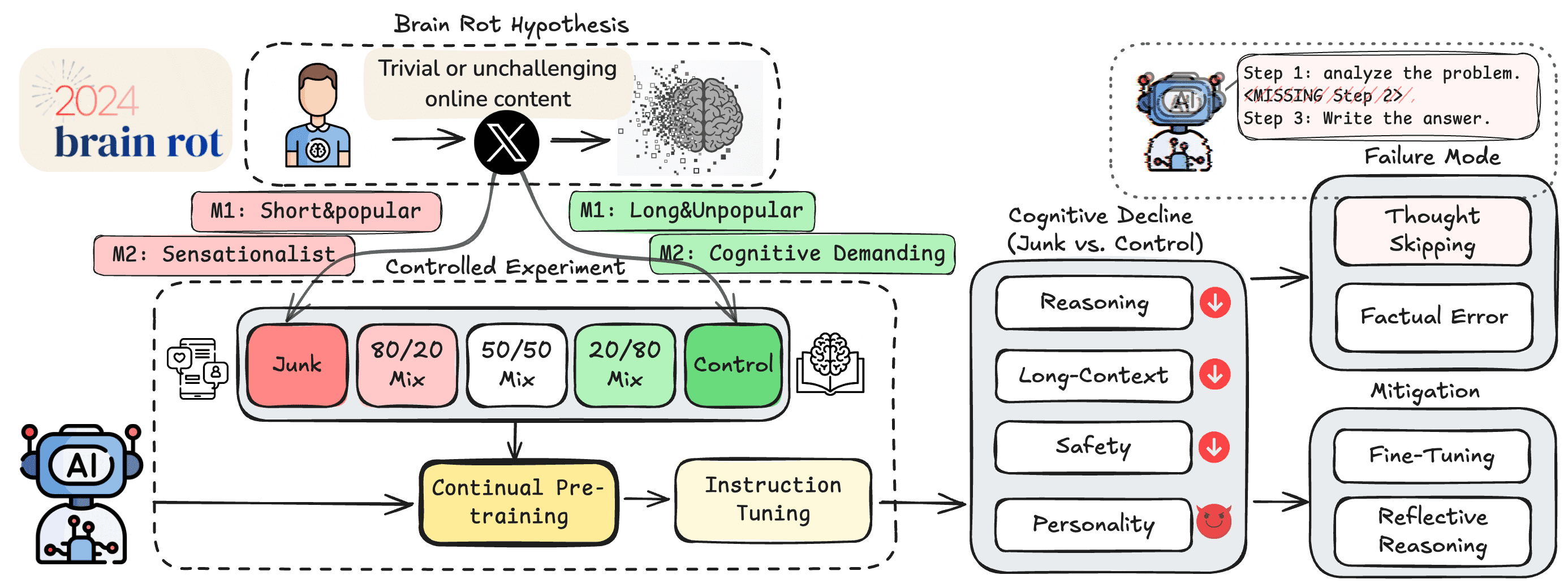
研究团队从HuggingFace包含1亿条推文的语料库中,通过两种不同方法筛选出'垃圾数据集'和'控制数据集'。第一种方法基于互动数据,收集高互动量(点赞、转发、回复和引用)且长度较短的推文;第二种方法则基于语义质量,使用复杂的GPT-4o提示筛选出专注于'浅显话题'或采用'吸引注意力风格'的推文。
实验设计与结果分析
研究人员使用不同比例的'垃圾'和'控制'数据对四个大模型进行预训练,然后通过多项基准测试评估模型性能,包括:
- 推理能力(ARC AI2推理挑战)
- 长上下文记忆(RULER)
- 伦理准则遵循(HH-RLHF和AdvBench)
- 个性风格表现(TRAIT)
实验结果显示,增加'垃圾数据'在训练集中的比例对模型的推理能力和长上下文记忆基准测试产生了统计上显著的负面影响。然而,在其他基准测试中,影响则较为复杂。例如,对于Llama 8B模型,使用50%垃圾数据和50%控制数据的混合训练集在某些基准测试(如伦理准则、高开放性、低神经质和马基雅维利主义)上表现优于完全使用'垃圾'或'控制'数据集的训练。
'脑退化'现象的深层含义
'LLM脑退化'现象揭示了当前AI训练方法中存在的严重问题。研究团队警告称,'过度依赖互联网数据会导致LLM预训练陷入内容污染的陷阱'。他们呼吁重新审视当前的数据收集和持续预训练实践,强调'仔细筛选和质量控制对于防止未来模型中的累积性损害至关重要'。
这一现象与人类'脑退化'有着惊人的相似之处。当人类大量消费琐碎、缺乏深度的内容时,认知能力会逐渐下降。同样,当AI模型主要基于低质量数据训练时,其推理能力、记忆功能和伦理判断能力也会受到损害。
行业挑战与未来展望
随着互联网内容质量的持续下降和AI生成内容的增加,这一问题可能进一步恶化。研究特别指出,越来越多的互联网内容是由AI生成的,如果这些内容被用来训练未来的模型,可能导致'模型崩溃'——即模型性能逐渐退化的恶性循环。

此外,研究还引发了对AI训练数据来源的广泛讨论。传统上,AI模型通过从互联网收集大量文本数据进行训练,但随着内容质量下降,这种方法的有效性受到质疑。一些公司已经开始探索替代数据源,如高质量的书籍、学术论文和专业文献,但这些数据源的获取成本较高,且可能存在偏见问题。
解决方案与行业建议
面对这一挑战,研究团队和行业专家提出了多项建议:
改进数据筛选算法:开发更智能的数据质量评估工具,能够自动识别和过滤低质量内容。
多元化数据来源:不仅依赖互联网数据,还应整合高质量的专业文献、书籍和其他经过验证的内容来源。
持续监控与评估:建立模型性能监控系统,及时发现并纠正因数据质量问题导致的性能下降。
行业合作与标准制定:制定数据质量标准和最佳实践指南,促进整个行业的协作与改进。
透明度与可解释性:提高AI训练过程的透明度,使研究人员和开发者能够理解和评估数据质量对模型性能的影响。
研究局限与未来方向
尽管这项研究提供了重要见解,但仍存在一些局限性。首先,'垃圾数据'的定义具有一定主观性,不同文化和社会背景可能导致对内容质量的不同判断。其次,研究主要基于推文数据,可能无法完全代表其他类型网络内容的影响。此外,长期效应研究仍需进一步探索,以了解持续暴露于低质量数据对AI模型的累积影响。
未来研究可以探索不同类型低质量数据的具体影响,开发更精确的数据质量评估方法,以及研究如何通过后处理技术减轻低质量数据的负面影响。此外,随着AI技术的不断发展,新的训练方法和架构可能会减轻数据质量对模型性能的影响。
结论
'LLM脑退化'现象揭示了AI训练数据质量对模型性能的深远影响。随着AI技术的快速发展,确保训练数据的高质量已成为行业面临的关键挑战。通过改进数据筛选方法、多元化数据来源、建立行业标准以及持续监控模型性能,我们可以减轻低质量数据的负面影响,推动AI技术向更健康、更可靠的方向发展。
这项研究不仅对AI开发者具有重要启示,也对整个数字生态系统提出了深刻思考。在信息爆炸的时代,无论是人类还是AI,都需要警惕'脑退化'的风险,主动选择高质量、有深度的内容,以维持和提升认知能力。随着AI技术的不断进步,我们有机会重新定义人与AI的关系,共同创造一个更加智能、更加可靠的数字未来。







