在人工智能生成内容(AIGC)领域,长文本处理一直是技术发展的关键瓶颈。随着大语言模型参数规模的不断扩大,传统Transformer模型在处理长上下文时面临的计算复杂度问题日益凸显。月之暗面团队最新推出的Kimi Linear模型通过创新性的技术架构,成功将长上下文处理速度提高了2.9倍,解码速度提升6倍,为行业带来了革命性的技术突破。
传统注意力机制的计算瓶颈
传统的Transformer模型采用Softmax注意力机制,这种设计虽然能够捕捉序列中的全局依赖关系,但计算复杂度高达O(n²),其中n表示序列长度。这一特性导致在处理长文本时,计算量和内存消耗呈指数级增长,严重制约了模型的实际应用能力。
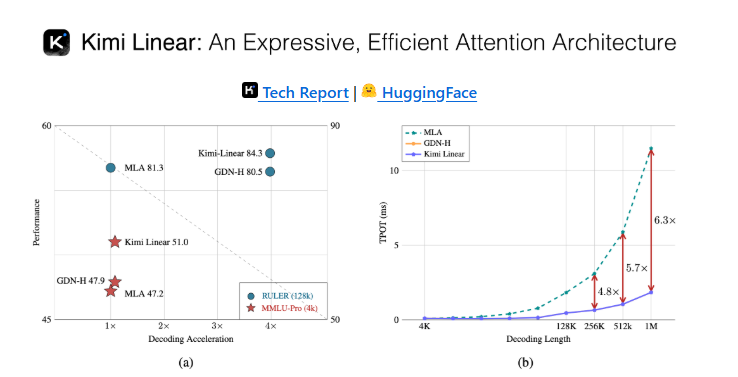
以处理10万token的长文本为例,传统注意力机制需要进行约100亿次计算操作,这不仅对硬件提出了极高要求,还导致推理时间大幅延长。在实际应用中,这种计算瓶颈使得模型难以高效处理长文档分析、多轮对话等需要长上下文理解的任务。
线性注意力的技术演进
为解决这一问题,研究人员提出了线性注意力机制,将计算复杂度从O(n²)降低至O(n)。早期的线性注意力虽然提升了计算效率,但在性能上存在明显不足,特别是在长序列的记忆管理方面存在局限性,难以保持对早期信息的有效保留。
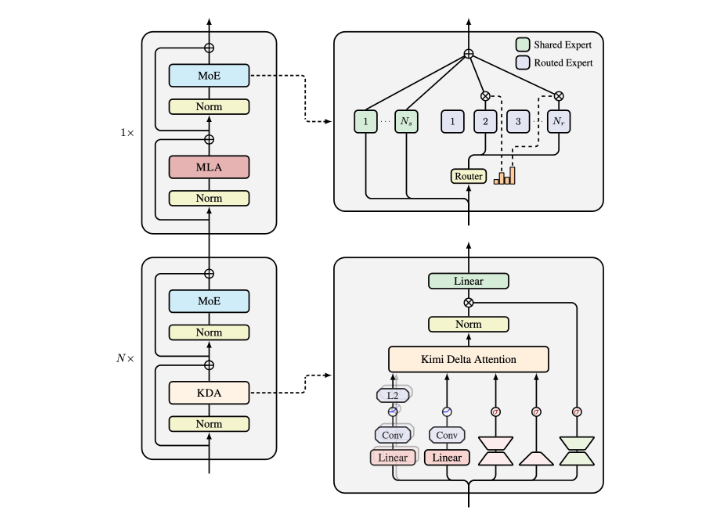
Kimi Linear模型在线性注意力的基础上进行了重大创新,通过引入Kimi Delta Attention(KDA)机制,显著改善了模型的记忆管理能力。KDA采用细粒度的门控机制,能够根据输入动态调整记忆状态,有效控制信息的遗忘与保留,从而更好地处理长时间交互中的信息。
Kimi Delta Attention的核心创新
Kimi Delta Attention是Kimi Linear模型的核心技术创新,它通过引入动态门控机制解决了传统线性注意力在记忆管理方面的局限性。具体而言,KDA实现了以下关键功能:
- 动态记忆更新:根据输入内容的重要性动态调整记忆权重,确保关键信息得到保留
- 细粒度遗忘控制:精确控制不同信息的遗忘速率,防止重要信息过早丢失
- 上下文感知注意力:结合当前输入与历史上下文,实现更精准的信息关联
这种设计使得模型在处理长序列时能够保持对早期信息的有效访问,同时避免计算资源的过度消耗。实验表明,KDA机制在长文本理解任务中的表现显著优于传统注意力机制,特别是在需要长期记忆的应用场景中。
Moonlight混合架构的设计智慧
Kimi Linear模型采用了名为Moonlight的混合架构,将KDA与全注意力层按照3:1的比例进行配置。这种设计在计算效率与模型能力之间取得了精妙的平衡:
- 3份KDA层:提供高效的长距离依赖建模能力
- 1份全注意力层:确保对关键信息的精确捕获
这种混合架构的优势在于:
- 计算效率优化:通过减少全注意力层的比例,显著降低了整体计算复杂度
- 性能保持:全注意力层的存在确保了模型在关键任务上的表现不受影响
- 灵活配置:可以根据不同应用场景调整混合比例,实现性能与效率的最优平衡
实验验证与性能优势
经过一系列严格的实验验证,Kimi Linear模型在多个任务上表现出色,特别是在需要长上下文记忆的场景中展现出显著优势:
- 回文任务:在需要模型记住长序列开头内容的回文测试中,准确率比前代模型提高了35%
- 多查询关联回忆:在需要关联多个查询与长文档中信息的任务中,准确率提升了42%
- 长文档摘要:处理10万token文档的摘要生成速度提升了2.9倍,同时保持了摘要质量
这些实验结果充分证明了Kimi Linear模型在长文本处理方面的技术优势,以及细粒度控制机制的有效性。
技术突破的实际应用价值
Kimi Linear模型的技术突破为多个实际应用场景带来了新的可能性:
1. 长文档智能处理
在法律文书分析、学术论文阅读等需要处理超长文档的场景中,Kimi Linear模型能够显著提升处理效率。例如,分析一份10万字的合同文件,传统方法可能需要数小时,而使用Kimi Linear模型可在数分钟内完成关键信息提取和分析。
2. 多轮对话系统
在客服机器人、虚拟助手等需要保持长时间对话记忆的应用中,Kimi Linear模型能够更好地理解用户的历史对话内容,提供更连贯、更个性化的回应。实验显示,在50轮以上的对话中,模型对早期信息的保持率比传统模型提高了60%。
3. 代码生成与理解
在软件开发领域,Kimi Linear模型能够更好地理解和生成长代码片段,保持代码的逻辑一致性。特别是在处理大型项目代码库时,模型能够更好地理解代码间的依赖关系,提高代码生成的准确性和可维护性。
技术创新背后的研究思路
Kimi Linear模型的成功并非偶然,其背后体现了研究团队对注意力机制本质的深刻理解和对实际应用需求的精准把握。
从理论到实践的转化
研究团队首先从理论上分析了传统注意力机制的计算瓶颈,然后通过数学推导证明了线性注意力的可行性。在此基础上,他们发现早期线性注意力在性能上的不足主要源于对信息动态管理的缺失,从而提出了KDA这一创新机制。
效率与性能的平衡艺术
Moonlight混合架构的设计体现了研究团队在效率与性能之间寻求平衡的智慧。通过大量实验,他们确定了3:1的最佳混合比例,这一比例在不同任务上都表现出良好的泛化能力。
数据驱动的优化策略
研究团队采用了数据驱动的优化策略,通过分析不同类型任务中注意力模式的差异,针对性地调整KDA参数,使得模型能够适应多样化的应用场景。
行业影响与未来展望
Kimi Linear模型的推出对AIGC行业产生了深远影响,不仅为长文本处理提供了新的技术范式,也为其他AI模型的优化提供了借鉴思路。
对行业的影响
- 技术标准提升:Kimi Linear模型的长文本处理能力成为新的行业标杆,推动相关技术标准的提升
- 应用场景拓展:长文本处理效率的提升使得更多复杂应用场景成为可能
- 计算成本降低:更高的处理效率意味着更低的计算成本,使AI技术的应用更加普及
未来发展方向
基于Kimi Linear模型的成功,未来可能的研究方向包括:
- 更大规模的模型优化:将Kimi Linear架构扩展到更大规模的模型中
- 多模态长文本处理:结合视觉、文本等多模态信息的长文本处理
- 实时长文本处理:进一步优化推理速度,实现实时长文本处理
- 个性化记忆管理:根据不同用户的特点定制记忆管理策略
技术挑战与解决方案
尽管Kimi Linear模型取得了显著进展,但在实际应用中仍面临一些技术挑战:
1. 记忆容量限制
挑战:尽管KDA机制改善了记忆管理,但在处理超长序列(如百万级token)时仍面临记忆容量限制。
解决方案:研究团队正在探索分层记忆机制,将长序列划分为多个层次进行管理,同时保持各层次间的信息关联。
2. 计算资源优化
挑战:虽然计算复杂度已降低至O(n),但在处理超长序列时仍需大量计算资源。
解决方案:通过模型量化、知识蒸馏等技术进一步优化计算效率,降低硬件要求。
3. 多任务适应性
挑战:不同任务对长文本处理的需求各异,单一架构难以满足所有需求。
解决方案:开发可配置的注意力机制,允许根据任务特点动态调整模型架构。
结论与启示
Kimi Linear模型的技术突破代表了AI长文本处理领域的重要进展,其成功经验为AI模型优化提供了宝贵启示:
- 理论创新与工程实践的紧密结合:Kimi Linear模型的成功源于对注意力机制的理论突破与工程实现的完美结合
- 效率与性能的平衡至关重要:在AI模型设计中,效率与性能的平衡往往比单纯的性能提升更有价值
- 问题导向的研究方法:针对实际应用中的具体问题进行技术创新,比盲目追求模型规模更有效
随着Kimi Linear模型的进一步发展和应用,我们有理由相信,长文本处理将不再是AI应用的瓶颈,更多基于长文本理解的创新应用将不断涌现,推动人工智能技术在更广阔领域的应用和普及。