
DICE-Talk是由复旦大学和腾讯优图实验室联合推出的情感化动态肖像生成框架,它为数字人、虚拟助手等应用带来了全新的可能性。该框架能够根据输入的音频和参考图像,生成具有生动情感表达并且保持身份一致性的动态肖像视频。本文将深入探讨DICE-Talk的技术原理、功能、应用场景及其潜在价值。
DICE-Talk的核心功能与特点
DICE-Talk的核心在于其情感化动态肖像生成能力。简单来说,它能够让静态的照片“活”起来,并且赋予其各种情感。不同于以往的技术,DICE-Talk在生成情感化视频的同时,还能保持原始人物的身份特征,避免出现身份混淆或失真。这一功能在需要高度还原人物形象的应用场景中尤为重要。
该框架生成的视频不仅在情感表达上更加自然,在视觉质量和唇部同步方面也达到了较高水平。这意味着生成的视频更逼真,更能引起观看者的共鸣。此外,DICE-Talk还具备良好的泛化能力,即使面对未曾见过的身份和情感组合,也能生成高质量的视频。
用户可以通过输入特定的情感目标来控制生成视频的情感表达,实现高度的自定义。这种用户可控性为内容创作者提供了更大的灵活性。DICE-Talk支持多种输入模态,包括音频、视频和参考图像,这使得它能够适应不同的应用场景。
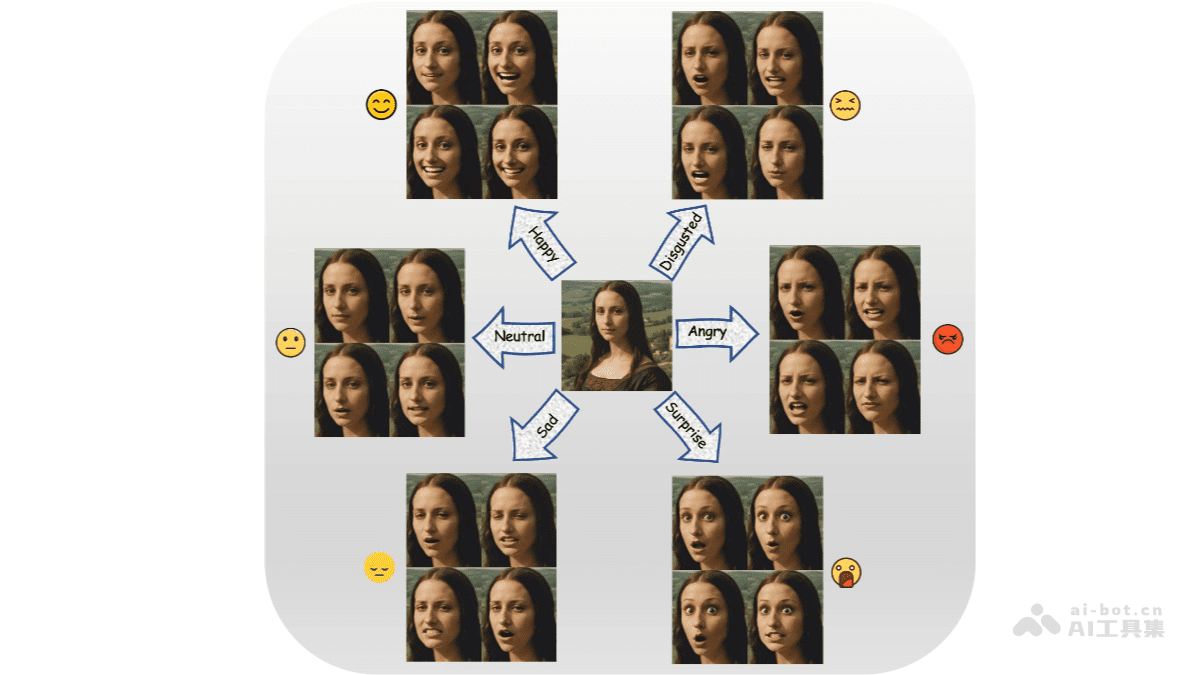
DICE-Talk的技术原理
DICE-Talk的技术原理主要包括以下几个方面:解耦身份与情感、情感关联增强、情感判别目标和扩散模型框架。
- 解耦身份与情感
为了实现情感的精准表达,DICE-Talk首先需要将身份信息和情感信息进行解耦。该框架基于跨模态注意力机制,联合建模音频和视觉情感线索,将情感表示为身份无关的高斯分布。这意味着情感的表达不再依赖于特定的身份,从而提高了情感表达的灵活性和多样性。为了进一步确保情感嵌入的准确性,DICE-Talk采用对比学习方法,例如InfoNCE损失,来训练情感嵌入器。这种训练方式使得相同情感的特征在嵌入空间中更加聚集,而不同情感的特征则更加分散,从而提高了情感识别的准确性。
- 情感关联增强
为了提升情感生成的准确性和多样性,DICE-Talk引入了情感关联增强模块。该模块的核心是一个情感库,用于存储多种情感的特征表示。情感库通过向量量化和基于注意力的特征聚合来学习情感之间的关系。这意味着模型不仅能够识别和表达单一的情感,还能理解不同情感之间的细微差别和联系。情感库的学习过程有助于模型更好地生成各种复杂的情感表达。
- 情感判别目标
为了确保生成视频的情感一致性,DICE-Talk设计了一个情感判别目标。该目标基于情感分类,在扩散模型的生成过程中,通过情感判别器来确保生成视频的情感表达与目标情感一致。情感判别器与扩散模型联合训练,从而保证生成的视频在情感表达上的准确性,同时保持视觉质量和唇部同步。
- 扩散模型框架
DICE-Talk采用扩散模型框架来生成目标视频。扩散模型是一种生成模型,它通过逐步去噪的方式从高斯噪声中生成目标数据。具体来说,DICE-Talk首先使用变分自编码器(VAE)将视频帧映射到潜在空间,然后在潜在空间中逐步引入高斯噪声。接着,基于扩散模型逐步去除噪声,最终生成目标视频。在去噪过程中,扩散模型基于跨模态注意力机制,结合参考图像、音频特征和情感特征,引导视频生成。这种方式使得生成的视频既能保持参考图像的身份特征,又能表达出目标情感。
DICE-Talk的应用场景
DICE-Talk的应用场景非常广泛,几乎所有需要数字人或虚拟形象的应用都可以从中受益。
- 数字人与虚拟助手:DICE-Talk可以为数字人和虚拟助手赋予丰富的情感表达能力,使它们在与用户交互时更加自然和生动,从而提升用户体验。例如,在智能客服领域,可以使用DICE-Talk生成具有不同情感表达的客服形象,根据用户的情绪调整自己的语气和表情,从而更好地服务用户。
- 影视制作:在影视特效和动画制作中,DICE-Talk可以快速生成具有特定情感的动态肖像,提高制作效率,降低制作成本。例如,在制作历史人物传记片时,可以使用DICE-Talk将历史人物的照片转化为动态视频,并且赋予其特定的情感,从而更好地还原历史场景。
- 虚拟现实与增强现实:在VR/AR应用中,DICE-Talk可以生成与用户情感互动的虚拟角色,增强沉浸感和情感共鸣。例如,在VR游戏中,可以使用DICE-Talk生成具有不同情感表达的NPC角色,根据用户的行为和选择调整自己的反应,从而提升游戏体验。
- 在线教育与培训:DICE-Talk可以创建具有情感反馈的教学视频,让学习内容更加生动有趣,提高学习效果。例如,在语言学习领域,可以使用DICE-Talk生成具有不同情感表达的 native speaker 形象,帮助学习者更好地理解和掌握语言。
- 心理健康支持:DICE-Talk可以开发情感化虚拟角色,用于心理治疗和情感支持,帮助用户更好地表达和理解情感。例如,在心理咨询领域,可以使用DICE-Talk生成具有同情心和理解力的虚拟咨询师形象,帮助用户更好地倾诉和释放情绪。
DICE-Talk的潜在价值与未来发展
DICE-Talk作为一种新型的情感化动态肖像生成框架,具有巨大的潜在价值。它不仅可以提升数字人、虚拟助手等应用的用户体验,还可以降低影视制作、VR/AR应用等行业的制作成本。随着人工智能技术的不断发展,DICE-Talk有望在未来得到更广泛的应用。
未来,DICE-Talk的发展方向可能包括以下几个方面:
- 提高生成视频的质量:虽然DICE-Talk已经能够生成高质量的视频,但仍有提升的空间。例如,可以进一步优化模型,提高视频的清晰度和流畅度,减少失真和噪点。
- 增强情感表达的多样性:目前,DICE-Talk主要支持几种常见的情感表达。未来,可以扩展情感库,增加对更多情感的支持,例如幽默、讽刺、悲伤等。
- 实现更精细的情感控制:目前,用户只能通过输入特定的情感目标来控制生成视频的情感表达。未来,可以实现更精细的情感控制,例如通过调整情感的强度、节奏和方式来生成更 nuanced 的情感表达。
- 与其他技术的融合:DICE-Talk可以与其他技术融合,例如语音识别、自然语言处理等,从而实现更智能的交互和更个性化的服务。
总结
DICE-Talk是情感化动态肖像生成领域的一项重要突破。它通过解耦身份与情感、情感关联增强、情感判别目标和扩散模型框架等技术手段,实现了高质量、高情感的动态肖像生成。DICE-Talk的应用场景非常广泛,具有巨大的潜在价值。随着技术的不断发展,DICE-Talk有望在未来得到更广泛的应用,为人们的生活带来更多便利和乐趣。








