在搜索引擎领域,一场静默的革命正在悄然发生。自去年Google AI Overviews灾难性推出以来,公众开始意识到AI驱动的搜索结果与传统数十年来的链接列表搜索有着天壤之别。最新研究为这一差异提供了量化证据,揭示了一个令人惊讶的现象:AI搜索引擎更倾向于引用那些在传统搜索结果中排名靠后的网站,甚至是一些在Google前100名链接中完全不会出现的来源。
研究发现:AI搜索的'深网'偏好
德国鲁尔大学与马克斯·普朗克软件系统研究所的研究人员在题为《生成式AI时代的网络搜索特征》的预印本论文中,对传统Google搜索结果与AI Overviews以及Gemini-2.5-Flash进行了系统比较。研究团队还考察了GPT-4o的网络搜索模式,以及独立的"GPT-4o带搜索工具"——这种工具仅在大型语言模型(LLM)认为需要从预训练数据之外获取信息时才会诉诸网络搜索。
研究人员从多个来源收集测试查询,包括提交给ChatGPT的特定问题(WildChat数据集)、AllSide网站上列出的普遍政治话题,以及亚马逊100个最常搜索产品列表中的产品。
网站排名的显著差异
总体而言,生成式搜索工具引用的来源往往比传统搜索前10名中的网站受欢迎程度更低。根据Tranco域名跟踪器的测量,AI引擎引用的来源比传统Google搜索链接更可能落在Tranco追踪的前1000名和前100万名域名之外。特别是Gemini搜索表现出引用不受欢迎域名的倾向,在所有结果中,中位数来源甚至不在Tranco前1000名之内。
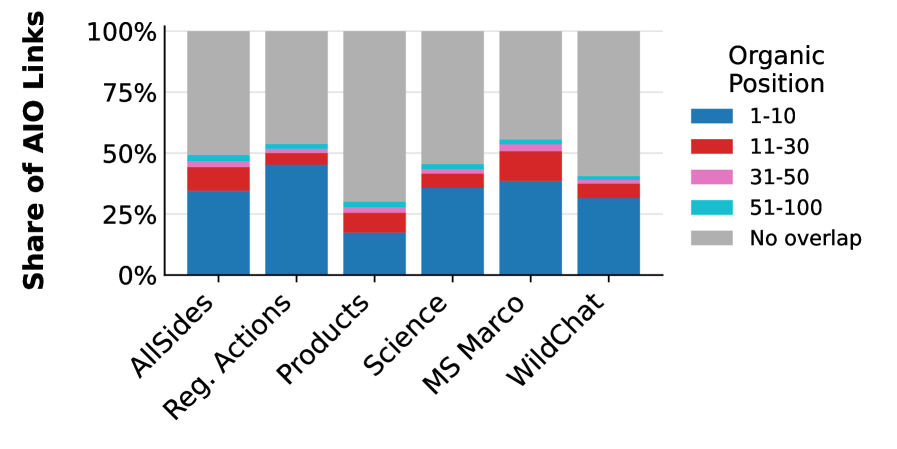
图:多数被AI Overview引用的来源并未出现在相同查询的Google前10名链接结果中
研究数据令人瞩目:53%的Google AI Overviews引用的来源并未出现在相同查询的Google前10名链接中,40%的来源甚至没有进入前100名。这种差异表明,AI搜索引擎正在探索传统搜索引擎忽视的信息空间。
优劣对比:AI搜索与传统搜索的博弈
这些差异并不意味着AI生成的搜索结果必然"更差"。研究发现,基于GPT的搜索更倾向于引用企业和百科全书等来源,而几乎从不引用社交媒体网站。
概念覆盖的相似性
斯坦福大学的一个基于LLM的分析工具发现,AI驱动的搜索结果往往与传统的前10名链接覆盖相似数量的可识别"概念",这表明结果在细节、多样性和新颖性方面处于相似水平。
然而,研究人员也指出:"生成式引擎倾向于压缩信息,有时会省略传统搜索保留的次要或模糊方面。