
在人工智能领域,视觉语言模型(Vision-Language Models,VLMs)正变得日益重要。它们不仅能够理解图像和视频内容,还能通过自然语言进行交互,为各种应用场景带来了革命性的变革。蚂蚁集团和中国人民大学联合推出的ViLAMP(Video-Language Model with Mixed Precision),正是一款专注于高效处理长视频内容的创新模型。本文将深入探讨ViLAMP的技术原理、功能特点、应用场景,并分析其在长视频理解方面的优势。
ViLAMP:长视频理解的新星
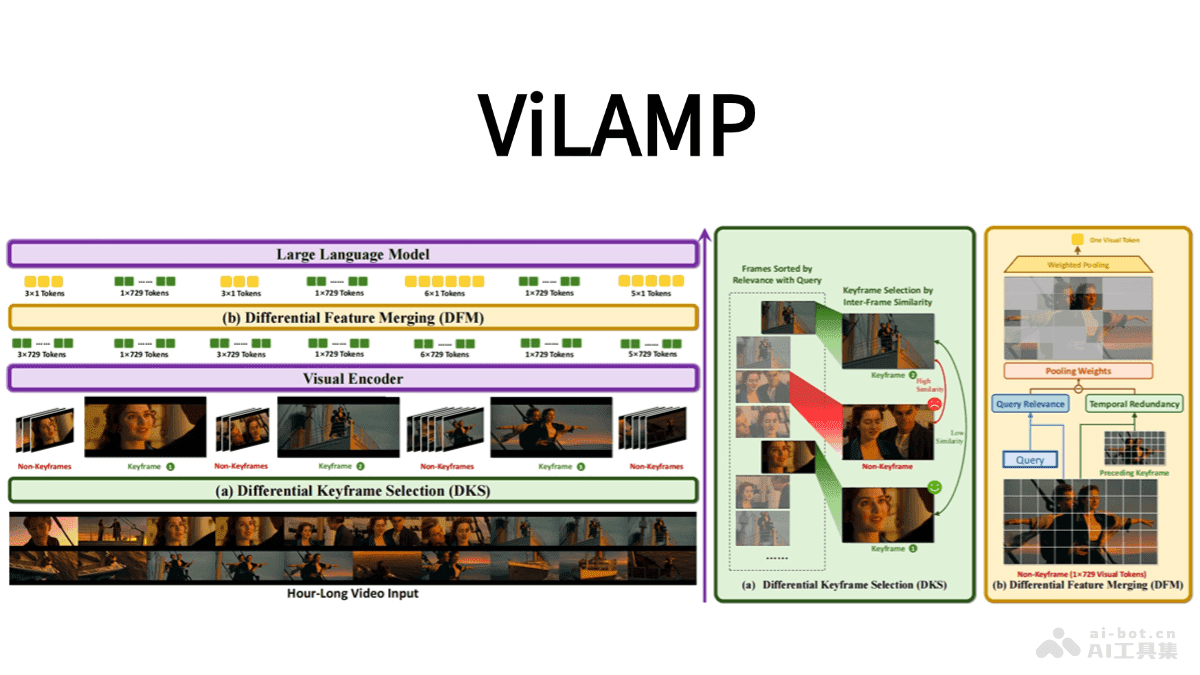
ViLAMP模型的核心在于其混合精度策略,这种策略允许模型在处理视频时,对关键帧保持高精度分析,而对其他帧进行压缩处理,从而显著降低计算成本,提高处理效率。这种方法特别适用于处理长视频,因为长视频通常包含大量的冗余信息,对所有帧都进行高精度分析会消耗大量的计算资源。
与传统的视频理解模型相比,ViLAMP在多个视频理解基准测试中表现出色,尤其是在长视频理解任务中,展现出显著优势。它能够在单张A100 GPU上处理长达1万帧(约3小时)的视频,同时保持稳定的理解准确率,这为长视频分析提供了一个新的解决方案。
ViLAMP的主要功能
ViLAMP模型的主要功能集中在长视频理解和高效计算上,具体包括以下几个方面:
- 长视频理解:ViLAMP的设计目标就是处理长达数小时的视频,这使得它能够应用于各种需要长时间视频分析的场景,例如在线教育、视频监控和影视制作。
- 关键信息提取:模型能够精准地提取视频中的关键信息,同时压缩冗余信息。这意味着ViLAMP可以快速地找到视频中的重点内容,而无需处理大量的无用信息。
- 高效计算:ViLAMP能够在单张A100 GPU上处理长达1万帧的视频,这得益于其混合精度策略和优化的算法。这种高效的计算能力使得ViLAMP能够在大规模视频数据上进行实时分析。
- 多任务处理:ViLAMP支持多种视频理解任务,如视频内容问答、动作识别、场景理解等。这意味着它可以被用于各种不同的应用场景,而不仅仅是单一的任务。
ViLAMP的技术原理
ViLAMP的技术原理主要包括差分关键帧选择和差分特征合并两个方面:
差分关键帧选择:ViLAMP使用基于贪心算法的关键帧选择策略,选择与用户查询高度相关且具有时间多样性的关键帧。这种策略确保选中的关键帧既能捕捉重要信息,又能避免冗余。
具体来说,该算法首先会计算每一帧与用户查询的相关性得分,然后选择得分最高的帧作为第一个关键帧。接下来,它会迭代地选择下一个关键帧,每次选择时都会考虑新帧与已选关键帧之间的差异性,以确保选出的关键帧能够覆盖视频中的所有重要信息。
这种差分关键帧选择策略的优势在于,它能够有效地减少需要处理的帧数,从而降低计算成本。同时,由于选出的关键帧都是与用户查询相关的,因此可以提高视频理解的准确率。
差分特征合并:ViLAMP对非关键帧进行压缩,将每个非关键帧的多个patch合并为单个token。这种压缩是通过差分加权池化实现的,该方法赋予与用户查询相关且具有独特性的patch更高的权重,同时降低与关键帧重复的patch的权重。
具体来说,该方法首先会将每个非关键帧分割成多个patch,然后计算每个patch与用户查询的相关性得分。接下来,它会使用这些得分作为权重,对patch进行加权池化,从而得到一个代表整个非关键帧的token。
这种差分特征合并策略的优势在于,它能够在保留关键信息的同时,显著减少计算量。通过将多个patch合并为单个token,ViLAMP可以大大减少需要处理的数据量,从而提高计算效率。
ViLAMP的应用场景
ViLAMP的应用场景非常广泛,以下是一些典型的例子:
在线教育:ViLAMP可以快速提取教育视频中的重点内容,生成摘要或回答学生问题。例如,它可以自动识别视频中的关键概念、公式和实验步骤,并生成一个包含这些信息的摘要。此外,ViLAMP还可以回答学生关于视频内容的问题,例如“这个公式是如何推导出来的?”或“这个实验的目的是什么?”
通过这种方式,ViLAMP可以帮助学生更有效地学习视频课程,提高学习效率。
视频监控:ViLAMP可以实时分析监控视频,检测异常事件并及时报警。例如,它可以识别视频中的异常行为,如打架、盗窃和火灾,并立即向监控人员发出警报。
这种实时分析能力可以帮助提高安全性,减少犯罪率。
直播分析:ViLAMP可以实时处理直播内容,提取亮点或回答观众问题。例如,它可以自动识别直播中的精彩瞬间,如高潮迭起的比赛、引人发笑的段子和感人至深的故事,并将这些瞬间Highlight出来。此外,ViLAMP还可以回答观众关于直播内容的问题,例如“这个选手是谁?”或“这个游戏怎么玩?”
通过这种方式,ViLAMP可以提高直播的互动性和趣味性,吸引更多的观众。
影视制作:ViLAMP可以帮助编辑和导演筛选素材,提取关键场景,提高制作效率。例如,它可以自动识别视频中的关键场景,如动作场面、对话场面和风景场面,并将这些场景提取出来,供编辑和导演使用。此外,ViLAMP还可以根据剧本自动生成剪辑方案,帮助编辑和导演更快地完成剪辑工作。
通过这种方式,ViLAMP可以大大缩短影视制作周期,降低制作成本。
智能客服:ViLAMP可以自动回答用户关于视频内容的问题,提升用户体验。例如,当用户观看一个产品介绍视频时,ViLAMP可以自动回答用户关于产品功能、使用方法和售后服务的问题。
通过这种方式,ViLAMP可以提高客户满意度,降低客服成本。
ViLAMP的优势与挑战
ViLAMP在长视频理解方面具有显著优势,这主要体现在以下几个方面:
- 高效性:ViLAMP的混合精度策略和优化的算法使其能够高效地处理长视频,降低计算成本。
- 准确性:ViLAMP的关键帧选择和特征合并策略使其能够准确地提取视频中的关键信息,提高视频理解的准确率。
- 通用性:ViLAMP支持多种视频理解任务,可以应用于各种不同的应用场景。
然而,ViLAMP也面临着一些挑战,例如:
- 模型复杂度:ViLAMP的模型结构相对复杂,需要大量的训练数据和计算资源。
- 鲁棒性:ViLAMP在处理低质量或噪声视频时,可能会出现性能下降的情况。
- 可解释性:ViLAMP的决策过程相对难以解释,这可能会影响其在某些领域的应用。
总结与展望
ViLAMP作为蚂蚁集团和中国人民大学联合推出的视觉语言模型,为长视频理解提供了一个新的解决方案。它通过混合精度策略、差分关键帧选择和差分特征合并等技术,实现了高效、准确和通用的视频理解能力。虽然ViLAMP还面临着一些挑战,但随着技术的不断发展,相信它将在未来的视频理解领域发挥越来越重要的作用。
未来,我们可以期待ViLAMP在以下几个方面取得更大的突破:
- 模型压缩:进一步优化模型结构,减少模型参数,降低计算成本。
- 鲁棒性提升:提高模型对低质量和噪声视频的鲁棒性,使其能够适应更复杂的应用场景。
- 可解释性增强:研究可解释的视频理解方法,提高模型决策过程的可解释性,使其能够更好地服务于人类。









