
在去年Google AI Overviews灾难性推出后,公众开始广泛关注AI驱动搜索结果与传统搜索引擎几十年生成的链接列表之间的巨大差异。现在,新研究帮助量化了这种差异,表明AI搜索引擎倾向于引用不太受欢迎的网站,而这些网站甚至不会出现在传统Google搜索的前100个链接中。
研究背景与方法
在题为《生成式AI时代网络搜索的特征分析》的预印本论文中,德国波鸿鲁尔大学和马克斯·普朗克软件系统研究所的研究人员比较了Google搜索引擎的传统链接结果与其AI Overviews和Gemini-2.5-Flash。研究人员还考察了GPT-4o的网络搜索模式以及单独的'GPT-4o带搜索工具'——只有在LLM决定需要在其预训练数据之外找到信息时才会诉诸网络搜索。
研究人员从多个来源收集测试查询,包括提交给ChatGPT的特定问题(WildChat数据集中)、AllSides上列出的通用政治话题以及100个搜索量最大的亚马逊产品列表中的产品。
非主流信息源的选择倾向
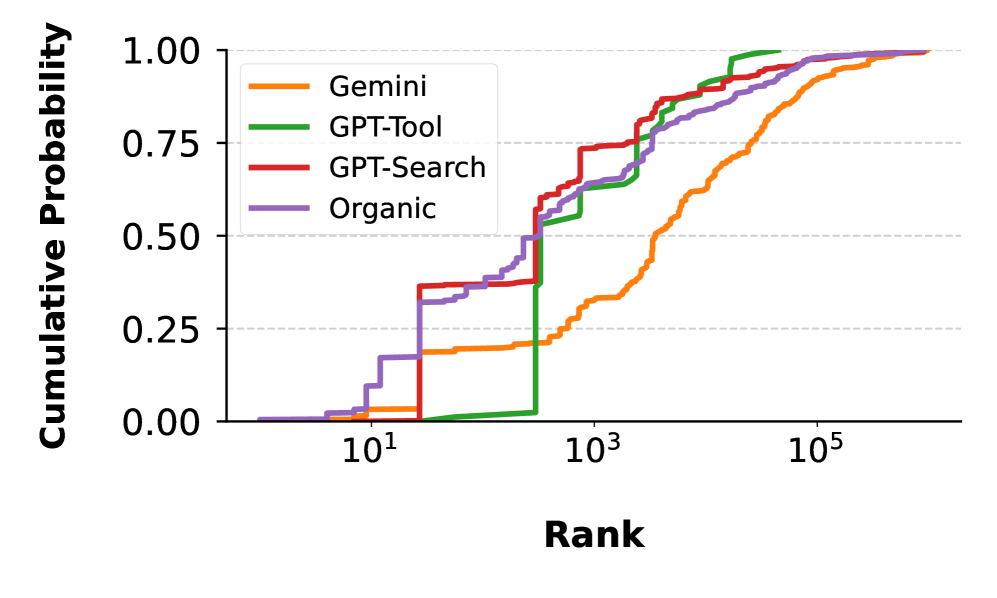
总体而言,生成式搜索工具结果中引用的信息源往往来自比传统搜索前10名更不受欢迎的网站——这是通过域名跟踪器Tranco衡量的。AI引擎引用的信息源比传统Google搜索链接的信息源更有可能落在Tranco跟踪的前1,000名和前1,000,000名域名之外。特别是Gemini搜索表现出引用不受欢迎域名的倾向,在所有结果中,中位数信息源都落在Tranco前1,000名之外。
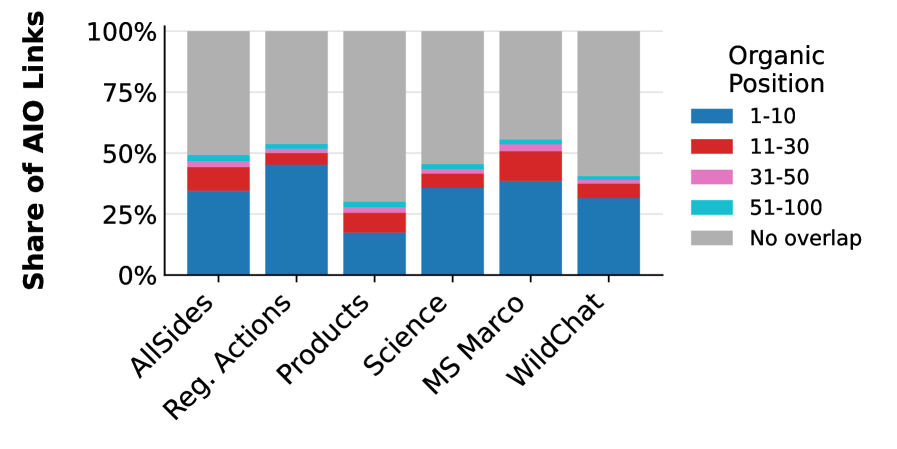
AI驱动的搜索引擎引用的信息源也往往是那些在相同有机Google搜索结果中根本不会出现在顶部附近的信息源。例如,Google AI Overviews引用的53%的信息源没有出现在相同查询的前10个Google链接中,40%的信息源甚至没有进入前100个Google链接。
信息质量与多样性的平衡
这些差异并不一定意味着AI生成的结果'更差'。研究人员发现,基于GPT的搜索更有可能引用企业实体和百科全书等来源的信息,而几乎从不引用社交媒体网站。
基于LLM的分析工具发现,AI驱动的搜索结果往往覆盖与传统的前10个链接相似数量的可识别'概念',表明结果在细节、多样性和新颖性方面处于相似水平。同时,研究人员发现'生成式引擎倾向于压缩信息,有时省略了传统搜索保留的次要或模糊方面'。对于更模糊的搜索术语(例如不同人共享的名字),这种情况尤其明显,研究人员发现'有机搜索结果提供了更好的覆盖'。
技术优势与局限性
AI搜索引擎 arguably 的优势在于能够将从引用网站收集的数据与预训练的'内部知识'编织在一起。这对于GPT-4o带搜索工具尤其明显,它通常不引用任何网络来源,而是仅基于其训练提供直接响应。
然而,这种对预训练数据的依赖在搜索及时信息时可能成为一个限制。对于从Google 9月15日趋势查询列表中提取的搜索词,研究人员发现GPT-4o带搜索工具通常回复类似'能否请您提供更多信息'的信息,而不是实际搜索网络以获取最新信息。
未来研究方向
虽然研究人员没有确定基于AI的搜索引擎总体上比传统搜索引擎链接'更好'或'更差',但他们确实敦促未来研究'新的评估方法,这些方法共同考虑生成式搜索系统中的信息源多样性、概念覆盖率和综合行为'。
这一发现对我们理解信息生态系统具有重要意义。随着AI搜索引擎的普及,我们可能需要重新思考什么是'权威信息',以及如何评估搜索结果的质量。非主流信息源的引入可能会带来更多元化的观点,但也可能增加信息验证的复杂性。
对用户的影响
对于普通用户而言,这一研究意味着在使用AI搜索引擎时应该采取更加批判性的态度。虽然这些工具能够提供更综合的信息摘要,但用户需要意识到这些信息可能来自传统搜索引擎不会优先考虑的来源。
特别是在涉及重要决策或需要高度准确性的领域,用户可能需要采取双重策略:既利用AI搜索引擎获取综合观点,又使用传统搜索引擎验证信息源的可靠性和时效性。
行业启示
这一研究对搜索引擎行业提供了重要启示。随着AI技术的不断发展,搜索引擎提供商可能需要重新考虑他们的信息源评估标准,平衡流行度与质量、权威性与多样性之间的关系。
同时,这也为内容创作者提供了新的机会:即使不是大型媒体或高流量网站,只要内容质量高、相关性好,也有可能通过AI搜索引擎获得前所未有的曝光度。这可能促使互联网内容生态朝着更加多元化和专业化的方向发展。









