
在人工智能音乐创作领域,上海AI Lab联合北京航空航天大学、香港中文大学推出了一个引人注目的新模型——SongGen。这款单阶段自回归Transformer模型,旨在通过文本输入直接生成歌曲,为音乐创作带来了全新的可能性。相较于传统的多阶段模型,SongGen以其创新的音频标记化策略和训练方法,显著提升了生成歌曲的自然度和人声清晰度,简化了复杂的训练和推理流程,为未来的音乐生成研究奠定了坚实的基础。
SongGen的核心功能:精细化控制与多样化输出
SongGen的核心优势在于其对生成过程的精细控制能力。用户可以通过输入歌词和描述性文本(如乐器、风格、情感等)来精确地指导歌曲的生成。这种细粒度的控制为音乐创作提供了极大的灵活性,使得创作者可以根据自己的想法定制歌曲。
此外,SongGen还支持声音克隆功能。通过提供一段三秒的参考音频,用户可以让生成的歌曲具有特定歌手的音色。这为模仿特定风格或创造个性化声音提供了便利。
在输出模式方面,SongGen提供两种选择:“混合模式”和“双轨模式”。混合模式直接生成人声和伴奏的混合音频,适用于快速生成歌曲原型。而双轨模式则分别合成人声和伴奏,方便后期编辑和调整,满足了专业音乐制作的需求。
更重要的是,SongGen通过优化的音频标记化和训练策略,能够生成具有高自然度和清晰人声的歌曲。这解决了传统AI音乐生成中人声质量不佳的问题,使得生成的歌曲更具实用价值。
技术原理:自回归框架与音频标记化
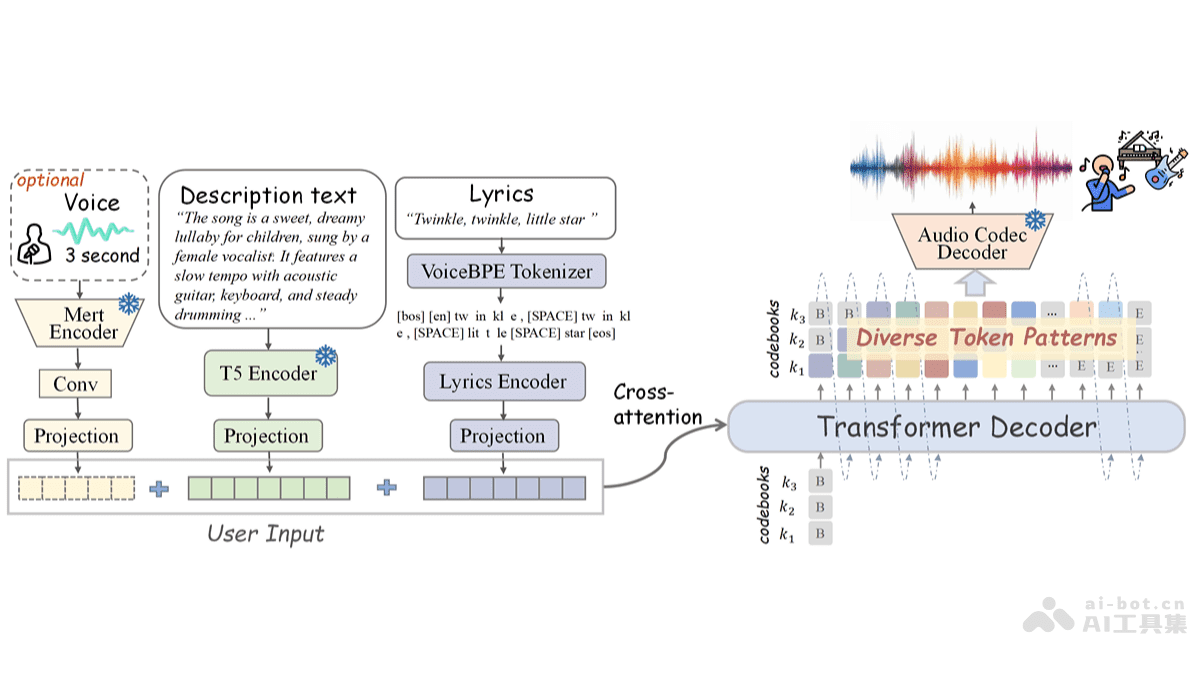
SongGen的技术核心在于其自回归生成框架。该框架基于自回归Transformer解码器,将歌词和描述性文本编码为条件输入,并利用交叉注意力机制引导音频标记的生成。这种结构使得模型能够理解文本输入,并将其转化为相应的音乐内容。
音频标记化是SongGen的另一项关键技术。模型使用X-Codec将音频信号编码为离散的音频标记,并通过代码本延迟模式处理多代码序列,从而实现高效的音频生成。这种方法不仅提高了生成速度,还有助于提升音频质量。
在处理混合模式和双轨模式时,SongGen采用了不同的策略。在混合模式下,模型直接生成混合音频标记,并引入辅助人声音频标记预测目标(Mixed Pro)来增强人声清晰度。而在双轨模式下,模型基于平行或交错模式分别生成人声和伴奏标记,确保两者在帧级别上的对齐,从而提升整体生成质量。
SongGen还采用了多种条件输入编码技术。VoiceBPE分词器将歌词转换为音素级标记,并使用小型Transformer编码器提取关键发音信息。MERT模型提取参考音频的音色特征,用于支持声音克隆。FLAN-T5模型则将描述性文本编码为特征向量,用于提供音乐风格、情感等控制。
为了进一步提升模型性能,SongGen采用了多阶段训练策略,包括模态对齐、无参考声音支持和高质量微调。此外,模型还采用了课程学习方法,逐步调整代码本损失权重,优化模型对音频细节的学习。为了确保数据质量,研究团队还开发了自动化数据预处理管道,从多个数据源收集音频,分离人声和伴奏,并生成高质量的歌词和描述性文本数据集。
项目地址与资源
对于希望深入了解或使用SongGen的研究者和开发者,以下是相关资源:
- GitHub仓库:https://github.com/LiuZH-19/SongGen
- arXiv技术论文:https://arxiv.org/pdf/2502.13128
SongGen的应用场景:无限可能
SongGen的应用前景广阔,可以应用于各种场景,例如:
- 音乐创作:SongGen可以作为音乐创作的强大辅助工具,帮助创作者快速生成歌曲雏形,探索不同的音乐风格,并为歌词生成伴奏,从而加速创作流程。对于缺乏音乐基础的创作者,SongGen降低了创作门槛,让他们能够更容易地表达自己的音乐想法。
- 视频配乐:在短视频、广告、电影等领域,SongGen可以用于生成背景音乐,并根据内容调整风格,提升视觉效果。相比于传统的音乐素材,使用SongGen生成的音乐更具独特性和个性化,能够更好地与视频内容融合。
- 教育辅助:SongGen可以帮助学生理解音乐创作,通过生成歌曲学习语言发音,激发创造力。例如,教师可以使用SongGen来创作歌曲,帮助学生学习外语,或者鼓励学生使用SongGen进行音乐创作,培养他们的音乐素养。
- 个性化体验:SongGen可以根据用户输入生成定制歌曲,用声音克隆实现“个人专属歌手”,增强娱乐性。例如,用户可以输入自己的歌词和喜欢的音乐风格,让SongGen生成一首专属歌曲,或者使用声音克隆功能,让歌曲听起来像自己喜欢的歌手演唱。
- 商业应用:SongGen可以为品牌生成专属音乐,替代版权受限的音乐素材,用于广告和推广。这不仅可以降低版权成本,还可以提升品牌的独特性和辨识度。
从技术原理到应用场景的深度解析
深入分析SongGen的技术原理,我们可以看到其在音频生成领域的创新之处。自回归Transformer架构赋予了模型强大的序列建模能力,使其能够捕捉音乐中的复杂结构和模式。音频标记化技术则将连续的音频信号转化为离散的符号,使得模型能够像处理文本一样处理音频,从而简化了生成过程。
混合模式和双轨模式的设计则体现了SongGen在输出灵活性方面的考量。混合模式适用于快速原型设计,而双轨模式则更适合精细的后期编辑。条件输入编码技术则使得用户可以通过歌词、风格描述等信息来精确控制生成结果,从而实现个性化定制。
从应用场景来看,SongGen的潜力远不止于上述几个方面。随着人工智能技术的不断发展,我们可以预见SongGen将在更多领域发挥作用。例如,在游戏开发领域,SongGen可以用于生成游戏背景音乐和音效;在虚拟现实领域,SongGen可以用于创建沉浸式的音乐体验;在音乐治疗领域,SongGen可以用于帮助患者表达情感和缓解压力。
AI音乐创作的未来展望
SongGen的出现,标志着AI音乐创作进入了一个新的阶段。它不仅简化了创作流程,降低了创作门槛,还为音乐创作带来了无限的可能性。然而,AI音乐创作仍然面临着一些挑战,例如如何提高生成音乐的艺术性和情感表达能力,如何更好地控制生成过程,以及如何解决版权问题等。
为了克服这些挑战,我们需要进一步研究新的模型架构、训练方法和评估指标。同时,我们也需要加强与音乐家的合作,将他们的专业知识和经验融入到AI音乐创作中。只有这样,我们才能真正实现AI与人类的协同创作,创造出更加优秀和动人的音乐作品。
总而言之,SongGen作为上海AI Lab、北京航空航天大学和香港中文大学联合推出的创新模型,无疑为AI音乐生成领域注入了新的活力。凭借其独特的单阶段自回归Transformer架构、创新的音频标记化策略以及对生成过程的精细控制能力,SongGen不仅提升了生成歌曲的自然度和人声清晰度,还为未来的音乐生成研究提供了新的基准。随着技术的不断进步和应用场景的不断拓展,我们有理由相信,AI音乐创作将在未来发挥越来越重要的作用,为人类带来更加丰富多彩的音乐体验。








