
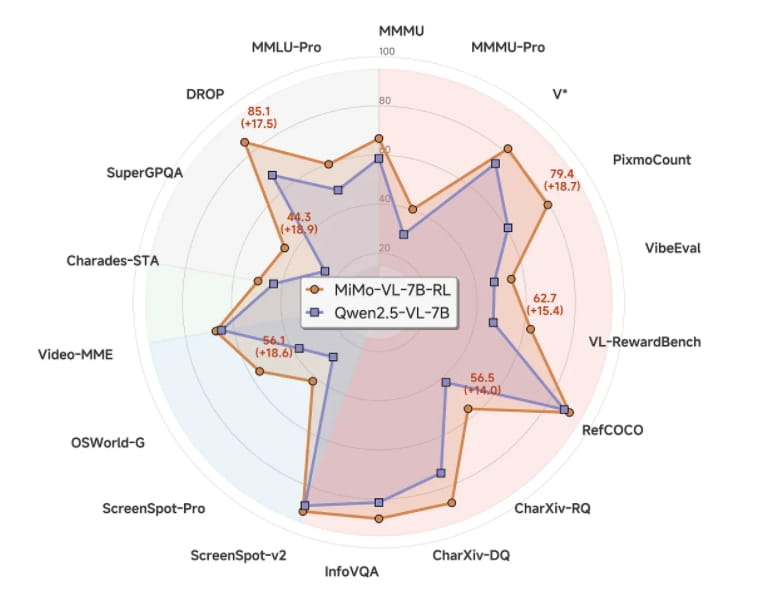
近日,小米公司开源了其最新的多模态模型MiMo-VL,再次引发了业界对于多模态人工智能的广泛关注。作为MiMo-7B的升级版本,MiMo-VL在图像、视频和语言的通用问答以及理解推理等多个任务中表现出色,超越了同等规模的标杆模型Qwen2.5-VL-7B。尤其在GUI Grounding任务中,MiMo-VL甚至可以与专用模型相媲美,为Agent时代的到来奠定了坚实的基础。
MiMo-VL-7B在多模态推理任务上的卓越表现令人印象深刻。尽管其参数规模仅为7B,但在奥林匹克竞赛(OlympiadBench)以及多个数学竞赛(MathVision、MathVerse)中,MiMo-VL-7B大幅领先于参数规模高达10倍的阿里Qwen-2.5-VL-72B和QVQ-72B-Preview。更为引人注目的是,MiMo-VL-7B甚至超越了闭源模型GPT-4o。在小米内部的大模型竞技场评估中,MiMo-VL-7B超越了GPT-4o,成为开源模型中的佼佼者。
在实际应用场景中,MiMo-VL-7B在复杂图像推理和问答方面展现出卓越的性能。同时,该模型在长达10多个步骤的GUI操作中也表现出巨大的潜力,甚至能够帮助用户将小米SU7添加到心愿单。这一能力预示着MiMo-VL-7B在自动化任务处理和人机交互方面具有广阔的应用前景。
MiMo-VL-7B之所以能够具备全面的视觉感知能力,得益于其高质量的预训练数据以及创新的混合在线强化学习算法(MORL)。在多阶段预训练过程中,小米公司收集、清洗和合成了包括图像-文本对、视频-文本对和GUI操作序列等多种数据类型的高质量多模态数据,总计2.4T tokens。通过分阶段调整不同类型数据的比例,小米有效地强化了MiMo-VL-7B的长程多模态推理能力。
混合在线强化学习(MORL)算法的引入是MiMo-VL-7B的另一大亮点。该算法融合了文本推理、多模态感知与推理以及RLHF(Reinforcement Learning from Human Feedback)等多种反馈信号,并通过在线强化学习算法稳定地加速训练过程。这种方法能够全方位地提升模型的推理能力、感知性能和用户体验。
多模态模型的崛起
近年来,随着人工智能技术的不断发展,多模态模型逐渐成为研究的热点。多模态模型旨在通过整合来自不同模态的信息,如图像、文本、音频等,从而实现对世界的更全面、更深入的理解。与传统的单模态模型相比,多模态模型具有更强的泛化能力和更好的鲁棒性,能够在各种复杂的现实场景中发挥作用。
MiMo-VL的开源,不仅展示了小米在人工智能领域的强大实力,也为多模态模型的发展注入了新的活力。通过开源,小米希望能够吸引更多的研究者和开发者参与到MiMo-VL的改进和应用中来,共同推动多模态人工智能技术的发展。
MiMo-VL的技术细节
MiMo-VL的技术架构主要包括以下几个核心组件:
- 视觉编码器:用于将输入的图像和视频数据转换为视觉特征向量。MiMo-VL采用了先进的卷积神经网络(CNN)和Transformer结构,能够有效地提取图像和视频中的关键信息。
- 文本编码器:用于将输入的文本数据转换为文本特征向量。MiMo-VL采用了预训练的语言模型,如BERT和RoBERTa,能够捕捉文本中的语义信息。
- 多模态融合模块:用于将视觉特征向量和文本特征向量融合在一起,从而得到多模态的表示。MiMo-VL采用了多种融合策略,包括注意力机制和跨模态Transformer,能够有效地整合不同模态的信息。
- 推理模块:用于根据多模态表示进行推理和预测。MiMo-VL采用了多种推理算法,包括神经网络和符号推理,能够完成各种复杂的任务。
MiMo-VL的应用前景
MiMo-VL作为一种强大的多模态模型,具有广泛的应用前景:
- 智能助手:MiMo-VL可以用于构建智能助手,能够理解用户的语音和图像输入,并提供相应的服务。例如,用户可以通过语音或图像查询天气、预订机票、查找商品等。
- 智能客服:MiMo-VL可以用于构建智能客服系统,能够理解用户的文本和图像输入,并提供相应的解答。例如,用户可以通过文本或图像咨询产品信息、售后服务等。
- 自动驾驶:MiMo-VL可以用于自动驾驶系统,能够理解车辆周围的图像和视频信息,并进行相应的决策。例如,MiMo-VL可以识别交通信号灯、车辆、行人等,并控制车辆的行驶。
- 医疗诊断:MiMo-VL可以用于医疗诊断系统,能够理解医学图像和文本信息,并辅助医生进行诊断。例如,MiMo-VL可以识别X光片、CT片、MRI片等,并诊断疾病。
- 教育领域:MiMo-VL可以用于智能教育平台,能够理解学生的学习情况,并提供个性化的辅导。例如,MiMo-VL可以分析学生的作业和考试成绩,并推荐相应的学习资源。
多模态数据的挑战与应对
尽管多模态模型具有巨大的潜力,但在实际应用中仍然面临着诸多挑战:
- 数据异构性:不同模态的数据具有不同的结构和特征,如何有效地整合这些异构数据是一个重要的挑战。MiMo-VL通过采用多种融合策略,如注意力机制和跨模态Transformer,能够有效地整合不同模态的信息。
- 模态缺失:在某些情况下,某些模态的数据可能缺失,如何在这种情况下进行有效的推理是一个挑战。MiMo-VL通过采用鲁棒的推理算法,能够在模态缺失的情况下仍然保持良好的性能。
- 计算复杂度:多模态模型的计算复杂度通常较高,如何在有限的计算资源下进行高效的训练和推理是一个挑战。MiMo-VL通过采用优化的算法和硬件加速技术,能够实现高效的训练和推理。
未来展望
随着人工智能技术的不断发展,多模态模型将在更多的领域发挥重要作用。未来,我们可以期待看到更多的创新性多模态模型出现,为人类带来更多的便利和价值。MiMo-VL的开源,无疑将加速这一进程,推动多模态人工智能技术的发展。
小米MiMo-VL的开源,不仅是小米在人工智能领域的一次重要突破,也是整个多模态人工智能领域的一次重要进展。我们有理由相信,在小米和更多研究者和开发者的共同努力下,多模态人工智能技术将迎来更加美好的未来。








