
在人工智能领域,模型创新层出不穷。MiniMax团队近期开源的推理模型MiniMax-M1,无疑是其中一颗耀眼的明星。这款模型基于混合专家架构(MoE)与闪电注意力机制(lightning attention)相结合,参数总量高达4560亿,每次token激活459亿参数,性能直逼海外领先的闭源模型,堪称业内性价比之王。更令人瞩目的是,MiniMax-M1原生支持100万token的上下文长度,并提供40K和80K两种推理预算版本,能够胜任长输入和复杂推理任务。在各项基准测试中,MiniMax-M1展现出卓越的性能,多项指标超越DeepSeek等开源模型,尤其在复杂软件工程、长上下文理解和工具使用等领域表现突出。其高效的计算能力和强大的推理能力,使其成为下一代语言模型代理的理想选择。
那么,MiniMax-M1究竟有哪些令人称道的关键功能呢?
首先,长上下文处理能力是其一大亮点。MiniMax-M1支持高达100万token的输入和8万token的输出,这意味着它可以轻松处理长篇文档和复杂的推理任务,例如分析冗长的法律条文、研读大量的学术论文,或者创作史诗级的文学作品。
其次,高效的推理能力也是其优势之一。MiniMax-M1提供40K和80K两种推理预算版本,能够根据不同的任务需求,灵活调整计算资源,从而有效降低推理成本,让用户在享受强大性能的同时,也能控制运营成本。
此外,MiniMax-M1在多领域任务优化方面也表现出色。无论是数学推理、软件工程,还是长上下文理解和工具使用,它都能胜任自如,展现出强大的适应性,为用户提供全方位的解决方案。
更值得一提的是,MiniMax-M1还支持功能调用。它能够识别并输出外部函数调用参数,从而方便与外部工具进行交互,实现更复杂的功能,例如自动发送邮件、查询天气信息等。

MiniMax-M1之所以能够拥有如此强大的性能,离不开其独特的技术原理。
**混合专家架构(MoE)**是MiniMax-M1的核心技术之一。它将模型分解为多个专家模块,每个模块负责处理特定的子任务或数据子集。输入数据会根据其特征,动态分配到不同的专家模块进行处理,从而实现高效的计算资源利用和并行处理能力。这种架构使得模型能够在拥有大规模参数的同时,保持高效的计算性能,并支持更复杂的任务处理。可以将其理解为,一个团队拥有多位专家,每位专家擅长不同的领域,当遇到问题时,会根据问题的性质,分配给最合适的专家进行处理,从而提高效率。
**闪电注意力机制(Lightning Attention)**则是另一项关键技术。它通过优化计算流程,减少冗余计算,显著提高了注意力模块的效率。同时,采用稀疏注意力模式,仅关注输入序列中的关键部分,进一步降低了计算复杂度。这种机制使得MiniMax-M1能够高效处理长序列数据,支持模型处理长达100万token的上下文。
大规模强化学习(RL)训练也功不可没。MiniMax团队采用大规模强化学习对模型进行训练,基于奖励信号优化模型的输出,使其在复杂任务中表现更好。他们还提出了一种新的RL算法CISPO,基于裁剪重要性采样权重而不是token更新,提高了训练效率和模型性能。混合注意力设计自然增强了RL的效率,解决了混合架构在扩展RL时的独特挑战。
那么,MiniMax-M1在实际应用中的性能表现如何呢?
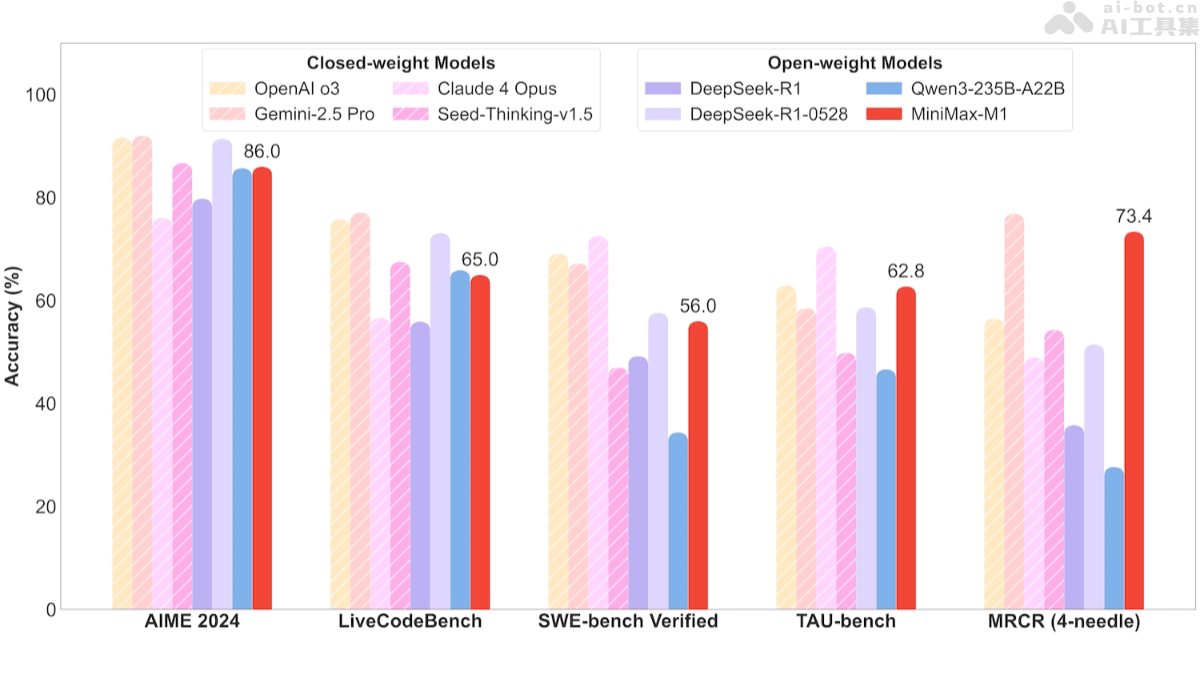
在软件工程任务方面,MiniMax-M1在SWE-bench验证基准上取得了令人瞩目的成绩。MiniMax-M1-40k和MiniMax-M1-80k分别取得了55.6%和56.0%的成绩,略逊于DeepSeek-R1-0528的57.6%,但显著超越其他开源权重模型。这意味着,MiniMax-M1在代码生成、优化、调试和文档生成等方面具有很强的能力,能够帮助开发者快速实现功能模块,提升开发效率。
在长上下文理解任务方面,MiniMax-M1依托百万级上下文窗口,表现卓越,全面超越所有开源权重模型,甚至超越OpenAI o3和Claude 4 Opus,在全球排名第二,仅以微弱差距落后于Gemini 2.5 Pro。这表明,MiniMax-M1在处理长篇报告、学术论文、小说等长文本时,具有很强的优势,能够准确理解文本的含义,并进行高质量的摘要、翻译等操作。
在工具使用场景方面,MiniMax-M1-40k在代理工具使用场景(TAU-bench)中,领跑所有开源权重模型,战胜Gemini-2.5 Pro。这意味着,MiniMax-M1可以作为智能助手,调用外部工具,完成多步骤任务,提供自动化解决方案,提升工作效率,例如自动预订机票、安排会议日程等。
对于开发者和研究者来说,MiniMax-M1的开源无疑是一个福音。他们可以通过以下渠道获取MiniMax-M1的相关资源:
- GitHub仓库:https://github.com/MiniMax-AI/MiniMax-M1
- HuggingFace模型库:https://huggingface.co/collections/MiniMaxAI/minimax-m1
- 技术论文:https://github.com/MiniMax-AI/MiniMax-M1/blob/main/MiniMax_M1_tech_report
MiniMax-M1的定价策略也颇具竞争力。其API调用推理成本定价如下:
- 0-32k 输入长度:
- 输入成本:0.8元/百万 token。
- 输出成本:8元/百万 token。
- 32k-128k 输入长度:
- 输入成本:1.2元/百万 token。
- 输出成本:16元/百万 token。
- 128k-1M 输入长度:
- 输入成本:2.4元/百万 token。
- 输出成本:24元/百万 token。
更令人惊喜的是,在MiniMax APP和Web端,用户可以享受不限量免费使用。
MiniMax-M1的应用场景十分广泛,可以应用于以下领域:
- 复杂软件工程:支持代码生成、优化、调试和文档生成,帮助开发者快速实现功能模块,提升开发效率。
- 长文本处理:能够生成长篇报告、学术论文、小说等,同时支持长文本分析和多文档总结,满足多样化需求。
- 数学与逻辑推理:解决复杂数学问题,如竞赛数学题目和数学建模,处理逻辑推理任务,提供清晰的解题思路。
- 工具使用与交互:作为智能助手调用外部工具,完成多步骤任务,提供自动化解决方案,提升工作效率。
总而言之,MiniMax-M1作为一款高性能、低成本、多功能的开源推理模型,无疑将为人工智能领域带来新的活力。它的出现,将加速人工智能技术在各个行业的应用,推动人工智能产业的蓬勃发展。我们有理由相信,在不久的将来,MiniMax-M1将在更多领域展现其强大的实力,为人类创造更大的价值。
MiniMax-M1的开源,为广大开发者和研究者提供了一个强大的工具,可以基于此模型进行二次开发和创新,从而推动人工智能技术的进步。
此外,MiniMax-M1的出现,也对其他人工智能企业提出了更高的要求,促使它们不断创新,提升自身的技术实力,从而推动整个行业的进步。
总之,MiniMax-M1的开源,是人工智能领域的一件大事,它将对人工智能技术的发展产生深远的影响。我们期待MiniMax-M1在未来能够取得更大的成就,为人类创造更多的价值。

