R1-Onevision:多模态视觉推理的先锋探索
摘要
R1-Onevision,一个由Qwen2.5-VL微调而成的开源多模态视觉推理模型,以其强大的图像与文本处理能力,在复杂的视觉推理任务中崭露头角。它不仅能够理解和分析图像中的细节信息,还能结合文本进行深度推理,这使得R1-Onevision在科学研究、教育、图像理解、医疗影像分析乃至自动驾驶等多个领域展现出广泛的应用潜力。通过形式化语言、规则强化学习以及精心设计的数据集,R1-Onevision在多模态信息融合和推理方面实现了显著的性能提升,并在多项基准测试中超越了同类模型,为人工智能领域带来了新的发展机遇。
引言
随着人工智能技术的飞速发展,多模态学习已成为研究的热点。多模态学习旨在使机器能够处理和理解来自不同模态(如文本、图像、音频等)的信息,从而实现更智能、更全面的认知。在多模态学习的众多应用中,视觉推理尤为重要。视觉推理要求模型不仅能够“看到”图像,还能够“理解”图像中的内容,并结合其他信息进行逻辑推理。R1-Onevision 正是在这一背景下应运而生,它致力于解决复杂的视觉推理问题,推动多模态人工智能技术的发展。
R1-Onevision的核心技术
R1-Onevision的核心技术主要体现在以下几个方面:
1. 多模态融合与推理
R1-Onevision 能够同时处理图像和文本输入,通过先进的 embedding 技术实现视觉与语言信息的高效整合。这种技术使得模型能够理解图像中的视觉信息,并将其与文本信息相结合,进行深度的推理。例如,在处理包含图表和文字的图像时,R1-Onevision 能够同时理解图表的结构和文字内容,从而回答关于图表的问题,或者进行更复杂的分析。这种多模态融合能力是模型在复杂推理任务中表现出色的关键。
2. 形式化语言驱动的推理
为了提升推理的准确性和可解释性,R1-Onevision 引入了形式化语言(Formal Language)来表达图像内容。形式化语言提供了一种结构化的方式来描述图像中的对象、关系和属性,使得推理过程更加精确和透明。通过使用形式化语言,模型可以构建更清晰的逻辑链条,减少推理过程中的歧义,并提供更可靠的答案。这种技术特别适用于需要精确推理的场景,例如科学研究和教育领域。
3. 基于规则的强化学习
R1-Onevision 在训练过程中采用了基于规则的强化学习(Rule-Based Reinforcement Learning, RL)。这种方法通过明确的逻辑约束和结构化输出,确保模型在推理过程中遵循逻辑推导的原则。基于规则的强化学习使得模型能够学习到更可靠的推理策略,并在面对复杂问题时保持一致的性能。这有助于模型在各种应用场景中提供准确的答案,尤其是在需要高度可靠性的领域,如医疗诊断和自动驾驶。
4. 精心设计的数据集
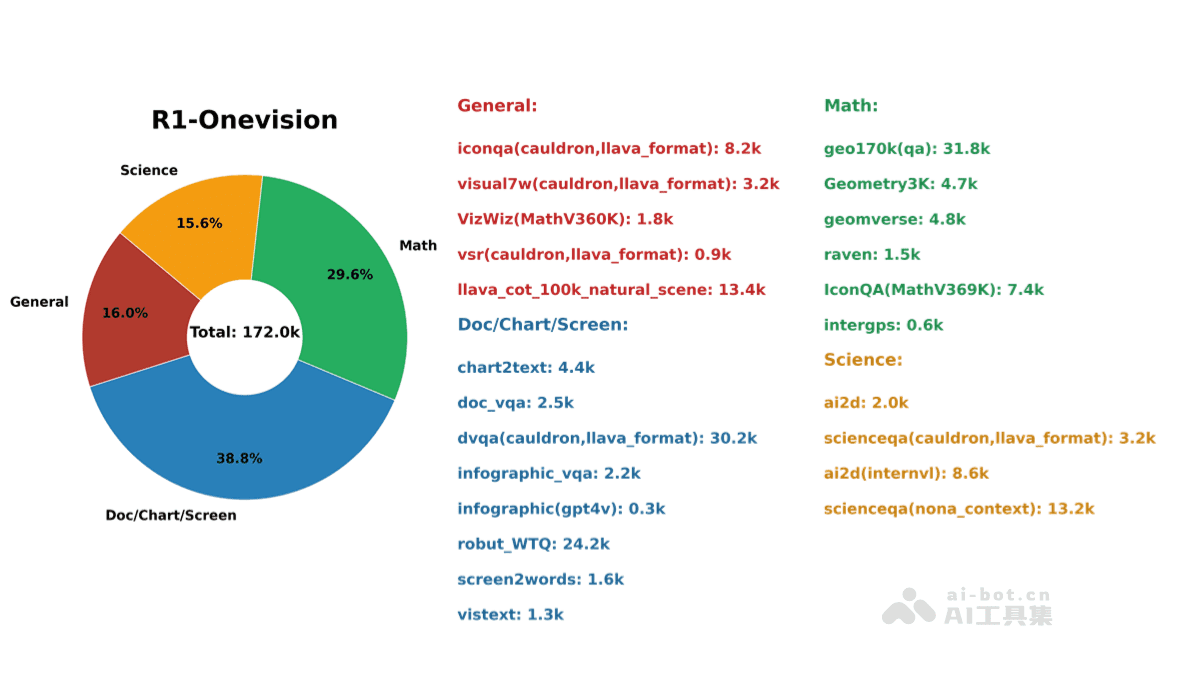
R1-Onevision 的数据集经过精心设计,通过密集标注技术捕捉图像的细节信息,结合语言模型的推理能力生成更具逻辑性的文本描述。数据集的质量直接影响模型的性能。R1-Onevision 团队投入大量精力构建了一个高质量、多样化的数据集,涵盖了自然场景、科学、数学问题、OCR 内容和复杂图表等多个领域。高质量的数据集为模型的训练提供了坚实的基础,使得模型能够学习到更广泛的知识,并提升其在各种任务中的表现。
5. 强化学习优化
R1-Onevision 借鉴了 DeepSeek 的 GRPO(Generative Reward Processing Optimization)强化学习技术。通过自监督学习和优化,减少了对大量标注数据的依赖,提升了学习速度和泛化能力。GRPO 技术使模型能够在没有大量人工标注的情况下,通过自我探索和优化来提升性能。这不仅降低了训练成本,还提升了模型在未见数据上的泛化能力。
6. 模型架构与训练
R1-Onevision 基于 Qwen2.5-VL 微调而成。Qwen2.5-VL 是一个强大的多模态大语言模型,为 R1-Onevision 提供了坚实的基础。R1-Onevision 采用了全模型监督微调(Full Model SFT)方法,并在训练过程中使用了 512 分辨率的图像输入以节省 GPU 内存。此外,模型通过优化学习率和梯度累积等技术,进一步提升了训练效率。这些技术细节保证了 R1-Onevision 在性能和效率上的卓越表现。
R1-Onevision的应用场景
R1-Onevision 在多个领域展现出广泛的应用前景,以下是几个主要的应用场景:
1. 科学研究与数据分析
R1-Onevision 在数学、物理和化学等领域的复杂推理任务中表现出色,能帮助科学家分析复杂的数据集,解决高难度的逻辑问题。例如,它可以用于分析实验数据、解读科学文献,并进行复杂的计算和推理。这有助于加速科学研究的进程,推动科学发现。
2. 教育工具
模型可以作为教育辅助工具,为学生提供精准的解答和指导。它可以解析复杂的科学问题或数学题目,以清晰的逻辑推理过程帮助学生理解。通过提供详细的解题步骤和解释,R1-Onevision 可以帮助学生更好地掌握知识,提升学习效果。
3. 图像理解与分析
R1-Onevision 能对自然场景、复杂图表和图像进行深度分析。例如,它可以在街景照片中识别潜在的危险物体,如行人、车辆和交通标志,为自动驾驶和智能交通系统提供支持。此外,它还可以用于分析复杂图表,提取关键信息,并进行趋势预测。
4. 医疗影像分析
在医疗领域,R1-Onevision 可以用于分析医学影像,辅助医生进行诊断。多模态推理能力能够结合图像与文本信息,提供更准确的分析结果。例如,它可以分析 X 光片、CT 扫描和 MRI 图像,识别疾病的早期迹象,并提供诊断建议。这有助于提高诊断的准确性和效率,改善患者的治疗效果。
5. 自动驾驶与智能交通
模型可以应用于自动驾驶场景,帮助车辆更好地理解复杂的交通环境,识别潜在危险并做出合理的决策。R1-Onevision 可以分析来自摄像头和其他传感器的图像数据,识别道路标志、行人和其他车辆,并预测它们的行为。这有助于提高自动驾驶系统的安全性,实现更可靠的自动驾驶。
案例分析
案例一:科学研究中的应用
假设一位科学家正在研究一个复杂的物理实验。实验结果以图表和文字的形式呈现。科学家可以使用 R1-Onevision 来分析这些图表和文本,提取关键信息,并进行逻辑推理。例如,R1-Onevision 可以识别图表中的趋势,计算关键参数,并预测未来的实验结果。通过这种方式,R1-Onevision 可以加速科学研究的进程,帮助科学家更好地理解实验结果。
案例二:教育领域的应用
一位学生正在学习微积分。他遇到了一道复杂的积分题,难以理解解题步骤。学生可以使用 R1-Onevision 来解决这道题。R1-Onevision 不仅可以给出正确的答案,还可以提供详细的解题步骤和解释。通过这种方式,学生可以更好地理解微积分的原理,掌握解题方法,并提高学习效果。
案例三:医疗影像分析的应用
一位医生正在诊断一位患者的肺部 X 光片。X 光片显示了一些模糊的阴影,难以判断是否为肺部肿瘤。医生可以使用 R1-Onevision 来辅助诊断。R1-Onevision 可以分析 X 光片,识别潜在的肿瘤迹象,并提供诊断建议。通过结合图像信息和文本信息,R1-Onevision 可以提高诊断的准确性和效率,帮助医生做出更明智的决策。
R1-Onevision的优势与挑战
R1-Onevision 凭借其强大的多模态融合与推理能力,在人工智能领域展现出显著的优势。然而,它也面临一些挑战。
优势
- 卓越的推理能力:在数学、科学、深度图像理解和逻辑推理等领域表现出色,超越了 Qwen2.5-VL-7B 和 GPT-4V 等模型。
- 多模态融合:能够同时处理图像和文本输入,通过先进的 embedding 技术实现高效的信息提取与关联。
- 广泛的应用场景:适用于科学研究、教育工具、图像理解、医疗影像分析和自动驾驶等多个领域。
- 技术创新:采用形式化语言、规则强化学习和精心设计的数据集,提升了推理的准确性和效率。
- 开源与社区支持:项目在 Github 和 Hugging Face 上开源,方便研究者和开发者使用和贡献。
挑战
- 计算资源需求:模型的训练和运行需要大量的计算资源,包括 GPU 和内存。
- 数据依赖:模型的性能很大程度上依赖于训练数据的质量和数量。
- 泛化能力:在处理未见过的复杂场景时,模型的泛化能力仍有提升空间。
- 伦理问题:在医疗影像分析和自动驾驶等领域,模型的应用可能涉及伦理问题,需要谨慎考虑。
未来展望
R1-Onevision 的出现为多模态视觉推理带来了新的希望。未来,R1-Onevision 可以通过以下几个方面进行改进和发展:
- 优化模型架构:进一步优化模型架构,提升模型的效率和性能。
- 增强多模态融合:探索更先进的 embedding 技术,实现更深度的多模态信息融合。
- 拓展应用场景:将 R1-Onevision 应用于更多领域,如机器人、虚拟现实和增强现实等。
- 提升泛化能力:通过更强大的自监督学习技术,提升模型在未见数据上的泛化能力。
- 加强伦理考量:在模型的开发和应用过程中,加强伦理考量,确保其应用符合社会道德规范。
通过持续的技术创新和应用拓展,R1-Onevision 有望在多模态人工智能领域发挥更大的作用,为人类社会带来更多福祉。