
在人工智能领域,每天都有新的突破和创新涌现。本文将深入探讨近期AI领域的几项重大进展,从OpenAI的图像生成模型到Keling AI的营收突破,再到Google Gemini 2.5的强大推理能力,以及Tencent和清华大学的最新技术成果,全面剖析AI技术的最新动态和未来趋势。
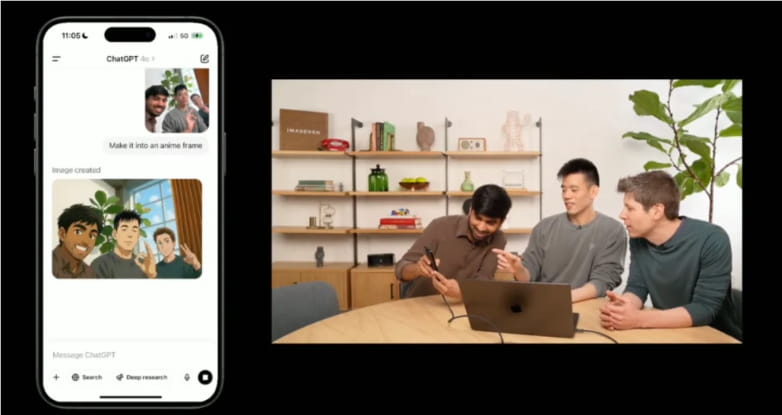
OpenAI推出全新图像生成模型
OpenAI再次引领AI创新浪潮,推出了最新的GPT-4o模型,该模型集成了先进的图像生成器,展示了卓越的图像渲染能力和多样化的输入/输出支持。OpenAI的CEO Sam Altman在社交媒体上分享了他对这一模型的惊叹和期待,鼓励用户充分发挥他们的创造力。GPT-4o的自回归特性使其在处理复杂指令方面表现出色,尽管仍存在一些不足,但OpenAI承诺将持续进行优化。
新模型支持高质量的图像生成,能够准确渲染文本内容,并提供多种输入/输出方法。GPT-4o采用自回归模型,能够处理10到20个复杂指令,展现出更强大的图像生成能力。此外,所有生成的图像都带有C2PA元数据标签,确保内容来源的可追溯性,从而增强安全性。
Keling AI营收破亿
Kuaishou于去年6月推出的Keling AI,已经实现了超过1亿元的营收,成为国内视频生成AI应用领域的佼佼者。其强大的功能和先发的市场定位,使其在竞争激烈的市场中占据了一席之地。Kuaishou计划通过技术创新和资本投入,进一步推动Keling AI的发展,目标是成为全球收入最高的视频生成AI应用。
Keling AI自推出以来,营收已突破1亿元,为国内视频生成AI的商业化树立了标杆。Kuaishou通过AI技术升级其现有业务,从而促进研发和收入的良性循环,目前已经迭代了超过20个版本。Keling AI在国际市场也表现出强大的竞争力,用户群迅速增长,成为全球内容创作者的热门选择。
Google发布Gemini 2.5
Google近期发布了最新的AI推理模型Gemini 2.5及其Pro版本,标志着AI技术取得了显著进展。Gemini 2.5具备“思考”能力,在多项基准测试中超越了竞争对手,尤其在代码编辑和软件开发方面表现突出。Google计划在未来引入更强大的200万token上下文窗口,以进一步提升模型的性能。
Gemini 2.5及其Pro版本具备推理能力,代表了AI技术的新进展。在多项基准测试中,Gemini 2.5 Pro的表现优于多个竞争对手。未来,200万token上下文窗口的引入将进一步增强AI模型的处理能力。更详细的信息,可以参考Google的官方博客。
Tencent推出HunYuan T1和DeepSeek V3-0324
Tencent近期发布了HunYuan T1的正式版本和DeepSeek V3的最新版本,标志着深度学习和人工智能领域的进一步发展。与之前的版本相比,HunYuan T1的正式版本在速度和性能方面都实现了显著升级,实现了秒级响应时间,并优化了各种推理任务的用户体验。DeepSeek V3也经过优化,提供了更准确的分析和推理能力。
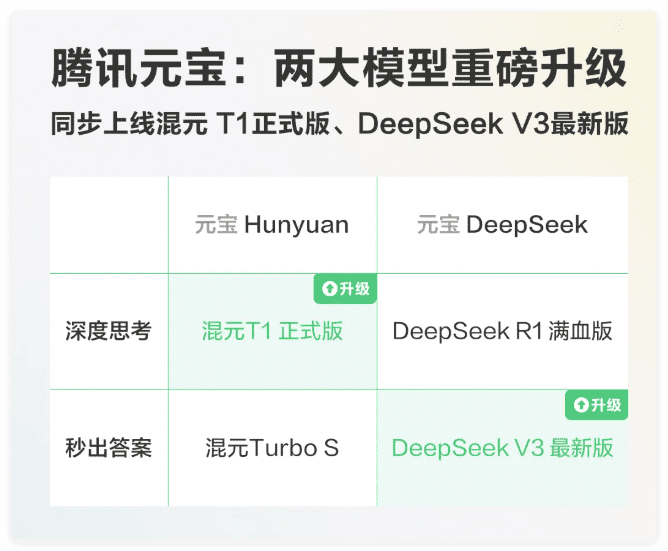
HunYuan T1的正式版本和DeepSeek V3的最新版本同步发布,使用户能够体验最新的深度思考技术。与T1 Preview相比,新版本经过全面升级,提高了速度和性能,实现了秒级响应时间。Tencent Cloud支持HunYuan T1,致力于为用户提供高效的智能服务和技术支持。
Anyshoot:AI电商视频生成工具
Product Anyshoot是一款专为电商行业设计的创新AI视频生成工具,旨在提高产品展示的效率和真实感。商家只需上传产品图片,系统即可智能地将产品集成到预制视频中,大大简化了制作流程。该工具具有高产品保真度,生成的视频质量达到商业标准,有助于中小企业在市场中脱颖而出。

只需上传产品图片,Product Anyshoot即可智能生成高质量的展示视频,从而大大简化制作流程。该工具包含5000多个预制模板,并支持定制,以满足个性化的展示需求。生成的视频的流畅性和真实感均达到商业标准,有助于中小企业提高其竞争力。更多详细信息,请访问https://top.aibase.com/tool/product-anyshoot。
Meitu WHEE推出新的“证件照”功能
WHEE的新“证件照”功能旨在为用户提供便捷的证件照创建体验。用户可以使用移动应用程序在短短五分钟内生成高质量的证件照,从而解决了传统照相馆的不便之处。该功能支持各种尺寸调整,确保用户拥有适用于各种场合的证件照。它还具有无缝的头部和服装更换功能,可以轻松更改背景和服装样式,以满足用户的个性化需求。

证件照功能支持各种尺寸调整,消除了尺寸方面的顾虑,适用于所有场合。它具有无缝的头部和服装更换功能,使用户可以轻松更改背景和服装,以展示不同的风格。多功能的图像功能使用户可以快速更改其图像,从而满足个性化需求。
Tencent Cloud发布DeepSeek最新版本V3模型API接口
Tencent Cloud宣布于3月25日晚发布DeepSeek-V3-0324版本模型的API接口,从而使企业和开发人员可以直接调用该模型,并提供稳定和高质量的服务。新版本在推理任务、编程能力和中文写作方面均显示出显著的改进,尤其是在数学和代码评估方面超越了GPT-4.5。

通过强化学习技术,新的DeepSeek-V3模型提高了其在推理任务中的性能,尤其是在数学和代码评估方面超越了GPT-4.5。编程能力得到了显著增强,生成的HTML代码具有更好的可用性和视觉效果。开发人员认为其能力与Claude 3.5/3.7 Sonnet相当。在中文写作方面,长篇文本创作的质量得到了优化,并且在在线搜索场景中输出了更详细和准确的结果。更多详细信息,请访问https://cloud.tencent.com/document/product/1772/115963。
Tsinghua University开源Video-T1
清华大学的研究团队开源了Video-T1技术,该技术利用测试时缩放(TTS)策略来显著提高视频生成质量和文本一致性。该方法增加了推理过程中的计算资源,避免了昂贵的模型重新训练,并展示了视频生成领域的新可能性。实验表明,TTS可以持续提高模型性能,尤其是在图像质量和场景描述的对齐方面。

TTS策略通过增加推理过程中的计算资源,从而显著提高了视频生成质量和一致性。Video-T1使用随机线性搜索和帧树搜索策略来优化候选视频的生成和评估。实验结果表明,TTS可以持续提高多个视频生成模型的性能,尤其是在图像质量和场景描述的对齐方面。更多详细信息,请访问https://top.aibase.com/tool/video-t1。
Apple使用Apple Maps“环视”照片训练AI模型
Apple近期宣布,它将从2025年3月开始使用从其“环视”功能收集的图像来训练人工智能模型。这些模型将用于图像识别和创建等技术。Apple已承诺在数据收集过程中保护用户隐私,所有图像都将被模糊处理。用户可以要求将其房屋的图像模糊处理。








