
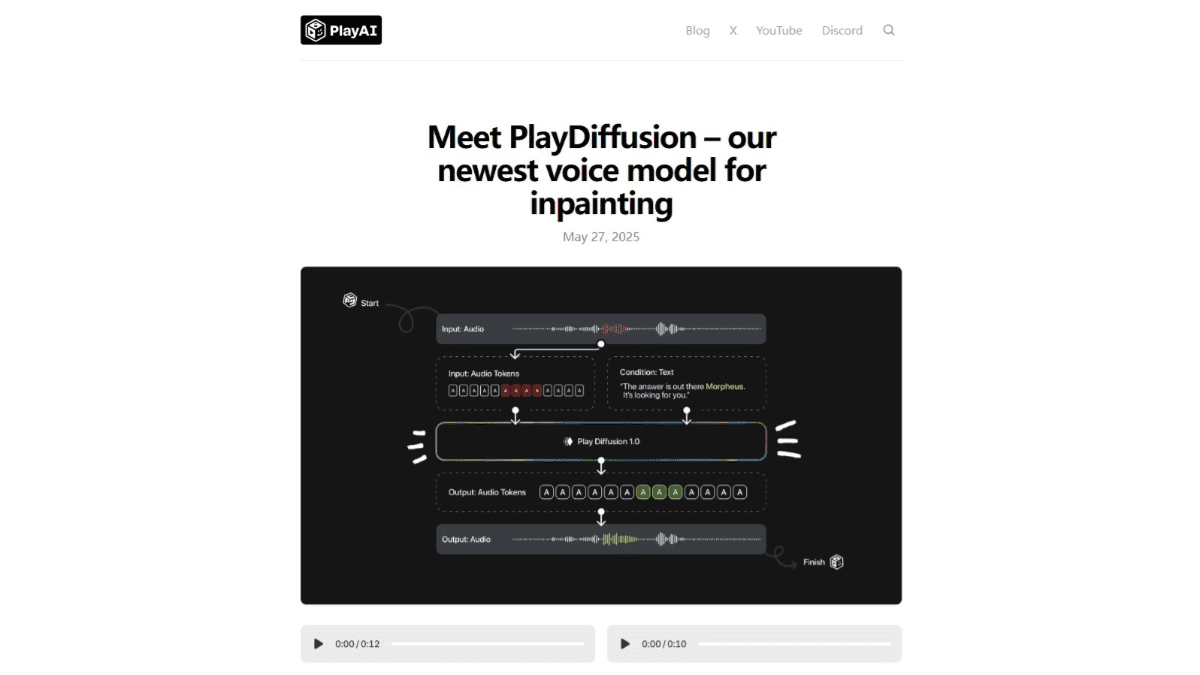
Play AI 推出了名为 PlayDiffusion 的音频编辑模型,它基于扩散模型技术,专为音频的精细编辑和修复而设计。该模型通过将音频编码为离散的标记序列,并对需要修改的部分进行掩码处理,然后利用扩散模型在给定更新文本的条件下对掩码区域进行去噪,从而实现高质量的音频编辑。这种方法能够无缝保留上下文,确保语音的连贯性和自然性,同时支持高效的文本到语音合成。PlayDiffusion 的非自回归特性在生成速度和质量上均优于传统的自回归模型,为音频编辑和语音合成领域带来了新的突破。
音频编辑技术的演进历程,从最初的简单剪切和粘贴,到现在的精细化编辑和修复,每一步都伴随着算法的革新和技术的进步。PlayDiffusion 的出现,无疑是将音频编辑技术推向了一个新的高度。它不仅仅是一个工具,更是一种理念的革新,将人工智能与音频处理深度融合,为用户提供了前所未有的编辑体验。
PlayDiffusion 的核心功能
PlayDiffusion 具备以下几项核心功能,这些功能共同构成了其强大的音频编辑能力:
- 音频局部编辑:该功能允许用户对音频进行局部替换、修改或删除,而无需重新生成整段音频。这不仅节省了时间,还确保了语音的自然和无缝衔接。例如,在一段访谈录音中,如果发现某个词语使用不当,可以使用该功能快速替换,而不会影响整个录音的流畅性。
- 高效 TTS:当掩码整个音频时,PlayDiffusion 可以作为一个高效的 TTS(文本到语音)模型使用。其推理速度比传统 TTS 提高 50 倍,同时保证了语音的自然度和一致性。这项功能在需要快速生成大量语音内容的场景中非常有用,例如自动化语音播报、智能客服等。
- 保持语音连贯性:在编辑过程中,PlayDiffusion 能够保留上下文信息,确保语音的连贯性和说话者音色的一致性。这意味着在修改音频时,不会出现声音突变或音色不一致的情况,从而保证了听觉体验的自然流畅。例如,在一段长篇小说的朗读音频中,即使对部分内容进行了修改,听众也难以察觉。
- 动态语音修改:该功能可以根据新的文本自动调整语音的发音、语气和节奏,适用于实时互动等场景。例如,在语音聊天机器人中,可以根据用户的提问动态调整回答的语气,使对话更加自然流畅。
- 无缝集成与易用性:PlayDiffusion 支持 Hugging Face 集成和本地部署,方便用户快速体验和使用。这意味着用户可以轻松地将 PlayDiffusion 集成到自己的项目中,或者在本地环境中运行,从而满足不同的需求。
PlayDiffusion 的技术原理
PlayDiffusion 的技术原理主要包括以下几个方面:
- 音频编码:将输入的音频序列编码为离散的标记序列,每个标记代表音频的一个单元。这种编码方式适用于真实语音和由文本到语音模型生成的音频。音频编码是音频处理的基础,它将连续的音频信号转换为计算机可以处理的离散数据。
- 掩码处理:当需要修改音频的某个部分时,将该部分标记为掩码,便于后续处理。掩码处理是局部编辑的关键,它允许模型只关注需要修改的部分,而忽略其他部分。
- 扩散模型去噪:基于更新文本的扩散模型对掩码区域进行去噪。扩散模型通过逐步去除噪声,生成高质量的音频标记序列。采用非自回归方法,同时生成所有标记,并基于固定数量的去噪步骤进行细化。扩散模型是 PlayDiffusion 的核心,它能够生成高质量的音频。
扩散模型(Diffusion Model)是一种生成模型,其核心思想是通过逐步添加噪声将数据转换为纯噪声,然后学习如何逆转这个过程,从噪声中恢复出原始数据。在音频编辑领域,扩散模型可以用于生成新的音频片段,修复损坏的音频,或者修改现有的音频内容。
扩散模型的工作原理可以分为两个阶段:前向扩散过程和反向扩散过程。
前向扩散过程:在这个阶段,模型逐步向原始音频数据添加噪声,直到数据完全变成随机噪声。这个过程可以用一个马尔可夫链来描述,每一步都向数据添加少量的高斯噪声。随着时间的推移,数据逐渐失去其原始结构,最终变成纯噪声。
反向扩散过程:这个阶段是生成过程的核心。模型学习如何逆转前向扩散过程,从纯噪声中逐步恢复出原始数据。这个过程也用一个马尔可夫链来描述,每一步都从噪声中去除少量噪声,直到生成清晰的音频数据。反向扩散过程需要学习一个概率分布,用于预测每一步应该去除的噪声量。
PlayDiffusion 采用非自回归方法,这意味着模型可以同时生成所有标记,而不是像传统的自回归模型那样逐个生成。这种方法可以显著提高生成速度,并且能够更好地捕捉音频中的长程依赖关系。此外,PlayDiffusion 基于固定数量的去噪步骤进行细化,这意味着模型可以在生成过程中逐步优化音频质量,从而获得更好的效果。
- 解码为音频波形:将生成的标记序列基于 BigVGAN 解码器模型转换回语音波形,确保最终输出的语音自然且连贯。解码是将离散的标记序列转换回连续的音频信号的过程,它需要使用一个高质量的解码器模型。
BigVGAN(Big Voice Generative Adversarial Network)是一种用于生成高质量音频的生成对抗网络。它由生成器和判别器组成,生成器负责生成音频,判别器负责判断生成的音频是否逼真。通过生成器和判别器的对抗训练,BigVGAN 可以生成非常逼真的音频。
在 PlayDiffusion 中,BigVGAN 解码器模型用于将生成的标记序列转换回语音波形。这确保了最终输出的语音自然且连贯,具有很高的听觉质量。
PlayDiffusion 的项目地址
- 项目官网:https://blog.play.ai/blog/play-diffusion
- GitHub仓库:https://github.com/playht/PlayDiffusion
- 在线体验Demo:https://huggingface.co/spaces/PlayHT/PlayDiffusion
PlayDiffusion 的应用场景
PlayDiffusion 的应用场景非常广泛,以下是一些典型的应用场景:
- 配音纠错:在配音过程中,难免会出现发音错误或口误。使用 PlayDiffusion 可以快速替换错误发音,保持配音的自然流畅。传统的配音纠错方法通常需要重新录制整个片段,而 PlayDiffusion 只需要替换错误的部分,大大提高了效率。
例如,一部纪录片的配音员在录制过程中将“联合国”误读为“联和国”。使用 PlayDiffusion,配音导演可以直接修改音频,将错误的发音替换为正确的发音,而无需重新录制整个句子。
- 合成对话改词:在合成对话中,有时需要修改对话内容,以确保语言的准确自然。使用 PlayDiffusion 可以轻松修改对话内容,而不会影响语音的整体质量。传统的对话修改方法通常需要重新合成整个对话,而 PlayDiffusion 只需要修改需要修改的部分,大大节省了时间和精力。
例如,一个智能客服机器人在回答用户问题时,使用了不恰当的措辞。使用 PlayDiffusion,开发者可以直接修改机器人的回答,将不恰当的措辞替换为更礼貌、更专业的措辞,从而提升用户体验。
- 播客剪辑:在播客制作过程中,经常需要修改或删除片段,以提升内容质量。使用 PlayDiffusion 可以轻松修改或删除片段,而不会影响音频的整体流畅性。传统的播客剪辑方法通常需要使用专业的音频编辑软件,而 PlayDiffusion 提供了更简单、更高效的解决方案。
例如,一个访谈类播客在后期制作过程中发现某位嘉宾的发言内容过于冗长,影响了节目的节奏。使用 PlayDiffusion,剪辑师可以直接删除冗长的部分,使节目更加紧凑、更吸引人。
- 实时语音互动:在实时语音互动场景中,需要动态调整语音内容,以实现自然交互。使用 PlayDiffusion 可以动态调整语音内容,例如改变语气、语速等,从而使对话更加生动、更具表现力。传统的实时语音互动技术通常只能进行简单的语音传输,而 PlayDiffusion 提供了更丰富的语音互动功能。
例如,在一个在线教育平台中,老师可以使用 PlayDiffusion 动态调整语音的语气和语速,以适应不同学生的学习进度和理解能力。对于学习较慢的学生,老师可以放慢语速,使用更简单易懂的语言;对于学习较快的学生,老师可以加快语速,使用更专业的术语。
- 语音合成:PlayDiffusion 可以高效生成高质量语音,适用于播报等场景。传统的语音合成技术通常需要大量的数据和复杂的算法,而 PlayDiffusion 提供了更简单、更高效的解决方案。PlayDiffusion 生成的语音自然流畅,具有很高的听觉质量,可以广泛应用于各种语音播报场景。
例如,一个新闻网站可以使用 PlayDiffusion 自动生成新闻报道的语音版本,方便用户在开车、做饭等场景中收听新闻。PlayDiffusion 可以根据新闻的内容自动调整语速和语气,使播报更加生动、更具吸引力。
总而言之,PlayDiffusion 的出现,为音频编辑和语音合成领域带来了革命性的变革。它不仅仅是一个工具,更是一种理念的革新,将人工智能与音频处理深度融合,为用户提供了前所未有的编辑体验。随着人工智能技术的不断发展,PlayDiffusion 将在未来发挥更大的作用,为人们的生活带来更多的便利。







