
在人工智能视频生成领域,清华大学的研究团队近期开源了一项名为Video-T1的创新技术,引起了广泛关注。该技术的核心在于测试时缩放(Test-Time Scaling,TTS),它能够在视频生成的推理阶段,通过增加计算资源的投入,从而显著提升生成视频的质量以及与文本提示的一致性,而无需进行耗时且成本高昂的重新模型训练。Video-T1的出现,无疑为视频生成领域带来了新的可能性和发展方向。

测试时缩放(TTS)的原理
在大型语言模型(LLMs)的研究中,人们已经发现,在测试阶段增加计算量可以有效地提升模型的性能。Video-T1正是借鉴了这一思路,并将其创造性地应用于视频生成领域。传统的视频生成模型在接收到文本提示后,通常会直接生成一段视频。而采用了TTS的Video-T1,则类似于在视频生成过程中进行多次“搜索”和“筛选”,通过生成多个候选视频,并利用“测试验证器”进行评估,最终选择质量最高的视频。这种方法就像一位技艺精湛的艺术家,在创作最终作品之前会尝试多种不同的方法和细节,力求达到完美。
可以将TTS理解为一种在推理过程中对模型进行优化的方法。它并不改变模型本身的结构或参数,而是在生成视频时,通过多次尝试和评估,找到最佳的生成结果。这种方法的优势在于,它可以在不增加训练成本的前提下,显著提升视频的质量。
Video-T1的核心技术解析
Video-T1并没有直接增加训练成本,而是专注于如何更有效地利用现有模型的能力。其核心方法可以理解为在模型的“噪声空间”中寻找更优的视频生成轨迹。为了实现这一目标,研究团队提出了两种主要的搜索策略:随机线性搜索(Random Linear Search)和帧树搜索(Tree-of-Frames,ToF)。
随机线性搜索(Random Linear Search):这种方法通过随机采样多个高斯噪声,让视频生成模型对这些噪声进行逐步去噪,从而生成多个候选视频片段。然后,利用测试验证器对这些候选视频进行评分,最终选择得分最高的视频。这种方法简单直接,易于实现,但计算成本相对较高。
随机线性搜索的关键在于噪声的采样和测试验证器的设计。噪声的采样需要保证多样性,以便覆盖尽可能多的视频生成轨迹。而测试验证器则需要能够准确地评估视频的质量,从而选出最佳的候选视频。
帧树搜索(Tree-of-Frames,ToF):考虑到同时对所有帧进行全步去噪会带来巨大的计算成本,ToF采用了一种更为高效的策略。它将视频生成过程分为三个阶段:首先进行图像级别的对齐,这会影响后续帧的生成;其次,在测试验证器中使用动态提示,重点关注运动的稳定性和物理上的合理性,并根据反馈指导搜索过程;最后,评估视频的整体质量,并选择与文本提示对齐度最高的视频。ToF这种自回归的方式能够更智能地探索视频生成的可能性。
帧树搜索的优势在于其高效性。通过将视频生成过程分解为多个阶段,并采用动态提示和自回归的方式,ToF能够显著减少计算成本,同时保证视频的质量。这种方法特别适用于生成长视频或复杂场景的视频。
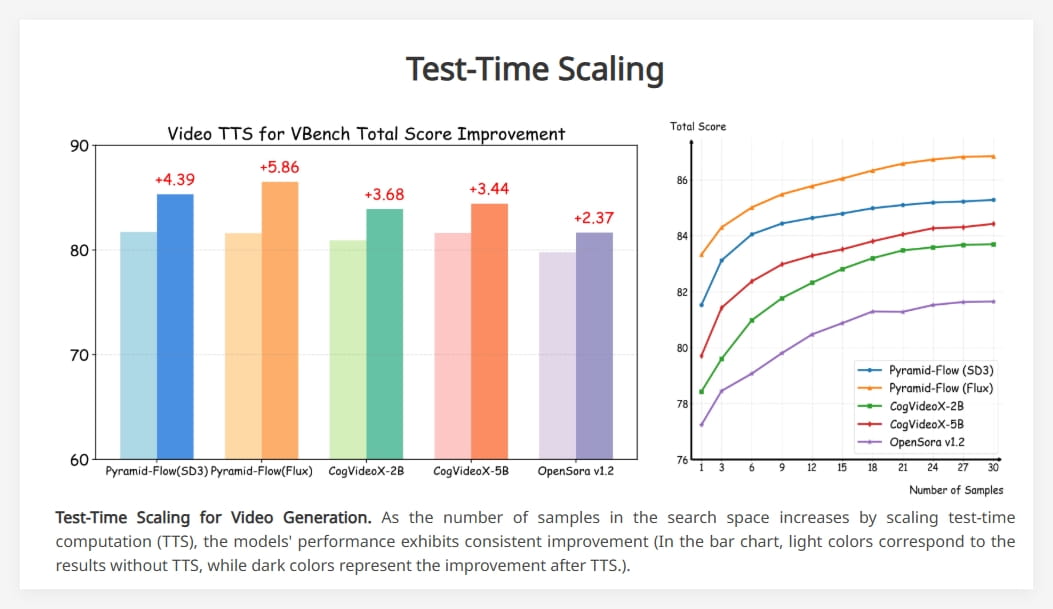
TTS的显著效果与性能提升
实验结果表明,随着测试时计算量的增加(即生成更多候选视频),模型性能会持续提升。这意味着,通过投入更多的推理时间,即使是同一个视频生成模型,也能够产生更高质量、与文本提示更加一致的视频。研究人员在多个视频生成模型上进行了实验,结果都显示出TTS能够稳定地带来性能提升。同时,不同的测试验证器关注的评估方面有所不同,因此在性能提升的速率和程度上也存在差异。
TTS的性能提升主要体现在以下几个方面:
- 视频质量:TTS能够显著提升视频的清晰度、细节和真实感。
- 文本一致性:TTS能够使生成的视频更好地符合文本提示的要求,避免出现与文本描述不符的情况。
- 运动流畅性:TTS能够在一定程度上提升视频的运动流畅性,减少画面跳动和不自然现象。
Video-T1的TTS方法在常见的提示类别(如场景、物体)和容易评估的维度(如图像质量)上取得了显著的改进。通过观察官方提供的视频演示可以看出,经过TTS处理后的视频在清晰度、细节和与文本描述的贴合度上都有明显的提升。例如,描述“戴着太阳镜在泳池边当救生员的猫”的视频,在经过TTS处理后,猫的形象更加清晰,救生员的动作也更加自然。

TTS的局限性与未来展望
尽管TTS在许多方面都带来了显著的进步,但研究人员也指出,对于一些难以评估的潜在属性,例如运动的流畅性和时序上的一致性(避免画面闪烁),TTS的改进效果相对有限。这主要是因为这些属性需要对跨帧的运动轨迹进行精确控制,而目前的视频生成模型在这方面仍然面临挑战。
TTS技术仍然存在一些局限性,例如:
- 计算成本:TTS需要生成多个候选视频,并进行评估,因此计算成本相对较高。
- 评估指标:目前缺乏有效的评估指标来衡量视频的运动流畅性和时序一致性。
- 泛化能力:TTS在某些特定场景下的效果可能不佳,需要进一步提升其泛化能力。
尽管存在一些挑战,但TTS作为一种创新的视频生成技术,具有巨大的潜力。未来,随着研究的深入,我们可以期待TTS在以下几个方面取得更大的突破:
- 降低计算成本:通过优化搜索算法和测试验证器,降低TTS的计算成本,使其能够应用于更多场景。
- 提升评估指标:开发更有效的评估指标,以衡量视频的运动流畅性和时序一致性,从而更好地优化TTS的效果。
- 增强泛化能力:通过引入更多的数据和技术,增强TTS的泛化能力,使其能够适应各种不同的场景。
清华大学开源的Video-T1通过创新的测试时缩放策略,为提升视频生成质量提供了一种新的有效途径。它无需昂贵的重新训练,而是通过更智能地利用推理时的计算资源,让现有模型焕发出更强的能力。随着未来研究的深入,我们有理由期待TTS技术在视频生成领域发挥越来越重要的作用,为人们带来更加精彩的视觉体验。
Video-T1的开源,无疑将加速TTS技术的发展和应用。相信在不久的将来,我们将看到更多基于TTS的视频生成应用出现,为人们的生活带来更多便利和乐趣。例如,我们可以利用TTS技术来生成高质量的电影预告片、游戏宣传片、广告视频等。此外,TTS技术还可以应用于虚拟现实、增强现实等领域,为用户带来更加沉浸式的体验。
总结
Video-T1的出现,为视频生成领域带来了一股新的活力。它不仅提升了视频生成的质量,还降低了训练成本,为更多的人提供了参与视频创作的机会。随着技术的不断发展,我们有理由相信,未来的视频生成领域将会更加繁荣,为人们带来更多惊喜。
- 测试时缩放(TTS)是一种创新的视频生成技术,它能够在推理阶段通过增加计算资源的投入,从而显著提升生成视频的质量以及与文本提示的一致性。
- Video-T1的核心技术包括随机线性搜索(Random Linear Search)和帧树搜索(Tree-of-Frames,ToF),它们能够在模型的“噪声空间”中寻找更优的视频生成轨迹。
- TTS的性能提升主要体现在视频质量、文本一致性和运动流畅性等方面。
- TTS技术仍然存在一些局限性,例如计算成本、评估指标和泛化能力。
- 未来,随着研究的深入,我们可以期待TTS在降低计算成本、提升评估指标和增强泛化能力等方面取得更大的突破。








