
在人工智能领域,多模态生成技术正日益成为研究和应用的热点。近日,松下控股公司联合美国松下研发公司(PRDCA)以及加州大学洛杉矶分校(UCLA)的研究人员,共同宣布了一项突破性成果——名为“OmniFlow”的多模态生成AI。这项技术最引人注目的特点是其“任意对任意”的生成能力,实现了文本、图像和音频之间的自由转换,为多模态生成AI的应用开辟了新的可能性。这一创新不仅解决了传统方法在数据获取上的局限性,还在多个评估实验中展现出卓越的性能,预示着其在未来工厂、生活方式等领域的广泛应用前景。
多模态生成AI旨在通过整合多种不同类型的数据,如文本、图像和音频,来创造更丰富、更全面的内容。近年来,随着深度学习技术的快速发展,多模态生成AI在各个领域的应用越来越广泛。尤其是在结合音频的生成技术方面,研究人员已经取得了显著的进展。然而,传统的多模态生成方法在数据获取方面面临诸多挑战。要训练一个能够同时处理文本、图像和音频数据的模型,需要大量的标注数据,这不仅耗时耗力,而且成本高昂。此外,不同模态的数据之间存在差异,如何有效地融合这些数据,也是一个亟待解决的问题。

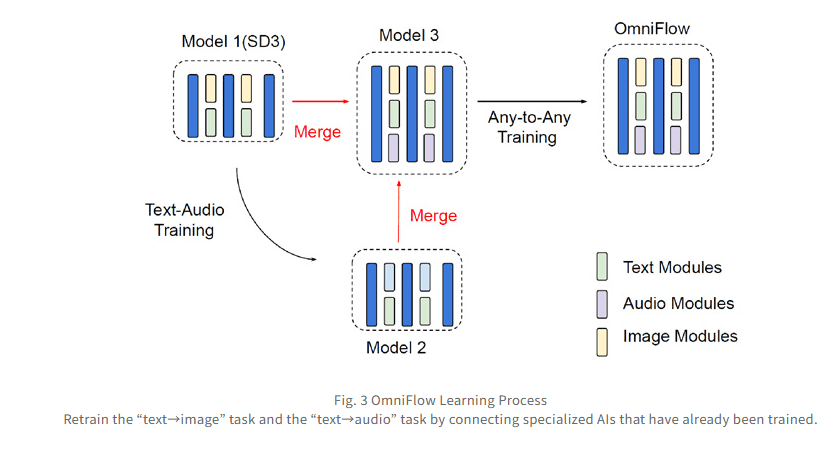
为了克服这些挑战,OmniFlow应运而生。OmniFlow的核心在于其灵活结合针对不同数据格式的生成AI,例如文本与音频、文本与图像等。这种方法使得OmniFlow即使在小样本情况下,也能够学习到高精度的“任意对任意”模型,从而显著降低了数据采集的成本。这意味着,研究人员不再需要花费大量的时间和金钱来收集和标注数据,就能够训练出一个强大的多模态生成模型。这一突破对于推动多模态生成AI的普及和应用具有重要意义。
OmniFlow的技术创新不仅体现在其灵活的数据处理能力上,还体现在其独特的数据关系学习方法上。传统的模型通常采用平均处理的方式来融合不同模态的数据,这种方法简单粗暴,容易丢失各模态的独特性。而OmniFlow则能够通过连接和处理三种不同的数据特征,学习更为复杂的数据关系。这种方法使得OmniFlow在生成过程中不仅能够保留各模态的特点,还能够提升表达能力,从而生成更具创意和表现力的内容。
松下控股公司表示,OmniFlow的技术创新已经获得了国际认可,并将在2025年计算机视觉与模式识别会议(CVPR)上进行展示。CVPR是计算机视觉领域最顶级的国际会议之一,OmniFlow能够在CVPR上亮相,充分证明了其技术实力和创新性。
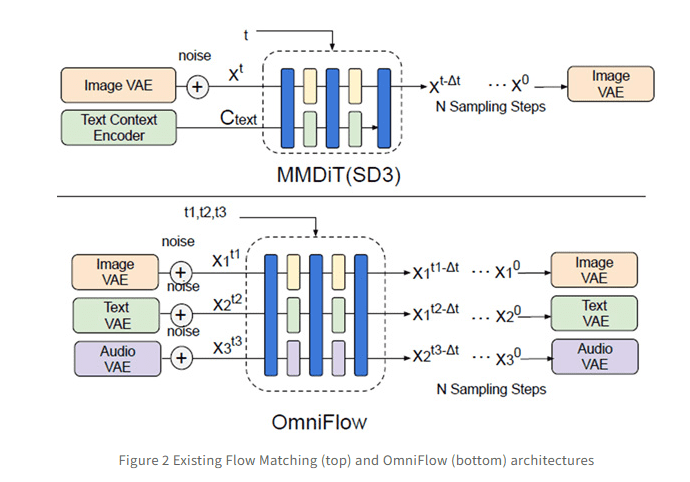
为了验证OmniFlow的性能,研究人员进行了一系列的评估实验。在“文本转图像”和“文本转音频”的生成任务中,OmniFlow的表现均优于其他传统方法,展现出最佳的性能。实验结果表明,与其他“任意对任意”生成方法相比,OmniFlow所需的训练数据量可减少至1/60。这一显著的优势使得OmniFlow在多模态AI领域脱颖而出。这意味着,OmniFlow不仅能够降低数据采集的成本,还能够提高模型的训练效率,从而加速多模态生成AI的应用。
OmniFlow在多个领域的应用前景广阔。在工厂领域,OmniFlow可以用于生成各种专门针对特定场景的数据,例如产品设计图、生产流程图、设备维护手册等。这些数据可以帮助工厂提高生产效率、降低生产成本、提升产品质量。例如,通过将文本描述转化为图像,设计师可以快速地生成产品原型,从而加快产品开发周期。通过将文本指令转化为音频,工人可以更加方便地操作设备,从而提高生产效率。在生活方式领域,OmniFlow可以用于生成各种个性化的内容,例如定制音乐、个性化壁纸、智能家居控制界面等。这些内容可以帮助用户提升生活品质、享受更加便捷的生活体验。例如,用户可以通过输入一段文字描述,生成一首符合自己心情的音乐。用户可以通过上传一张照片,生成一张与照片风格相符的个性化壁纸。
松下控股公司表示,将继续推动AI的社会化应用,致力于开发能够为客户生活与工作带来便利的AI技术。OmniFlow的成功开发,是松下控股公司在AI领域的重要里程碑。未来,松下控股公司将继续加大在AI领域的投入,不断推出更多创新性的AI产品和服务,为社会发展做出更大的贡献。
总的来说,松下OmniFlow多模态生成AI的问世,为人工智能领域注入了新的活力。其“任意对任意”的生成能力,不仅突破了传统方法的局限性,还在多个评估实验中展现出卓越的性能。随着OmniFlow在工厂、生活方式等领域的广泛应用,我们有理由相信,它将为人类的生活和工作带来更多的便利和惊喜。让我们拭目以待,OmniFlow在未来的发展中,能够创造出更加辉煌的成就。








