在人工智能发展历程中,每一次技术突破都伴随着范式的革新。当前,大语言模型(LLM)的文本能力逐渐触及天花板,行业普遍寻求新的突破口。10月30日,智源研究院正式发布的"悟界EMU3.5"多模态世界大模型,正是这一探索阶段的重要里程碑,它不仅解决了多模态领域长期存在的技术难题,更提出了AI发展的"第三种Scaling范式",为人工智能的未来指明了新方向。
多模态AI的核心挑战与突破
多模态AI面临的首要挑战,是如何建立一个能够统一处理文本、图像、视频等多种数据类型的"大一统"模型。传统做法往往是将不同功能的模型拼接起来,但这带来了融合难题——不同架构间的"语言"并不相通,导致信息传递不畅、理解不深入。
智源研究院从Emu3开始就选择了更具挑战性的"原生多模态"路线:采用统一的自回归(Autoregressive)架构。这一架构将文本、图像、视频等不同模态的数据全部打散成Token,由模型统一预测,理论上实现了"图像、文本、视频的大一统"。
然而,这一选择在过去一年里面临着一个致命的"原罪":推理效率太低。当模型生成图像时,需要一个Token一个Token地"吐"出来,如同"像素点打印",与Diffusion等模型的并行生成方式相比,速度慢了几个数量级,严重制约了其实用价值。
DiDA技术:效率革命的关键
为解决这一核心短板,EMU3.5团队创新性地提出了"DiDA(离散扩散自适应)"技术。这是一种高效的混合推理预测方法,允许自回归模型在推理时并行预测和生成大规模Token,从根本上改变了"一个点一个点画"的低效模式。
这一技术突破带来了显著的性能提升:在不牺牲性能的前提下,每张图片的推理速度提升了近20倍。智源研究院院长王仲远表示,这使得EMU3.5的自回归架构"首次使自回归模型的生成效率媲美顶尖的闭源扩散模型"。
这一工程上的关键突破,不仅补齐了原生多模态路线的核心短板,更证明了这一路径不仅在理论上可行,在实践中也具备了"可用性"和"可竞争性",为多模态AI的规模化发展奠定了基础。
"第三种Scaling范式"的提出与验证
在人工智能领域,"Scaling Law"(规模定律)是过去几年最重要的发现之一。它指的是,只要持续增加模型参数、训练数据和算力投入,模型的性能就会相应地可预期地提升。大模型的成功,正是建立在这一"力大砖飞"的信仰之上。
然而,在多模态领域,这条路径一直不甚明朗。由于技术路线不统一,行业并不确定多模态模型是否存在清晰的Scaling Law。
EMU3.5通过DiDA技术解决效率问题后,智源迅速开始了规模化的验证。从Emu3到EMU3.5的演变清晰地体现了这一规模化进程:
- 模型参数:从8B(80亿)跃升至34B(340亿),提升超过4倍
- 训练数据:累计的视频数据训练时长,从15年猛增到790年,跃升超过50倍
- 性能表现:随着规模扩大,模型能力获得了显著提升
基于这一实践,王仲远在发布会上提出了一个大胆的判断:EMU3.5开启了继"语言预训练"和"后训练及推理"之后的"第三个Scaling范式"。
"第三范式"的三大核心优势
智源研究院为这一"新范式"提供了三个关键理由:
架构的统一性:EMU的自回归架构能够大一统地处理各种模态的数据,为规模化提供了简洁的基础。不同于传统多模态系统需要为不同模态设计专门的子模型,EMU3.5通过统一的架构简化了复杂度。
设施的可复用性:这一架构可以"大规模复用已有的计算基础设施"。这意味着,所有为训练LLM而构建的昂贵智算集群,几乎都可以无缝迁移过来训练EMU模型,极大降低了Scaling的门槛和成本。
强化学习的引入:EMU3.5首次在多模态领域实现了大规模强化学习(RL)。强化学习(尤其是RLHF)是激发LLM高级能力、使其"听话"的关键步骤。如今,智源将这套在语言上被验证过的成熟方案,成功地应用到了更复杂的多模态模型上。
王仲远在现场强调,"Scaling范式"的意义在于"可预期"。而EMU3.5的潜力才刚刚开始释放——目前34B的参数规模,相比LLM动辄万亿的规模还很小;而790年的视频数据量,"只占全互联网公开视频数据不到1%"。这意味着,无论是在模型参数还是在数据维度上,这条路都还有着巨大的提升空间。
从"预测Token"到"预测状态":世界模型的本质转变
如果说,解决效率问题和开启规模化,回答了"怎么做"的问题,那么EMU3.5的另一大转变,则是在回答"学什么"的问题。
智源团队在发布会上反复强调"第一性原理"(First Principles)。王仲远以一个生动的例子说明:一个两岁小女孩通过刷短视频,观察视频里的人如何吃糖葫芦,然后在现实世界中模仿、尝试、失败、再尝试,最终自己学会了串糖葫芦。
他强调,人类的学习不是从文本开始的,而是从对这个世界、对物理规律的视觉观察开始的。这正是EMU3.5试图模拟的核心理念:AI不应只学习"语言",更应学习"世界"。
NSP:从数据续写到状态预测
基于这一理念,EMU3.5提出了核心范式的升级:从Emu3的"Next-Token Prediction"(预测下一个词元),升级为"Next-State Prediction (NSP)"(预测下一个状态)。
这一转变意味着模型的目标,不再是机械地"续写"数据(比如预测下一个像素或下一个词),而是要理解事物背后的因果和规律,预测世界在逻辑上的"下一个状态"。
王仲远以"桌边的咖啡"为例解释了这一区别:一个"视频生成模型",也许能预测出"杯子掉落、咖啡洒一地"的逼真画面;但一个"世界模型",首先应该理解"这个杯子放得很危险(状态)",并预测"它很可能会掉落(状态变化)"。更进一步,当接收到"拿起这杯咖啡"的指令时,这个模型会基于对物理常识(纸杯的力度、重心的位置)的理解,来规划"下一步的行动"。

Emu3.5能以精准可控的方式完成文图生成|图片来源:智源
多模态能力展示:从理解到行动
EMU3.5展现出的许多能力,都在印证这种从"理解"到"行动"的进化:
意图规划:当用户输入"如何做芹菜饺子"时,模型输出的不是零散的图片,而是一套图文并茂、步骤清晰的"行动指南",体现了对用户意图的深度理解。
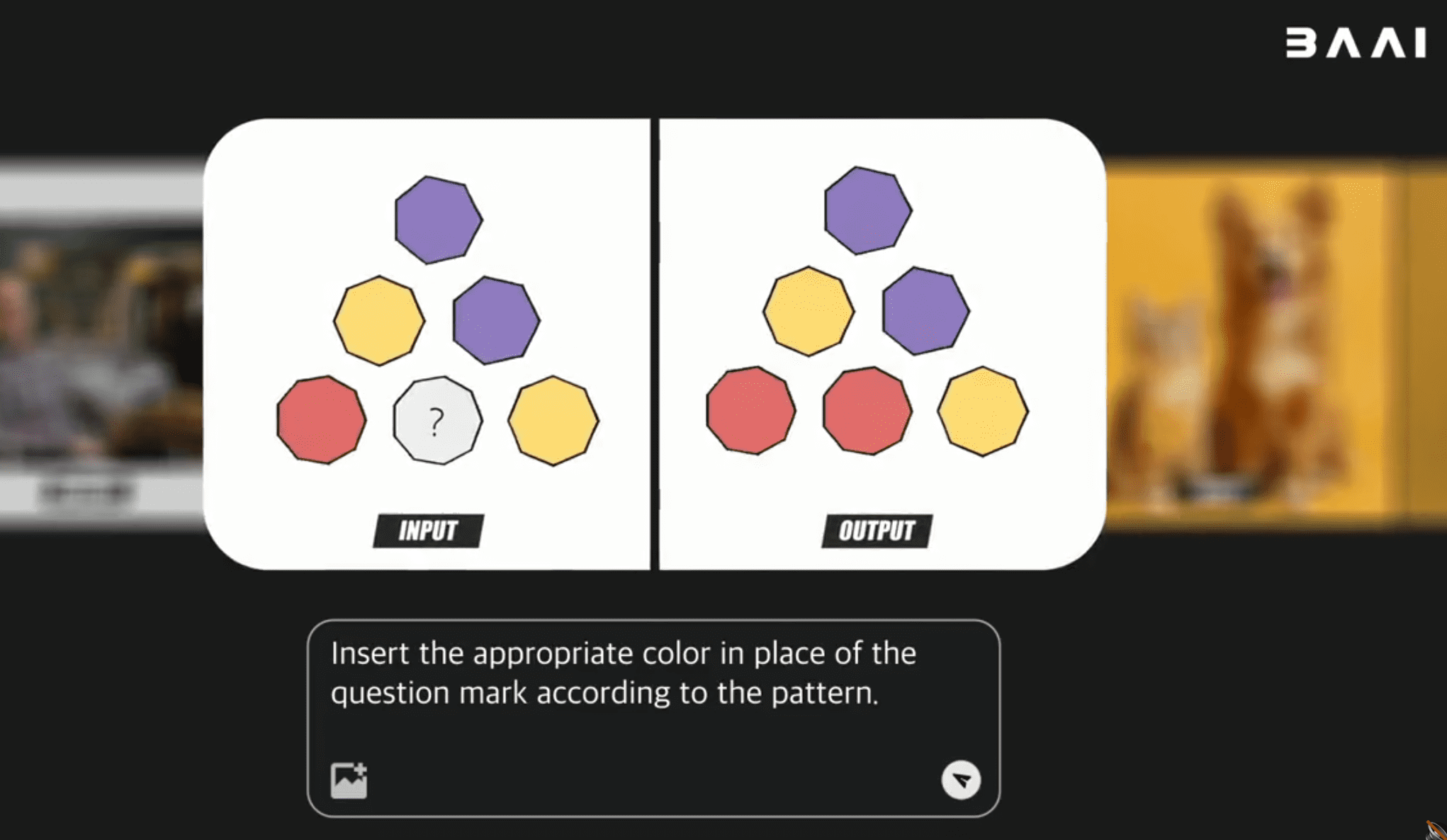
动态模拟与推理:在一个示例中,模型需要根据图案规律,在"?"处填上合适的颜色。这要求模型必须先"理解"图案的排布规则(一种逻辑状态),才能"生成"正确的红色方块(下一个状态)。
时空理解:模型可以将一张建筑的正面图,根据指令转换为"俯视图"。这背后是模型对物体三维空间关系的建模能力。
展现出基于视觉理解的图像生成能力图片来源:智源
世界模型与具身智能的紧密联系
这种"预测下一个状态"的能力,最终指向了人工智能的终极应用之一:具身智能(机器人)。
具身智能行业目前面临数据匮乏的瓶颈。而EMU3.5这样的世界模型,可以通过对物理世界的理解和模拟,为机器人生成海量、高质量、且多样化的"仿真训练数据"。

只需一句"叠衣服"的简单指令,Emu3.5便能自主规划、拆解任务,并精确生成机器人完成一整套复杂的折叠动作|图片来源:智源
在"叠衣服"的演示中,模型自主规划并生成了机器人完成复杂折叠动作的完整序列。王鑫龙博士提到,利用EMU3.5的世界模型能力,机器人在"没见过的场景"中执行任务,成功率可以"直接(从0%)到70%"。这表明,EMU3.5正在扮演的,是具身智能"大脑"的角色,即提供理解、规划和泛化的核心智能。
技术突破与未来展望
EMU3.5的发布,首先通过DiDA技术,解决了原生多模态自回归架构最致命的"效率"短板。以此为基础,它得以开启"多模态Scaling"的进程,通过堆叠数据和参数来提升能力,并验证了"第三种Scaling范式"的可能性。
这种规模化的最终目标,是实现一个更宏大的愿景:从"预测Token"转向"预测状态",让AI真正学习这个世界的物理规律和因果关系,为最终实现能够理解并与物理世界交互的通用人工智能,提供了一条坚实的路径。
目前智源已将技术细节在技术报告里披露,并计划在未来开源模型。这一举措或将加速多模态世界模型领域的发展,或许在多模态世界模型这条新赛道上,一个来自中国的"新范式"已经登场,将为全球AI发展带来新的活力与可能性。

Emu3.5的多模态指导能力:输入"如何做芹菜饺子",模型输出有步骤的图文指导图片来源:智源