
在人工智能领域,多模态大型语言模型(MLLMs)正迅速崭露头角,成为研究和应用的热点。其中,MindOmni,作为由腾讯ARC Lab联合清华大学深圳国际研究生院、香港中文大学和香港大学等机构共同研发的杰出代表,凭借其卓越的视觉语言理解与生成能力,在这一领域中独树一帜。本文将深入剖析MindOmni的技术原理、功能特点、应用场景,以及其对多模态AI发展所带来的深远影响。
MindOmni:多模态AI的新星
MindOmni的核心优势在于其强大的推理生成能力,这得益于其所采用的强化学习算法(RGPO)。通过这种算法,MindOmni在视觉语言模型的性能上实现了显著提升。模型训练采用了三阶段策略,从构建统一的视觉语言模型开始,逐步过渡到基于链式思考(CoT)数据的监督微调,最终利用RGPO算法优化推理生成过程。
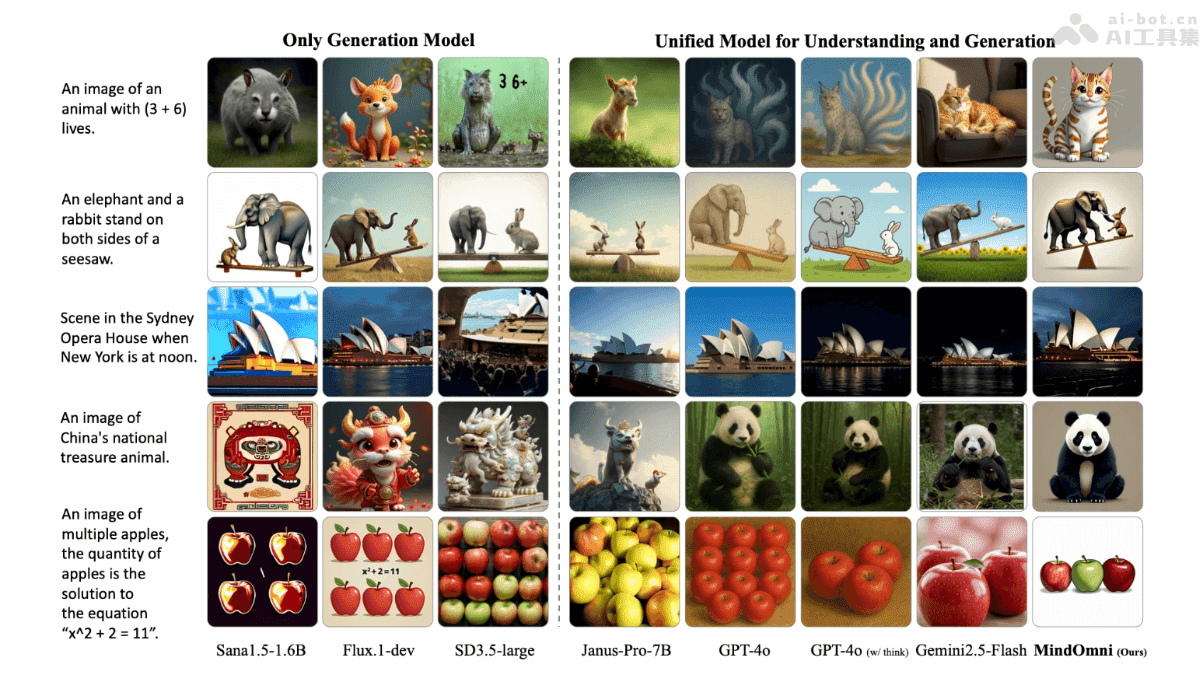
MindOmni的主要功能
MindOmni的功能十分全面,涵盖了视觉理解、文本到图像生成、推理生成、视觉编辑以及多模态输入处理等多个方面:
- 视觉理解:MindOmni能够深入理解和解释图像的内容,并准确回答与图像相关的问题。这意味着它可以应用于图像搜索、智能客服等领域,为用户提供更直观、更便捷的信息服务。
- 文本到图像生成:通过输入文本描述,MindOmni能够生成高质量的图像。这项功能在内容创作、广告设计等领域具有广泛的应用前景,可以帮助用户快速生成符合需求的视觉素材。
- 推理生成:MindOmni具备复杂的逻辑推理能力,能够生成包含推理过程的图像。这使得它在教育、科研等领域具有独特的价值,可以用于可视化复杂概念、辅助科学研究。
- 视觉编辑:MindOmni支持对现有图像进行编辑,例如添加、删除或修改图像中的元素。这项功能可以应用于图像修复、创意设计等领域,为用户提供更灵活、更强大的图像处理能力。
- 多模态输入处理:MindOmni能够同时处理文本和图像输入,并生成相应的输出。这意味着它可以应用于智能助手、人机交互等领域,为用户提供更自然、更智能的交互体验。
MindOmni的技术原理
MindOmni的技术架构是其强大功能的基础。它主要由视觉语言模型(VLM)、轻量级连接器、文本头和解码器扩散模块组成。
- 视觉语言模型(VLM):VLM是MindOmni的核心组成部分,它基于预训练的ViT(Vision Transformer)提取图像特征,并使用文本编码器将文本输入转换为离散的文本标记。ViT是一种强大的图像特征提取器,能够有效地捕捉图像中的各种视觉信息。文本编码器则可以将文本输入转换为机器可理解的数字表示,为后续的文本处理任务提供基础。
- 轻量级连接器:轻量级连接器负责连接VLM和扩散解码器,确保特征在不同模块之间的有效传递。这种设计可以有效地降低模型的计算复杂度,提高模型的运行效率。
- 文本头:文本头用于处理文本输入和生成文本输出。它可以执行各种文本处理任务,例如文本分类、文本生成等。
- 解码器扩散模块:解码器扩散模块负责生成图像,它基于去噪过程将潜在噪声转换为实际图像。扩散模型是一种强大的图像生成模型,可以生成高质量、高分辨率的图像。
MindOmni的训练过程分为三个阶段:
- 第一阶段:预训练。在这个阶段,模型主要学习基本的文本到图像生成和编辑能力。通过将图像文本对和X2I数据对训练连接器,确保扩散解码器能够无缝处理VLM的语义表示。优化目标函数主要基于扩散损失和KL散度损失。
- 第二阶段:基于链式思考(CoT)指令数据进行优化。在这个阶段,模型主要学习生成逻辑推理过程。通过构建一系列粗到细的CoT指令数据,并使用这些数据对模型进行监督微调,提高模型的推理能力。
- 第三阶段:基于强化学习进行优化。在这个阶段,模型主要学习提升推理生成能力,确保生成内容的质量和准确性。通过推出推理生成策略优化(RGPO)算法,并使用多模态反馈信号(包括图像和文本特征)指导策略更新,提高模型的生成质量。此外,还引入了格式奖励函数和一致性奖励函数,用于评估视觉语言对齐情况。为了稳定训练过程,防止知识遗忘,还使用了KL散度正则化器。
MindOmni的应用场景
MindOmni的应用场景十分广泛,几乎涵盖了所有需要多模态理解和生成的领域:
- 内容创作:MindOmni可以根据文本描述生成高质量图像,应用于广告、游戏、影视等行业的视觉内容创作,加速创意设计流程。例如,广告设计师可以使用MindOmni快速生成各种广告创意图,游戏开发者可以使用MindOmni快速生成游戏角色、场景和道具,影视制作人员可以使用MindOmni快速生成故事板和概念图。
- 教育领域:MindOmni可以生成与教学内容相关的图像和解释,辅助教学,帮助学生更好地理解和记忆复杂概念,提升学习效果。例如,教师可以使用MindOmni生成各种教学插图,帮助学生更直观地理解抽象的概念;学生可以使用MindOmni生成各种学习卡片,帮助记忆知识点。
- 娱乐产业:MindOmni可以在游戏开发中生成角色、场景和道具,加速开发流程;为影视制作提供故事板和概念图,丰富创意表达。例如,游戏开发者可以使用MindOmni快速生成各种游戏角色和场景,提高游戏开发的效率;影视制作人员可以使用MindOmni快速生成各种故事板和概念图,为影视创作提供灵感。
- 广告行业:MindOmni可以生成吸引人的广告图像和视频,提高广告效果。例如,广告公司可以使用MindOmni快速生成各种广告创意,提高广告的点击率和转化率。
- 智能助手:MindOmni可以结合语音、文本和图像输入,提供更自然、更智能的交互体验,满足用户多样化的需求。例如,用户可以通过语音、文本或图像与智能助手进行交互,MindOmni可以根据用户的输入生成相应的输出,为用户提供更便捷的服务。
MindOmni的未来展望
作为多模态AI领域的杰出代表,MindOmni的未来发展前景广阔。随着技术的不断进步,MindOmni有望在更多领域得到应用,为人类社会带来更大的价值。例如,在医疗领域,MindOmni可以用于辅助医生进行诊断,提高诊断的准确率;在交通领域,MindOmni可以用于自动驾驶,提高交通的安全性和效率;在金融领域,MindOmni可以用于风险评估,提高金融的稳定性。
总而言之,MindOmni的出现,不仅是多模态AI技术的一次重要突破,也为我们展示了人工智能在理解和生成复杂信息方面的巨大潜力。随着MindOmni的不断发展和完善,我们有理由期待它在未来的各个领域中发挥更大的作用,为人类社会带来更多的创新和变革。










