
在人工智能领域日新月异的今天,昆仑万维开源 Skywork-OR1 系列模型、iFlytek Xingchen Agent 平台全面支持 MCP、Kimi 开源视觉语言模型 Kimi-VL 等一系列事件,再次将我们的目光聚焦到 AI 技术的创新与应用上。这些进展不仅预示着 AI 技术发展的新方向,也为开发者和企业提供了更强大的工具和平台。
一、Kimi 开源视觉语言模型:多模态理解与推理的飞跃
Moonshot AI 近期开源的 Kimi-VL 和 Kimi-VL-Thinking 视觉语言模型,在多模态理解和推理能力上表现出了卓越的性能。这两款模型采用了轻量级的 MoE 架构,仅有 30 亿参数,却在多个基准测试中超越了 GPT-4o,尤其在数学推理、Agent 操作和高分辨率图像处理方面表现突出。Kimi-VL 系列模型还支持超长上下文理解,能够处理长文档和视频分析,展现出广泛的应用潜力。

轻量级 MoE 架构是 Kimi-VL 系列模型的一大亮点。MoE 架构通过将模型分解为多个子模型,每个子模型处理不同的输入,从而在保证模型性能的同时,降低了计算成本。这种架构特别适用于资源有限的场景,如移动设备和嵌入式系统。Kimi-VL 在 MathVision 和 ScreenSpot-Pro 测试中分别取得了 36.8% 和 34.5% 的优异成绩,充分证明了其强大的推理能力。超长上下文支持是 Kimi-VL 的另一项重要特性。通过支持高达 128K tokens 的上下文输入,Kimi-VL 可以处理更长的文档和视频,从而更好地理解其中的信息。这对于需要处理大量信息的应用场景,如金融分析、法律咨询和医疗诊断,具有重要意义。
二、iFlytek Star Agent 平台:赋能 Agent 应用开发
iFlytek 近期宣布其 Star Agent 开发平台全面支持 MCP,旨在帮助开发者高效构建 Agent 应用。该平台不仅支持轻松配置和调用行业领先的 MCP 服务器,还允许一键部署自定义 MCP 服务器,实现真正的“即插即用”。首批支持的 MCP 服务器覆盖多个行业,推动了 AI 应用中间件的标准化。
iFlytek Star Agent 平台的 MCP 支持,为开发者提供了极大的便利。MCP(Model as a Compositional Primitive)是一种将 AI 模型分解为多个可组合的原始操作的技术。通过 MCP,开发者可以将复杂的 AI 任务分解为多个简单的子任务,然后使用现有的 AI 模型来完成这些子任务。这种方法可以大大降低 AI 应用的开发难度,并提高开发效率。iFlytek Star Agent 平台支持无代码和低代码创建模式,进一步降低了 AI 应用的开发门槛。无代码开发模式允许开发者通过简单的拖拽和配置,即可创建 AI 应用,而无需编写任何代码。低代码开发模式则允许开发者使用少量的代码,即可完成 AI 应用的定制和扩展。这两种模式都极大地降低了 AI 应用的开发难度,使得更多的人可以参与到 AI 应用的开发中来。
三、昆仑万维 Skywork-OR1 系列模型:数学与代码能力的突破
昆仑万维的 Tiangong 团队于 4 月 13 日发布了升级后的 Skywork-OR1 系列模型,标志着在逻辑推理和复杂任务解决方面取得了重大突破。该系列包括三款高性能模型,专门针对数学和代码领域,展示了卓越的推理能力和成本效益。Skywork-OR1-32B-Preview 在竞争性编程任务中表现尤为出色,展示了其训练策略的进步。
Skywork-OR1 系列模型在数学和代码领域的卓越表现,得益于其先进的训练策略。该系列模型采用了多种训练技术,包括自监督学习、迁移学习和强化学习。自监督学习允许模型从大量的无标签数据中学习知识,迁移学习允许模型将从一个任务中学到的知识应用到另一个任务中,强化学习则允许模型通过与环境的交互来学习最优策略。这些技术使得 Skywork-OR1 系列模型能够更好地理解数学和代码,并解决复杂的问题。Skywork-OR1-32B-Preview 在竞争性编程任务中的出色表现,充分证明了其训练策略的有效性。竞争性编程任务通常需要选手具备扎实的算法基础和编程能力,以及快速解决问题的能力。Skywork-OR1-32B-Preview 在这些任务中的出色表现,表明其已经具备了相当高的智能水平。
四、ByteDance Seed-Thinking-v1.5:推理 AI 竞赛的新力量
ByteDance 新推出的大型语言模型 Seed-Thinking-v1.5 在推理 AI 竞赛中表现出了强大的能力。该模型采用了混合专家架构,在多个基准测试中超越了行业巨头,尤其是在科学、技术、数学和工程领域。通过技术创新和高效的训练方法,Seed-Thinking-v1.5 不仅提高了推理能力,还在非推理任务中表现出色。

混合专家架构是 Seed-Thinking-v1.5 的一大亮点。混合专家架构通过将模型分解为多个专家模型,每个专家模型处理不同的输入,从而在保证模型性能的同时,提高了模型的泛化能力。这种架构特别适用于处理复杂的问题,如推理和决策。ByteDance 在 Seed-Thinking-v1.5 的训练过程中,采用了多种先进的训练技术,包括自适应学习率、梯度裁剪和模型蒸馏。自适应学习率允许模型根据训练的进度,自动调整学习率,从而提高训练效率。梯度裁剪可以防止梯度爆炸,从而保证训练的稳定性。模型蒸馏则可以将大型模型的知识迁移到小型模型中,从而提高小型模型的性能。
五、SenseTime SenseCore 2.0:AI 基础设施的全面升级
在 2025 SenseTime 技术交流日上,SenseTime 宣布全面升级其 SenseCore 2.0 大型 AI 基础设施,旨在为企业提供高效灵活的全栈 AI 基础设施服务。此次升级解决了大型模型行业的三个主要挑战,并通过技术创新显着提高了计算能力利用率和推理性能。此外,SenseTime 还投入了 1 亿元的专项代金券,以帮助各行业加速 AI 实施。

SenseCore 2.0 的全面升级,为 AI 基础设施带来了质的飞跃。SenseCore 2.0 采用了多种先进的技术,包括异构计算、弹性调度和智能存储。异构计算允许 SenseCore 2.0 利用不同类型的计算资源,如 CPU、GPU 和 FPGA,从而提高计算效率。弹性调度允许 SenseCore 2.0 根据用户的需求,动态分配计算资源,从而提高资源利用率。智能存储则可以根据数据的访问模式,自动调整存储策略,从而提高存储效率。SenseTime 还与 Songying Technology 建立了战略合作伙伴关系,以促进具身智能技术的发展,并解决智能实施的挑战。具身智能是一种将 AI 技术与物理世界相结合的技术。通过具身智能,AI 系统可以更好地理解物理世界,并与物理世界进行交互。
六、Google AI Studio Veo 2 视频模型:开启有限免费试用
Google AI Studio 近期向部分用户开放了 Veo 2 视频模型的有限免费试用,引起了广泛关注。Veo 2 是最新一代 AI 视频生成工具,支持高达 4K 的分辨率和逼真的物理模拟,展示了其强大的技术能力。然而,试用访问受到严格限制,用户对冷却时间和未来使用情况感到不确定。

Veo 2 视频模型的推出,标志着 AI 视频生成技术进入了一个新的阶段。Veo 2 采用了多种先进的技术,包括生成对抗网络、Transformer 和神经渲染。生成对抗网络允许 Veo 2 生成逼真的视频,Transformer 可以捕捉视频中的长期依赖关系,神经渲染则可以生成高质量的图像。Google 对 Veo 2 生成的内容进行了严格的控制,以确保用户隐私和安全。Google 采用了多种技术,包括水印、内容过滤和人工审核,以防止 Veo 2 生成有害的内容。
七、Shanghai AI Lab InternVL3 系列多模态大语言模型:开源赋能
OpenGVLab 于 4 月 11 日发布了 InternVL3 系列模型,标志着多模态大语言模型领域的一个新里程碑。该系列包括从 1B 到 78B 参数的各种尺寸的模型,能够处理文本、图像和视频,并且性能显着提高。与之前的版本相比,InternVL3 在多模态感知和推理方面取得了重大进展,扩展了工具使用、工业图像分析等方面的能力。
InternVL3 系列模型的发布,为多模态大语言模型的研究和应用提供了新的动力。InternVL3 采用了多种先进的技术,包括多模态 Transformer、对比学习和知识蒸馏。多模态 Transformer 允许 InternVL3 同时处理文本、图像和视频,对比学习可以提高 InternVL3 的多模态感知能力,知识蒸馏则可以将大型模型的知识迁移到小型模型中,从而提高小型模型的性能。该模型可以通过 LMDeploy 的 api_server 部署为与 OpenAI 兼容的 API,允许用户轻松调用该模型。
八、GAIA 基准:AI“智商”测试的革命
随着 AI 技术的快速发展,准确评估 AI 的智能水平已成为一个关键的行业问题。传统的评估基准(如 MMLU)虽然被广泛使用,但越来越显示出局限性,无法完全反映 AI 在实际应用中的能力。新推出的 GAIA 基准模拟了复杂的现实世界问题,强调 AI 在多步骤任务中的灵活性和专业性,标志着 AI 评估方法的一个重大转变。
GAIA 基准的推出,为 AI 评估提供了一个新的视角。GAIA 基准的目标是评估 AI 在解决复杂现实世界问题时的能力。这些问题通常需要 AI 系统具备多种能力,包括多模态理解、复杂推理和知识应用。GAIA 基准的初始结果表明,灵活的模型在复杂任务中优于其他知名模型。这表明,在解决复杂现实世界问题时,模型的灵活性比模型的大小更重要。
九、Pusa:百元开源视频模型
Pusa 是一款基于 Mochi 微调的开源视频生成模型,具有低成本和完全开源的特点。Pusa 的训练成本约为 100 美元,展示了良好的视频生成能力,支持各种生成任务。其开放的微调过程促进了社区协作和开发,吸引了更多的研究人员参与视频模型研究。
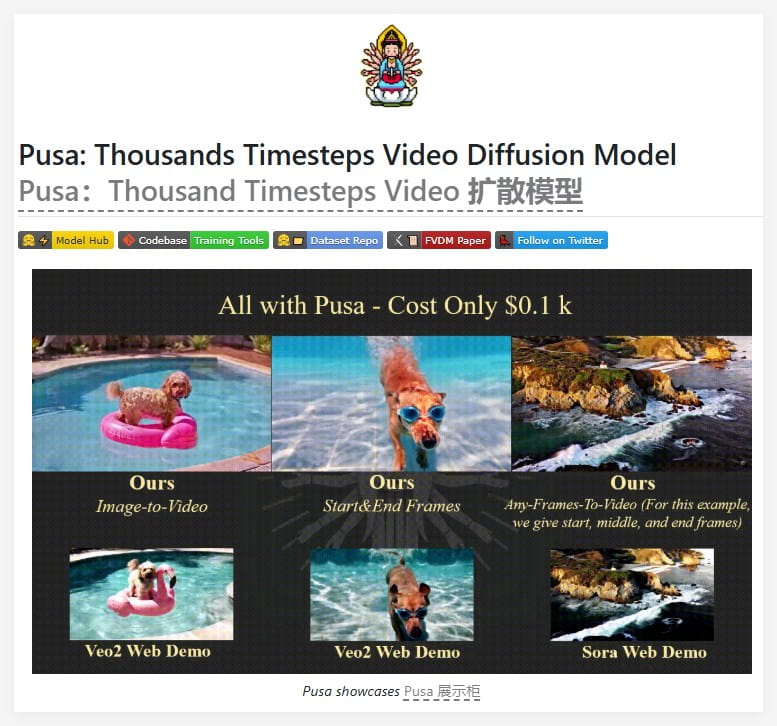
Pusa 模型的推出,为低成本视频生成提供了一种新的解决方案。Pusa 基于 Mochi 微调,Mochi 是一种轻量级的 Transformer 架构,可以高效地进行微调。Pusa 的训练成本仅为 100 美元,远低于传统的大型视频模型,这使得更多的研究人员和开发者可以参与到视频模型的研究中来。Pusa 是完全开源的,这促进了社区协作和开发。研究人员可以自由地访问 Pusa 的代码和数据,并在此基础上进行创新。
十、ByteDance UNO:保持角色和对象一致性的图像生成
ByteDance 的开源项目 UNO 在 AI 图像生成方面取得了重大突破,解决了生成图像中角色或对象不一致的问题。通过创新的高一致性数据合成过程和模型设计,UNO 确保生成的图像保持一致的特征,无论是在单主题还是多主题场景中。

UNO 项目的推出,为解决 AI 图像生成中的一致性问题提供了一种新的方法。UNO 使用了一种高一致性的数据合成过程,该过程可以生成具有一致特征的图像。UNO 还采用了一种创新的模型设计,该设计可以确保生成的图像保持一致的特征。UNO 支持单主题和多主题场景,这使得 UNO 可以应用于各种图像生成任务。
十一、XPeng Motors 物理大模型:定位为 AI 汽车公司
XPeng Motors 创始人 He Xiaopeng 在社交媒体上强调了该公司作为 AI 汽车公司的定位,认为人工智能的最大价值在于改变物理世界。他透露了 XPeng 在自动驾驶方面的创新技术,特别是强化学习和模型蒸馏,使其在该行业中具有独特的竞争优势。此外,XPeng 正在训练一个超大规模的物理世界模型,这标志着其在 AI 技术应用方面的领先地位。

XPeng Motors 将自己定位为 AI 汽车公司,表明其对 AI 技术的重视。XPeng Motors 正在训练一个超大规模的物理世界模型,该模型可以模拟物理世界的各种现象。通过这个模型,XPeng Motors 可以更好地理解物理世界,并开发出更先进的自动驾驶技术。XPeng Motors 还在自动驾驶方面采用了强化学习和模型蒸馏技术。强化学习可以使自动驾驶系统通过与环境的交互来学习最优策略,模型蒸馏则可以将大型模型的知识迁移到小型模型中,从而提高小型模型的性能。
十二、ByteDance AI 智能眼镜:可穿戴设备市场的挑战者
ByteDance 正在积极开发一款 AI 智能眼镜产品,旨在将先进的 AI 功能与高质量的图像捕捉相结合,以提供创新的用户体验。该设备将集成 ByteDance 自行开发的“Doubao”AI 模型,从而增强智能交互能力。用户可以通过语音命令和其他方法与眼镜进行交互。该项目已进入实质性的研发阶段,ByteDance 正在与供应链合作伙伴沟通,以推动产品设计和发布计划。

ByteDance 正在开发 AI 智能眼镜,表明其对可穿戴设备市场的兴趣。ByteDance 的 AI 智能眼镜将集成“Doubao”AI 模型,该模型可以提供语音命令、实时翻译和其他智能交互功能。ByteDance 正在与供应链合作伙伴沟通,以推动产品设计和发布计划。这表明 ByteDance 正在认真对待 AI 智能眼镜项目,并希望尽快将其推向市场。
总的来说,AI 领域的这些最新进展,无论是模型开源、平台升级还是新产品的推出,都预示着 AI 技术将更加深入地渗透到各个行业和我们的日常生活中。我们有理由期待,在 AI 技术的驱动下,未来的世界将更加智能化、便捷化。








