
OpenAI 近期推出了其最新的图像生成模型,这一举动无疑给图像生成领域带来了一股强劲的冲击波,也直接对标 Google 的“一句话P图”技术。OpenAI 的首席执行官萨姆·奥特曼在社交媒体上分享了他初次体验该模型时的激动心情,他表示对生成图像的质量感到震惊,并期待用户能够充分利用这一工具释放他们的创造力。
这款新型图像生成器的突出特点包括其精确渲染文本内容的能力,从而确保图像具有卓越的质量。它还支持多种输入输出模式,涵盖文本、图像和音频等多种形式,为用户提供了极大的灵活性和便利性。更重要的是,该模型能够理解复杂的指令并结合上下文信息,从而生成具有真实感的第一人称视角图像,这在很大程度上提升了用户体验。
与 OpenAI 之前推出的图像生成模型 DALL·E 不同,GPT-4o 采用了一种自回归模型,该模型原生嵌入在 ChatGPT 中。这意味着它可以处理包含多达 10 到 20 个不同对象的复杂指令,而其竞争对手通常只能处理 5 到 8 个对象。这种显著的提升使得 GPT-4o 在处理复杂场景时表现出更强大的能力。
用户只需简单地描述他们的需求,例如指定图像的纵横比、颜色或透明背景,模型便可以迅速生成图像。虽然渲染更复杂的细节可能需要稍长的时间,但最终生成的效果通常是令人满意的。这种高效和高质量的图像生成能力无疑将极大地提升用户的工作效率。
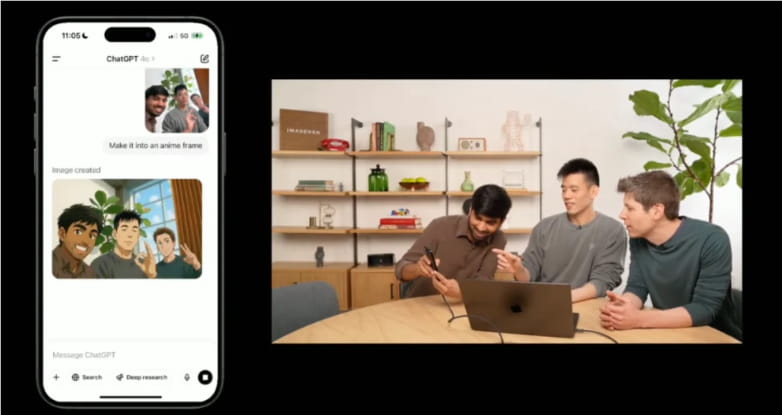
在最近的一次发布会上,演示者展示了多个具体的应用案例。例如,他们将一张合影转换成动漫风格的图像,模型不仅成功地保留了人物的特征,还完美地融合了动漫的视觉效果。此外,演示者还要求生成一页关于相对论的幽默漫画,结果生成的漫画不仅结构完整,而且生动有趣。这些案例充分展示了该模型在图像风格转换和创意内容生成方面的强大能力。
OpenAI 非常重视这一功能的安全性。为了确保内容的可追溯性,所有生成的图像都带有 C2PA 元数据标识,这有助于追溯内容的来源,并有效地阻止不当请求的生成。这种安全措施对于维护图像生成领域的健康发展至关重要。
尽管 OpenAI 的图像生成工具在某些方面仍有不足,例如在裁剪、上下文理解和非拉丁文本渲染等方面,但 OpenAI 承诺将在未来不断优化这些问题。通过持续的改进和优化,OpenAI 旨在为用户提供更强大、更可靠的图像生成服务。
与此同时,Google 也在同一时间发布了其强大的 AI 模型 Gemini 2.5 Pro Experimental,该模型在推理和编程能力方面表现出显著的提升。这些动态表明,人工智能领域的竞争正在变得日益激烈,各大科技巨头都在不断推出更先进的技术,力求在这场“AI 争霸战”中占据领先地位。这种竞争不仅推动了技术的进步,也为用户带来了更多的选择和更好的体验。
OpenAI 新图像生成模型的深度剖析
OpenAI 最新推出的图像生成模型无疑是人工智能领域的一项重大突破。该模型不仅在技术上有所创新,更在应用层面展现出巨大的潜力。通过深入分析其技术特点、应用场景以及潜在的局限性,我们可以更全面地了解这项技术的价值和影响。
技术特点
GPT-4o 模型采用了一种自回归模型,这种模型能够更好地理解和生成复杂的图像内容。与传统的图像生成模型相比,GPT-4o 在处理多对象场景时表现出更强的能力。它可以处理多达 10 到 20 个不同的对象,而竞争对手通常只能处理 5 到 8 个对象。这种显著的提升使得 GPT-4o 在生成复杂场景时更加出色。
此外,GPT-4o 模型还支持多种输入输出模式,涵盖文本、图像和音频等多种形式。这种多模态的支持使得用户可以通过不同的方式与模型进行交互,从而提高了使用的灵活性和便利性。例如,用户可以通过文本描述来生成图像,也可以通过上传图像来进行编辑和修改。
应用场景
OpenAI 的新图像生成模型在多个领域都具有广泛的应用前景。
- 广告和营销:该模型可以用于生成高质量的广告素材和营销内容。通过简单的文本描述,营销人员可以快速生成各种风格的广告图像,从而提高广告的吸引力和转化率。
- 教育:教师可以利用该模型来生成教学材料,例如插图、图表和动画。这可以帮助学生更好地理解抽象的概念,提高学习的效率和趣味性。
- 娱乐:该模型可以用于生成各种创意内容,例如漫画、动画和游戏素材。这为艺术家和设计师提供了更多的创作灵感和工具,从而推动了娱乐产业的发展。
- 设计:设计师可以利用该模型来生成设计草图和原型。通过简单的描述,设计师可以快速生成各种设计方案,从而加快设计流程,提高设计效率。
潜在的局限性
尽管 OpenAI 的新图像生成模型具有很多优点,但也存在一些潜在的局限性。
- 裁剪问题:在某些情况下,模型在处理裁剪问题时可能会出现一些错误。例如,当用户要求裁剪图像的某个部分时,模型可能会出现偏差,导致裁剪结果不符合预期。
- 上下文理解:模型在理解复杂的上下文时可能会存在一定的困难。例如,当用户描述的场景比较复杂时,模型可能会出现理解偏差,导致生成的图像不符合用户的意图。
- 非拉丁文本渲染:模型在渲染非拉丁文本时可能会出现一些问题。例如,当用户要求在图像中添加中文或日文文本时,模型可能会出现乱码或显示错误。
与 Google Gemini 2.5 Pro Experimental 的竞争
在 OpenAI 发布其新图像生成模型的同时,Google 也推出了其强大的 AI 模型 Gemini 2.5 Pro Experimental。这两款模型的发布标志着人工智能领域的竞争正在变得日益激烈。Gemini 2.5 Pro Experimental 在推理和编程能力方面表现出显著的提升,这使得它在某些应用场景中可能更具优势。
OpenAI 和 Google 之间的竞争将推动人工智能技术的不断进步,从而为用户带来更多的选择和更好的体验。未来,我们可以期待看到更多创新的人工智能产品和服务。
结论
OpenAI 推出的新图像生成模型是一项具有里程碑意义的技术创新。它不仅在技术上有所突破,更在应用层面展现出巨大的潜力。尽管该模型仍存在一些局限性,但随着技术的不断发展,这些问题有望在未来得到解决。OpenAI 与 Google 等科技巨头之间的竞争将推动人工智能技术的不断进步,从而为人类社会带来更多的福祉。








