自定义检索器:提升RAG应用性能的关键
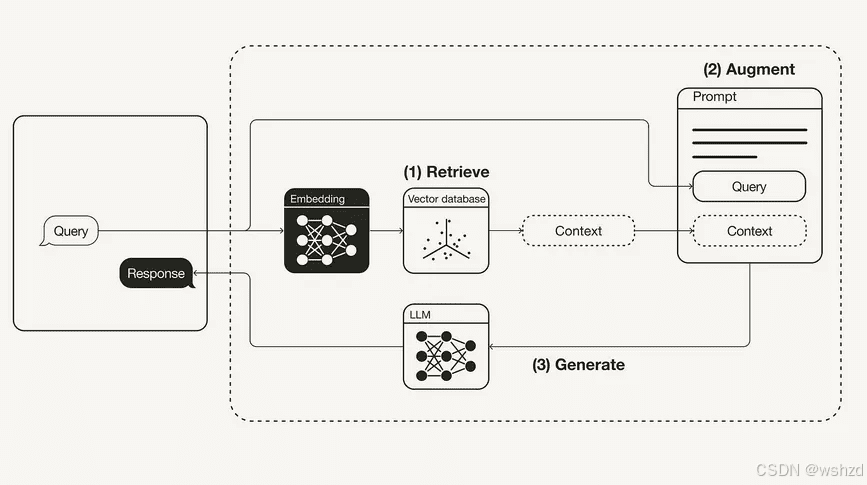
在检索增强生成(RAG)管道中,检索器扮演着至关重要的角色。它负责从海量数据中精准提取与用户查询相关的上下文信息,直接影响着后续生成器所产生响应的质量和准确性。本文将深入探讨如何使用LlamaIndex构建一个结合关键词和向量搜索的自定义检索器,并结合Gemini大模型实现多文档聊天,从而显著提升RAG应用的性能。
一、RAG管道中的检索器与生成器
RAG管道由检索器和生成器两个核心组件构成。检索器负责根据用户查询,从知识库中检索出相关的文档或文本片段,为生成器提供上下文信息。生成器则利用这些上下文信息,结合自身的语言模型能力,生成最终的响应。
检索器的性能直接影响着RAG管道的整体效果。一个优秀的检索器能够准确、高效地找到与查询最相关的文档,从而为生成器提供高质量的上下文,最终生成更准确、更具信息量的响应。
二、构建混合搜索自定义检索器
为了构建一个高效的自定义检索器,我们需要选择合适的检索方法。本文将重点介绍一种混合搜索方法,它结合了关键词搜索和向量搜索的优势,从而提高检索的准确性和召回率。
- 关键词搜索:基于关键词匹配的检索方法,通过查找包含用户查询关键词的文档来获取相关信息。关键词搜索的优点是速度快、效率高,但缺点是容易受到关键词歧义和语义差异的影响。
- 向量搜索:基于语义相似度的检索方法,通过将用户查询和文档都转换为向量表示,然后计算它们之间的相似度来获取相关信息。向量搜索的优点是可以理解语义信息,从而找到与查询在语义上相关的文档,即使文档中不包含查询关键词。但是,向量搜索的缺点是计算复杂度高,速度较慢。
2.1 混合搜索的两种模式:AND 和 OR
在实现混合搜索时,我们需要决定如何将关键词搜索和向量搜索的结果进行整合。LlamaIndex 提供了两种模式:AND 和 OR。
- AND 模式:只返回同时满足关键词搜索和向量搜索结果的文档。这种模式的优点是准确性高,但缺点是召回率较低,可能会遗漏一些相关文档。
- OR 模式:返回满足关键词搜索或向量搜索结果的文档。这种模式的优点是召回率高,但缺点是准确性较低,可能会返回一些不相关的文档。
在选择 AND 或 OR 模式时,我们需要根据具体的应用场景来权衡准确性和召回率。例如,对于需要高度准确性的应用,如金融领域的风险评估,可以选择 AND 模式。对于需要高召回率的应用,如医疗领域的疾病诊断,可以选择 OR 模式。
三、LlamaIndex 实现自定义检索器
接下来,我们将使用 LlamaIndex 构建一个结合关键词和向量搜索的混合搜索自定义检索器。
3.1 环境准备
首先,我们需要安装必要的 Python 包:
!pip install llama-index3.2 配置 Google API 密钥
本文使用 Google Gemini 作为大型语言模型(LLM)和嵌入模型。你需要申请一个 Google API 密钥,并在代码中进行配置。
from getpass import getpass
google_api_key = getpass("Please enter your Google API key: ")3.3 数据加载与节点创建
使用 LlamaIndex 的 SimpleDirectoryReader 加载数据。你需要创建一个文件夹,并将需要检索的文档(如 PDF 文件)放入该文件夹中。
from llama_index.core import SimpleDirectoryReader
documents = SimpleDirectoryReader("data").load_data()加载文档后,LlamaIndex 会将文档拆分成更小的文本块,称为节点。节点是 LlamaIndex 框架中定义的数据架构,方便后续的检索和生成。
3.4 设置嵌入模型和 LLM
本文使用 Gemini 作为嵌入模型和 LLM。
from llama_index.embeddings.gemini import GeminiEmbedding
embed_model = GeminiEmbedding(api_key=google_api_key)3.5 定义存储上下文
LlamaIndex 使用存储上下文来存储文档的向量嵌入。
from llama_index.core import StorageContext3.6 创建向量索引和关键词索引
为了实现混合搜索,我们需要创建两个索引:一个用于向量搜索的向量索引,另一个用于关键词搜索的关键词索引。
from llama_index.core import SimpleKeywordTableIndex, VectorStoreIndex
keyword_index = SimpleKeywordTableIndex.from_documents(documents)
vector_index = VectorStoreIndex.from_documents(documents, embed_model=embed_model)3.7 构建自定义检索器
自定义检索器需要结合向量索引检索器和关键词索引检索器。通过指定模式(AND 或 OR)来实现这两种检索器的组合。
from llama_index.core import QueryBundle
class HybridRetriever:
def __init__(self, vector_retriever, keyword_retriever, mode="AND"):
self.vector_retriever = vector_retriever
self.keyword_retriever = keyword_retriever
self.mode = mode
def retrieve(self, query_bundle: QueryBundle):
vector_results = self.vector_retriever.retrieve(query_bundle)
keyword_results = self.keyword_retriever.retrieve(query_bundle)
vector_ids = {r.node.node_id for r in vector_results}
keyword_ids = {r.node.node_id for r in keyword_results}
if self.mode == "AND":
node_ids = vector_ids.intersection(keyword_ids)
elif self.mode == "OR":
node_ids = vector_ids.union(keyword_ids)
else:
raise ValueError(f"Invalid mode: {self.mode}")
results = []
all_nodes = {}
for r in vector_results + keyword_results:
all_nodes[r.node.node_id] = r.node
for node_id in node_ids:
node = all_nodes[node_id]
results.append(node)
return results3.8 定义检索器和查询引擎
from llama_index.core import get_response_synthesizer
vector_retriever = vector_index.as_retriever()
keyword_retriever = keyword_index.as_retriever()
hybrid_retriever = HybridRetriever(vector_retriever, keyword_retriever, mode="OR")
response_synthesizer = get_response_synthesizer()3.9 运行自定义检索查询引擎
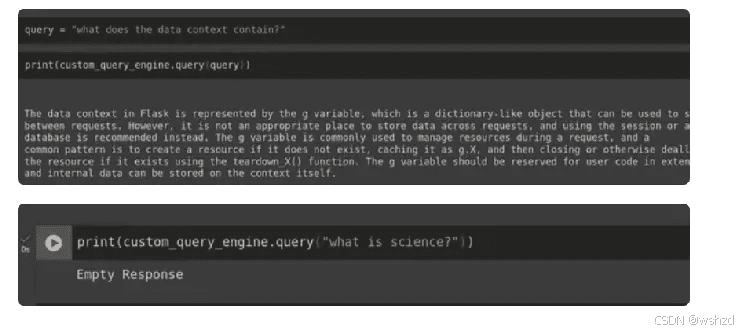
query = "what does the data context contain?"
results = hybrid_retriever.retrieve(QueryBundle(query_str=query))
for node in results:
print(node.get_content())四、高级检索器技术
除了混合搜索,还有一些高级检索器技术可以进一步提高 RAG 应用的性能,例如:
- Rerank:对检索结果进行重新排序,将更相关的文档排在前面。
- HyDE (Hypothetical Document Embeddings):生成一个假设文档,然后使用该文档进行检索,从而提高检索的准确性。
五、总结
本文介绍了如何使用 LlamaIndex 构建一个结合关键词和向量搜索的自定义检索器,并结合 Gemini 大模型实现多文档聊天。通过选择合适的检索方法和模式,我们可以显著提高 RAG 应用的性能,减少幻觉,并生成更准确、更具信息量的响应。同时,我们还探讨了一些高级检索器技术,可以进一步提高 RAG 应用的性能。
构建自定义检索器是提升 RAG 应用性能的关键步骤。通过深入了解 RAG 管道中的检索器和生成器组件,以及各种检索技术,我们可以构建出更加高效、准确的 RAG 应用,从而更好地满足用户的需求。