
人工智能领域的最新研究揭示了一个令人担忧的现象:就像人类过度消费低质量内容会导致认知能力下降一样,大语言模型(LLM)如果使用'垃圾数据'进行训练,也会出现类似的'脑萎缩'效应。这一发现对当前AI开发的数据收集策略提出了严峻挑战,引发行业对训练数据质量控制的重新思考。
研究背景:从人类'脑萎缩'到AI'认知衰退'
德州农工大学、德克萨斯大学和普渡大学的研究团队在最近发表的一篇预印本论文中,提出了'LLM脑萎缩假说'。这一概念受到现有研究的启发——研究表明,人类大量消费'琐碎且缺乏挑战性的在线内容'会导致注意力、记忆和社会认知能力出现问题。
'脑萎缩'在人类中是'网络成瘾的后果',研究人员将这一概念迁移到AI领域,提出了'持续使用垃圾网络文本进行预训练会导致LLM出现持久的认知衰退'的假设。
数据质量困境:如何定义'垃圾数据'与'高质量内容'
确定什么构成'垃圾网络文本',什么又算'高质量内容',绝非简单或完全客观的过程。研究人员采用了多种指标,从HuggingFace包含1亿条推文的语料库中,区分出'垃圾数据集'和'控制数据集'。
基于'垃圾推文应能以琐碎方式最大化用户参与度'的理念,研究人员创建了一个'垃圾'数据集,收集了高互动数据(点赞、转发、回复和引用)且长度较短的推文,认为'更受欢迎但更短的推文将被视为垃圾数据'。
对于第二个'垃圾'指标,研究人员借鉴市场营销研究,定义了推文本身的'语义质量'。使用复杂的GPT-4o提示,他们提取出专注于'表面话题(如阴谋论、夸大声明、无根据断言或表面生活方式内容)'或采用'吸引眼球风格(如使用点击诱饵语言的耸人听闻标题或过度触发词)'的推文。
研究人员对一小部分基于LLM的分类进行了随机抽样,与三名研究生的评估进行对比,匹配率达到76%。
实验设计:不同数据比例对LLM性能的影响
研究人员使用这两种部分重叠的'垃圾'数据集,对四个LLM进行了不同比例'垃圾'和'控制'数据的预训练。随后,这些经过不同训练的模型接受了多项基准测试,以测量其推理能力、长上下文记忆、遵守伦理规范的程度以及'个性风格'。
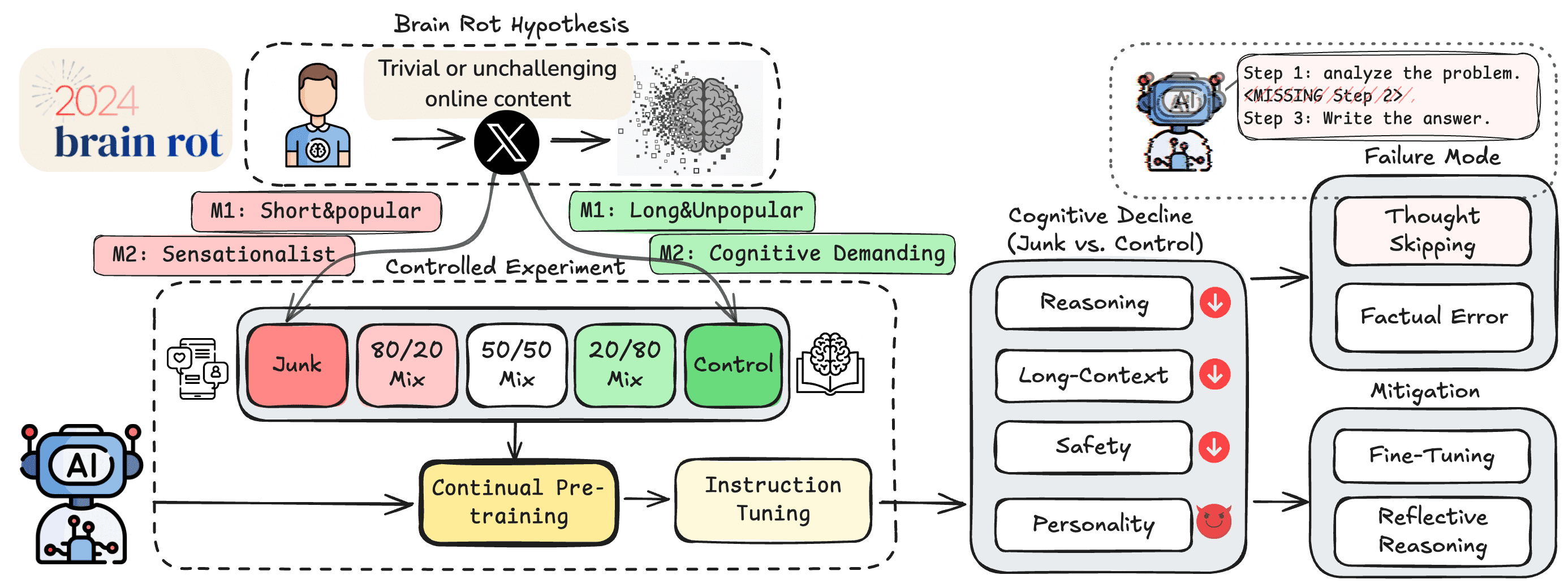
测试结果显示,在训练集中增加更多'垃圾数据'对模型的推理能力和长上下文记忆基准测试产生了统计学上的显著影响。然而,在其他基准测试上的效果则更为复杂。例如,对于Llama 8B模型,使用50/50的'垃圾'与控制数据混合,在某些基准测试(伦理规范、高开放性、低神经质和马基雅维利主义)上生成的得分比完全'垃圾'或完全'控制'的训练数据集都要好。
研究发现与行业警示
基于这些结果,研究人员警告称'严重依赖互联网数据会导致LLM预训练陷入内容污染的陷阱'。他们呼吁'重新审视当前从互联网收集数据和持续预训练的做法',并警告'未来模型需要仔细策划和质量控制,以防止累积性损害'。
这一发现尤为重要,因为随着互联网上AI生成内容的不断增加,这些内容如果用于训练未来模型,可能会导致'模型崩溃'。研究人员提出的问题直指行业核心:我们是否应该继续依赖日益被AI内容污染的互联网作为主要训练数据源?
数据质量与AI未来的关系
这项研究揭示了AI开发中的一个根本性矛盾:互联网作为最大的数据源,其质量却在不断下降。一方面,AI模型需要海量数据进行训练;另一方面,这些数据中越来越多的部分可能是低质量的AI生成内容。
研究人员提出的解决方案包括:
- 更严格的数据质量控制流程
- 开发更有效的方法来识别和过滤低质量内容
- 探索除互联网数据外的其他高质量数据来源
- 重新评估持续预训练的必要性和方法
行业影响与未来展望
这一研究对AI行业的影响将是深远的。如果数据质量确实对模型性能有如此显著的影响,那么:
- AI公司可能需要重新评估其数据收集策略
- 数据标注和验证的重要性将大幅提升
- 可能会出现专门提供高质量训练数据的新市场
- 模型评估标准可能需要纳入数据质量指标
同时,这也提出了一个更广泛的问题:在AI内容泛滥的时代,我们如何确保训练数据的质量和多样性?这不仅是一个技术问题,也是一个社会和伦理问题。
结论:质量胜于数量的AI训练新范式
这项研究清晰地表明,在AI训练中,数据的质量可能比数量更为重要。随着AI技术的不断发展,我们需要建立更严格的数据质量控制机制,以确保AI模型能够持续学习和进步,而不是在'垃圾数据'的'营养'下出现'认知衰退'。
未来,AI行业可能需要从'越多越好'的数据收集模式,转向'质量优先'的新范式。这不仅关系到AI模型的性能,也关系到这些模型在未来社会中能够发挥的积极作用。正如研究人员所强调的,'仔细策划和质量控制对于防止未来模型中的累积性损害至关重要'。
在AI技术日益融入我们生活的今天,确保这些系统基于高质量、多样化的数据进行学习,不仅是技术挑战,也是对我们作为技术开发者的责任和远见的考验。








