
在人工智能技术飞速发展的今天,医疗领域正经历着前所未有的变革。谷歌最新推出的视频生成AI模型Veo-3在手术视频生成方面展现出令人惊叹的能力,然而最新研究揭示了一个令人警醒的事实:尽管Veo-3能够生成视觉上极为逼真的手术视频,但在医学逻辑理解方面却存在严重不足。这一发现不仅挑战了我们对AI医疗能力的认知,也为未来AI在医疗领域的应用敲响了警钟。
研究背景:Veo-3的视觉突破与医学应用潜力
谷歌的Veo-3模型代表了当前视频生成AI技术的最前沿水平。与早期版本相比,Veo-3在视频生成质量、连贯性和细节表现方面都有了显著提升。这使得许多研究者开始探索其在医疗领域的应用可能性,特别是在手术培训、术前规划和医疗教育等方面。
手术是一项高度复杂且精细的医疗活动,需要医生具备深厚的专业知识、丰富的实践经验和敏锐的临床判断力。传统的手术培训依赖于真实手术观摩、模拟训练和教科书学习等方式,这些方法虽然有效但存在诸多局限性,如资源消耗大、培训周期长、风险高等。
基于这一背景,研究团队开始探索Veo-3在手术视频生成方面的潜力。他们设想,如果AI能够生成高质量、逻辑合理的手术视频,将为医学教育和培训提供全新的可能性,使医生能够在虚拟环境中反复练习复杂手术,提高手术技能和安全性。
研究方法:SurgVeo评测标准的构建与应用
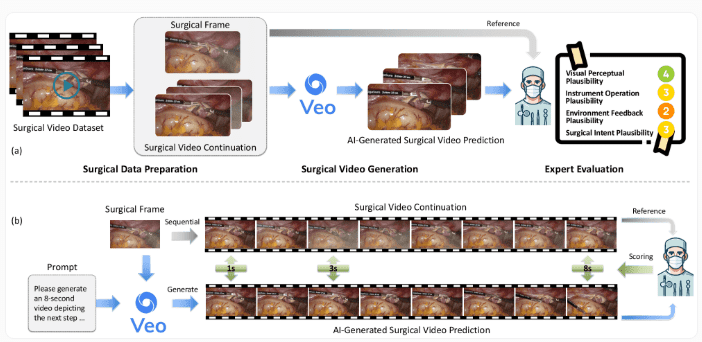
为了全面评估Veo-3在手术视频生成方面的表现,研究团队构建了一个名为SurgVeo的专业评测标准。这一标准基于医学专业人士的视角,旨在全面评估AI生成手术视频的质量和医学合理性。
数据集构建
研究团队精心收集并整理了50段真实的腹腔和脑部手术视频,涵盖了多种常见手术类型和操作场景。这些视频不仅具有视觉多样性,还包含了丰富的医学信息,为评估AI模型的医学理解能力提供了坚实基础。
评测框架设计
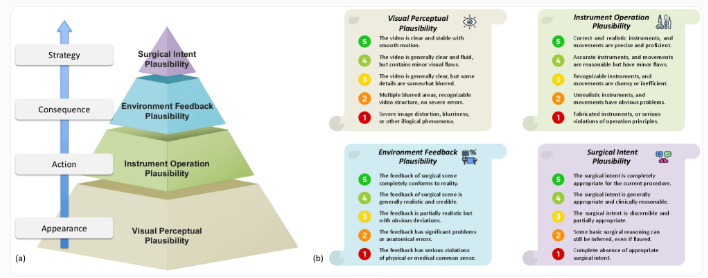
SurgVeo评测标准从四个关键维度对AI生成的手术视频进行评分:
- 视觉真实性:评估视频的视觉质量、细节表现和真实感
- 器械使用的合理性:评估手术器械的选择、使用方式和操作规范
- 组织反应:评估组织在手术过程中的生理反应和变化
- 手术逻辑性:评估手术步骤的合理性、连贯性和符合医学规范的程度
专家评估流程
研究团队邀请了四位经验丰富的外科医生参与评估工作。这些专家来自不同专业领域,具有丰富的临床经验和教学背景,能够从专业角度对AI生成的手术视频进行全面评估。
评估采用双盲方式进行,确保评分的客观性和公正性。每位专家独立对AI生成的视频进行评分,评分采用5分量表,1分表示极差,5分表示优秀。评分结果通过统计分析进行处理,得出最终的评估结论。
研究发现:视觉逼真与医学逻辑的巨大反差
整体评估结果
研究结果显示,Veo-3在手术视频生成方面展现出令人惊讶的能力,特别是在视觉真实性方面获得了专家的高度评价。多位外科医生表示,Veo-3生成的视频"清晰得令人震惊",在视觉细节和真实感方面已经达到了令人难以置信的水平。
然而,当评估深入到医学专业层面时,Veo-3的表现却呈现出巨大的反差。在腹腔手术测试中,Veo-3的视觉合理性得分为3.72分(满分5分),表明其视觉表现已经接近专业水准。但在其他关键医学维度上,得分却显著降低:器械操作仅得1.78分,组织反应1.64分,而手术逻辑性评分更是低至1.61分。
神经外科场景中的表现
在神经外科场景中,Veo-3的表现更为逊色。神经外科手术以其高度复杂性和精确性著称,对医生的技能和判断力提出了极高要求。研究团队发现,在神经外科手术视频中,Veo-3在8秒后的手术逻辑性得分仅为1.13分,几乎处于最低水平。
这一结果尤为令人担忧,因为神经外科手术的任何微小偏差都可能导致严重后果。Veo-3在神经外科场景中的表现表明,当前AI模型在处理高度专业化和精细化的医学操作时,其局限性尤为明显。
错误类型分析
研究团队对Veo-3生成的手术视频中的错误进行了详细分析,发现超过93%的错误源于医学逻辑层面。这些错误主要包括:
- 虚构不存在的手术器械:AI模型会创造现实中不存在或不符合手术需求的器械
- 不符合生理规律的组织反应:组织在手术过程中的变化不符合医学常识和生理规律
- 错误的手术步骤顺序:手术步骤的顺序不符合医学规范和临床实践
- 不合理的操作方式:手术操作方式不符合专业标准和安全要求
上下文信息的影响
为了测试Veo-3在获得更多医学信息后的表现,研究团队尝试为模型提供额外的上下文信息,如手术类型、具体操作阶段、患者情况等。然而,结果显示,这些额外的医学信息并未显著改善Veo-3的表现。
这一发现表明,当前AI模型在医学逻辑理解方面存在根本性局限,简单的信息输入无法弥补其专业知识的缺乏。这也提示我们,要实现真正有医学价值的AI手术视频生成,需要在模型架构和训练方法上进行根本性创新。
研究意义:AI医疗应用的挑战与机遇
对AI医疗发展的警示
这项研究对当前AI医疗应用的发展提出了重要警示。虽然AI技术在医学影像分析、疾病诊断等方面已经取得了显著进展,但在需要深度医学理解和专业判断的领域,如手术模拟和医学教育,AI模型仍然面临巨大挑战。
Veo-3的案例表明,当前AI模型可能擅长生成逼真的视觉内容,但在理解和模拟复杂医学过程方面存在根本性局限。这一发现提醒我们,在推进AI医疗应用时,需要保持清醒的认识,避免过度夸大现有技术的能力。
医学培训中的潜在风险
研究特别强调了在医学培训中使用AI生成视频的潜在风险。如果医学学生或年轻医生基于逻辑错误的手术视频进行学习,可能会形成错误的手术观念和技术习惯,这对患者安全和医疗质量构成严重威胁。
研究团队指出,虽然未来AI生成的手术视频可能成为医学培训的辅助工具,但在当前技术条件下,必须谨慎使用,并需要专业医生的严格监督和指导。任何AI生成的医学内容都应该经过医学专家的审核和验证,确保其医学准确性和教育价值。
数据集开源的推动作用
为了促进AI在医学理解方面的进步,研究团队计划将SurgVoe数据集开源。这一举措将为学术界提供宝贵的资源,帮助研究人员开发和评估更先进的AI模型,特别是在医学逻辑理解方面。
开源数据集的发布有望吸引更多研究力量投入到AI医疗领域,推动技术创新和方法改进。同时,这也将促进不同研究团队之间的合作与交流,加速AI医疗应用的健康发展。
未来展望:迈向真正理解医学的AI
技术创新方向
基于这项研究的发现,未来AI医疗应用的发展需要在以下几个方面进行重点突破:
- 医学知识融合:将医学专业知识深度融入AI模型架构,提高模型的医学逻辑理解能力
- 多模态学习:结合文本、图像、视频等多种医学数据,增强模型的综合理解能力
- 专家系统结合:将AI与医学专家知识系统结合,优势互补,提高决策准确性
- 持续学习机制:建立能够从医学实践中持续学习和进化的AI系统
跨学科合作的重要性
要实现真正理解医学的AI,需要计算机科学、医学、认知科学等多个学科的深度合作。医学专家需要参与AI模型的开发和评估,提供专业的医学知识和临床经验;AI研究者则需要深入了解医学领域的特殊需求和挑战。
这种跨学科合作将有助于打破技术壁垒和学科界限,推动AI医疗应用向更高水平发展。只有真正理解医学本质的AI,才能在医疗领域发挥最大价值。
伦理与监管考量
随着AI在医疗领域的应用不断深入,相关的伦理和监管问题也日益凸显。我们需要建立完善的评估标准和监管机制,确保AI医疗应用的安全性和有效性。同时,也需要关注AI医疗应用中的隐私保护、数据安全等伦理问题。
政府和相关机构应该积极制定AI医疗应用的指导方针和规范,为技术创新提供明确的方向和边界。只有这样,才能在促进创新的同时,保障患者权益和医疗质量。
结论:在期待与现实之间寻找平衡
谷歌Veo-3的研究案例为我们提供了一个宝贵的视角,让我们得以一窥当前AI技术在医疗领域的真实能力和局限。虽然AI在视觉生成方面已经取得了令人瞩目的成就,但在医学逻辑理解方面仍然存在巨大差距。
这一发现既是对当前AI医疗应用的警示,也是未来发展的指引。我们需要在技术创新和临床需求之间找到平衡点,既要充分发挥AI技术的优势,又要清醒认识其局限性,确保AI医疗应用的安全性和有效性。
随着SurgVoe数据集的开源和更多研究力量的投入,我们有理由期待,未来的AI模型将在医学理解方面取得突破性进展。那一天,AI生成的手术视频将不仅仅是视觉上的逼真,更将在医学逻辑上达到专业水准,为医学教育和培训提供真正有价值的工具。
在通往真正理解医学的AI的道路上,我们还有很长的路要走。但正如这项研究所展示的,每一步探索都将为我们带来宝贵的经验和启示,推动AI医疗应用向更高水平发展。在这个过程中,技术创新与医学专业知识的深度融合将是关键所在。





