
在人工智能领域,视觉编码器扮演着至关重要的角色,它们是连接图像和文本理解的桥梁。近日,加州大学圣克鲁兹分校发布了OpenVision,这是一个全新的视觉编码器系列,旨在为开发者和企业提供除OpenAI的CLIP和Google的SigLIP之外的更灵活、高效的选择。OpenVision的发布,无疑为图像处理和理解领域注入了新的活力。

视觉编码器的核心作用
视觉编码器是一种AI模型,其主要功能是将视觉材料(通常是静态图像)转换为数值数据,这种数据可以被其他非视觉模型(如大型语言模型)所理解。换句话说,视觉编码器让大型语言模型能够识别图像中的主题、颜色、位置等特征,从而实现更复杂的推理和交互。这种能力对于许多应用场景至关重要,例如图像搜索、自动驾驶、医疗诊断等。
OpenVision的发布,正是为了满足日益增长的对高效、灵活的视觉编码器的需求。它不仅提供了多种模型选择,还优化了部署架构,使其能够适应不同的应用场景。
OpenVision的关键特性解析
OpenVision之所以备受关注,在于其拥有的多项关键特性,这些特性使其在众多视觉编码器中脱颖而出:
- 模型多样性:满足不同场景需求
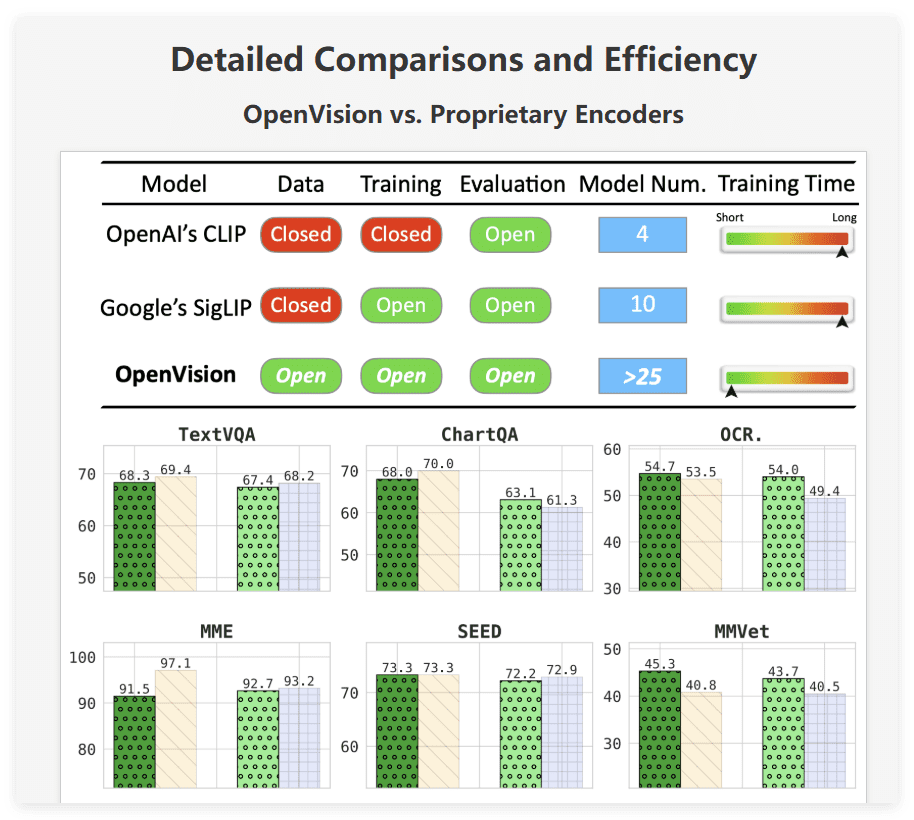
OpenVision提供了26种不同的模型,参数规模从590万到6.32亿不等。这种多样性使得开发者可以根据具体的应用场景选择合适的模型。例如,在需要高精度和详细视觉理解的服务器级工作负载中,可以选择较大的模型;而在计算和内存资源有限的边缘计算环境中,则可以选择较小的模型。这种灵活性使得OpenVision能够广泛应用于各种场景,例如建筑工地的图像识别、家用电器的故障排除指导等。
考虑到实际应用中,不同场景对模型大小、计算资源的需求各不相同。OpenVision的多样化模型选择,能够有效避免资源浪费,提升整体效率。例如,对于移动设备上的实时图像处理,小型模型可以保证流畅的用户体验;而对于需要进行复杂分析的场景,大型模型则可以提供更高的准确性。
- 灵活的部署架构:适应各种使用场景
OpenVision的设计充分考虑了不同使用场景的需求。大型模型适用于服务器级别的工作负载,需要高精度和详细的视觉理解;而较小的模型则针对边缘计算进行了优化,适用于计算和内存资源有限的环境。此外,OpenVision还支持自适应patch sizes(8×8和16×16),从而可以在细节分辨率和计算负载之间进行灵活的权衡。
这种灵活的部署架构,使得OpenVision能够无缝集成到各种应用中。例如,在智能监控系统中,可以使用较小的模型进行实时视频分析,并在检测到异常情况时,将图像发送到服务器进行更详细的分析。这种分层处理的方式,可以有效降低网络带宽和计算资源的消耗。
- 卓越的多模态基准性能:超越传统评估标准
OpenVision在一系列基准测试中表现出色,尤其是在各种视觉-语言任务中。值得注意的是,OpenVision的评估虽然包括传统的CLIP基准(如ImageNet和MSCOCO),但研究团队强调,不应仅仅依赖这些指标来评估模型性能。他们建议采用更广泛的基准覆盖和开放评估协议,以更好地反映真实世界的多模态应用。
这种观点反映了当前AI领域对模型评估的深刻反思。传统的基准测试往往侧重于特定数据集和任务,难以全面反映模型在实际应用中的性能。OpenVision团队提倡的更广泛的基准覆盖和开放评估协议,有助于更客观、全面地评估模型的性能,从而推动AI技术的进步。
- 高效的渐进式训练策略:加速模型训练过程
OpenVision采用了一种渐进式分辨率训练策略,即模型首先在低分辨率图像上进行训练,然后逐渐微调到更高的分辨率。这种方法可以提高训练效率,通常比CLIP和SigLIP快2到3倍,同时不牺牲下游性能。
渐进式训练策略的优势在于,它可以在早期阶段快速学习图像的基本特征,然后在后期阶段逐步优化细节。这种方法可以有效避免模型陷入局部最优解,从而提高模型的泛化能力。此外,由于低分辨率图像的计算成本较低,因此可以显著缩短训练时间。
- 优化的轻量级系统和边缘计算应用:赋能小型语言模型
OpenVision还致力于与小型语言模型有效结合。在一个实验中,该视觉编码器与一个具有150万参数的Smol-LM模型相结合,创建了一个总参数数量低于250万的多模态模型。尽管体积很小,但该模型在视觉问答和文档理解等任务中保持了良好的准确性。
这种轻量级的设计使得OpenVision能够部署在资源有限的设备上,例如移动设备、嵌入式系统等。结合小型语言模型,可以实现各种智能应用,例如智能家居控制、智能客服等。这种趋势表明,未来的AI模型将更加注重效率和可移植性。
企业应用的战略意义
OpenVision全面的开源和模块化开发方法对企业技术决策者具有重要的战略意义。它不仅为大型语言模型提供了即插即用的高性能视觉能力,还确保了企业专有数据的机密性。此外,OpenVision透明的架构使得安全团队能够监控和评估模型中潜在的漏洞。
对于企业而言,数据安全至关重要。OpenVision的开源特性使得企业可以对其进行定制和审计,从而确保数据的安全性和隐私性。此外,模块化的设计使得企业可以根据自身需求选择不同的组件,从而构建定制化的解决方案。
OpenVision的模型库现在以PyTorch和JAX实现提供,可以从Hugging Face下载。训练配方也已公开。通过提供透明、高效和可扩展的替代方案,OpenVision为研究人员和开发人员提供了一个灵活的基础,以推动视觉-语言应用程序的开发。
案例分析:OpenVision在智能零售中的应用
假设一家大型零售企业希望利用AI技术提升客户体验和运营效率。他们可以采用OpenVision构建一个智能零售系统,该系统可以实现以下功能:
- **智能商品识别:**通过OpenVision,系统可以自动识别商品种类、品牌、价格等信息,无需人工扫描条形码,提高收银效率。
- **客流分析:**通过分析摄像头捕捉的图像,系统可以了解顾客的购物行为、偏好等信息,为商品陈列和营销策略提供数据支持。
- **防盗监控:**通过OpenVision,系统可以识别可疑行为,例如盗窃、破坏等,及时发出警报,降低损失。
在这个案例中,企业可以选择适合自身需求的OpenVision模型,并对其进行定制和优化。例如,对于客流分析,可以选择一个较小的模型,以降低计算成本;而对于防盗监控,则可以选择一个较大的模型,以提高准确性。通过OpenVision,企业可以构建一个高效、智能的零售系统,提升客户体验和运营效率。
OpenVision的未来展望
OpenVision的发布,标志着视觉编码器领域进入了一个新的发展阶段。未来,我们可以期待OpenVision在以下几个方面取得更大的突破:
- **更高的精度和效率:**随着算法和硬件的不断发展,OpenVision的精度和效率将不断提高,从而能够处理更复杂的视觉任务。
- **更广泛的应用场景:**OpenVision将被应用于更多的领域,例如自动驾驶、医疗诊断、智能制造等,为各行各业带来变革。
- **更强的可解释性:**未来的OpenVision将更加注重可解释性,从而让人们更容易理解其工作原理,并对其进行信任和控制。
总之,OpenVision的发布,为视觉编码器领域带来了新的希望。它不仅提供了更灵活、高效的选择,还推动了AI技术的进步。我们有理由相信,在OpenVision的推动下,视觉-语言应用程序将会迎来更加美好的未来。





