
在人工智能领域,多模态大模型正成为连接不同感知维度的关键桥梁。NVIDIA最新推出的OmniVinci模型,以其独特的技术架构和卓越的性能表现,重新定义了全模态AI的能力边界。本文将深入剖析这一革命性模型的技术原理、创新架构及其广泛的应用前景,揭示其如何通过跨模态语义对齐和时间感知技术,实现视觉、听觉、语言和推理的深度融合。
全模态AI的新纪元:OmniVinci的诞生
OmniVinci作为NVIDIA推出的全模态大语言模型,代表了当前多模态AI技术的最高水平。与传统的单一模态模型不同,OmniVinci能够同时处理视觉(图像、视频)、音频和文本信息,实现跨模态的联合理解。这一突破性进展源于NVIDIA在深度学习和多模态融合领域多年的技术积累,以及对全模态语义对齐问题的创新解决方案。
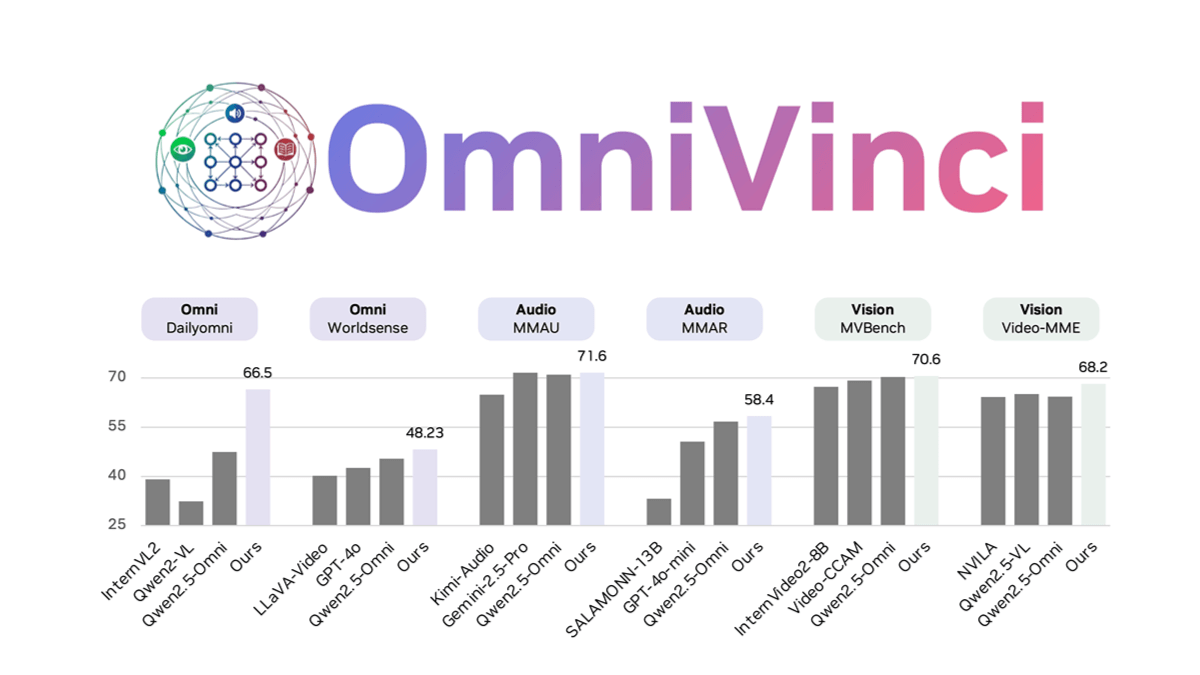
OmniVinci的核心优势在于其独特的训练策略和技术创新。模型仅需0.2万亿tokens的训练量,远低于同类产品的1.2T标准,却能在Dailyomni等基准测试中超越Qwen2.5等先进模型,特别是在音画同步理解任务上表现尤为突出。这种高效训练策略不仅降低了开发成本,也为全模态AI的普及应用提供了可能。
技术创新:OmniVinci的核心架构解析
OmniAlignNet:跨模态语义对齐的革命
OmniVinci最核心的技术突破在于其独创的OmniAlignNet模块。传统多模态模型常常面临不同模态之间语义脱节的困境,视觉信息与音频内容难以形成统一的理解框架。OmniAlignNet通过加强视觉和音频嵌入在共享全模态潜在空间中的对齐,彻底解决了这一难题。
该模块采用了一种创新的注意力机制,能够在训练过程中自动学习不同模态之间的对应关系。例如,在视频分析任务中,OmniAlignNet能够将人物的动作与相应的语音内容精确关联,形成完整的语义理解。这种跨模态对齐能力使得OmniVinci在需要综合多种感官信息的场景中表现出色。
时间感知的双重创新:TEG与CRTE
多模态数据的时间同步是长期困扰AI领域的难题。OmniVinci通过两项创新技术——Temporal Embedding Grouping(TEG)和Constrained Rotary Time Embedding(CRTE)——实现了对时间信息的精准处理。
TEG技术专门用于捕获视觉和音频信号之间的相对时间对齐。通过将时间嵌入分组处理,TEG能够有效识别不同模态事件之间的时序关系,例如视频中人物的口型与声音的同步。这一技术对于视频分析、会议记录等需要精确时间同步的应用场景尤为重要。
CRTE则通过维度敏感的旋转编码,实现对绝对时间信息的精准标记。与传统的位置编码不同,CRTE考虑了不同模态数据的时间特性,为视觉和音频信号提供定制化的时间表示。这种创新的时间编码方式使得OmniVinci在处理具有明确时间顺序的多模态数据时表现出色。
高效训练策略:从数据到算法的全面优化
OmniVinci的训练过程体现了NVIDIA在AI效率优化方面的深厚积累。模型通过精心设计的数据合成和优化流程,生成了2400万条单模态和全模态对话样本,其中15%为显式全模态合成数据。这种大规模、高质量的数据集为模型提供了丰富的多模态学习样本。
在训练过程中,OmniVinci采用多模型协同纠错机制,有效消除了"模态幻觉"问题——即模型错误地将不存在的信息添加到某一模态中。通过这种方式,模型能够生成更加准确和一致的多模态输出。
值得一提的是,OmniVinci在GRPO(Group Relative Policy Optimization)强化学习框架下进行训练,通过视听结合的方式提升模型的收敛速度和性能表现。这种创新的训练策略使得模型在多模态任务中表现出色,同时保持了较高的训练效率。
应用场景:OmniVinci的多元价值实现
视频内容分析:从像素到语义的跨越
OmniVinci在视频内容分析领域展现出强大的能力。模型能够详细描述视频中的人物动作、对话内容以及场景细节,适用于视频解说、体育比赛分析、新闻报道等多种场景。与传统的视频分析工具相比,OmniVinci不仅能识别视觉元素,还能理解音频内容,并将两者有机结合,提供更加丰富和准确的视频内容理解。
例如,在体育比赛分析中,OmniVinci可以同时追踪运动员的动作、解说员的评论以及观众的反应,形成全方位的比赛理解。这种多模态分析能力为体育内容的深度解读提供了新的可能性。
医疗AI:影像与语音的智能融合
在医疗领域,OmniVinci展现出巨大的应用潜力。模型能够结合医生的口头解释和医学影像(如CT、MRI等),准确回答高难度问题,辅助医生进行诊断和治疗方案的制定。这种多模态理解能力能够显著提升医疗效率和准确性,特别是在远程医疗和医学教育方面具有重要价值。

OmniVinci在医疗影像分析方面的优势在于,它不仅能够识别图像中的异常,还能理解医生对病例的口头描述,将两者结合起来形成完整的诊断思路。这种能力对于复杂病例的分析和教学特别有价值。
机器人导航:语音与视觉的协同感知
在机器人领域,OmniVinci通过语音指令控制机器人行动,实现更高效的人机交互。模型能够理解自然语言指令,并结合视觉环境信息,为机器人提供精准的行动指导。这一能力适用于家庭服务机器人、工业机器人等多种场景,显著提升了机器人的智能性和灵活性。
例如,在家庭服务场景中,用户可以通过自然语言指令"请帮我把桌子上的红色杯子拿到厨房",OmniVinci能够理解这一指令,并指导机器人识别红色杯子、规划移动路径,最终完成任务。这种直观的人机交互方式大大降低了机器人的使用门槛。
工业检测:多模态质量控制的革新
在工业生产中,OmniVinci可以结合视觉和音频信息,用于半导体器件检测、生产线监控等场景。传统工业检测往往依赖单一视觉或听觉信息,而OmniVinci能够综合利用多种模态数据,显著提升检测精度和效率,降低人工成本。
例如,在半导体制造过程中,OmniVinci可以同时分析芯片的视觉图像和设备运行的声音特征,及时发现异常情况。这种多模态检测方式能够发现单一模态难以识别的问题,提高产品质量控制的可靠性。
开源生态:推动全模态AI的普及发展
NVIDIA通过开源OmniVinci的代码、数据和网页演示,为全模态AI研究社区提供了宝贵的资源。研究人员和开发者可以基于这一平台进行二次开发和改进,加速全模态AI技术的创新和应用。
OmniVinci的开源不仅包括模型本身,还包括训练数据集和评估工具,为全模态AI研究提供了完整的解决方案。这种开放策略有助于构建更加多元和包容的AI研究生态,推动全模态技术的民主化发展。
未来展望:全模态AI的发展趋势
OmniVinci的出现标志着全模态AI技术进入新的发展阶段。未来,我们可以预见以下几个发展趋势:
模态融合的深度化:未来的全模态模型将实现更深层次的模态融合,不仅能够处理现有的视觉、听觉和语言信息,还将整合触觉、嗅觉等更多感知维度,构建更加完整的人工智能感知系统。
实时性能的优化:随着边缘计算技术的发展,全模态模型将更加注重实时性能优化,使其能够在移动设备和嵌入式系统中高效运行,拓展应用场景。
领域专业化:针对特定领域的全模态模型将不断涌现,如医疗、教育、娱乐等,通过专业化提升在特定场景下的表现和实用性。
人机交互的自然化:全模态AI将推动人机交互方式向更加自然、直观的方向发展,减少用户的学习成本,提升使用体验。
结语:OmniVinci引领全模态AI新方向
OmniVinci作为NVIDIA推出的全模态大语言模型,通过其创新的技术架构和卓越的性能表现,为多模态AI的发展指明了新方向。从跨模态语义对齐到时间感知技术,从高效训练策略到多元应用场景,OmniVinci展示了全模态AI的巨大潜力。
随着技术的不断进步和应用场景的持续拓展,全模态AI将在更多领域发挥重要作用,改变人们的生活和工作方式。OmniVinci的开源策略也为这一技术的普及和发展提供了有力支持,有望加速全模态AI的创新迭代和应用落地。
未来,我们期待看到更多基于OmniVinci的创新应用,以及全模态AI技术的进一步突破,为人工智能的发展开辟更加广阔的空间。







