
在人工智能领域,多模态大型语言模型正逐渐成为研究和应用的热点。这些模型不仅能够理解和生成文本,还能处理图像、音频等多种类型的数据,从而实现更丰富、更智能的交互体验。近日,腾讯联合清华大学等机构推出了名为MindOmni的多模态大语言模型,引起了业界的广泛关注。本文将深入探讨MindOmni的技术原理、功能特点、应用场景等方面,以期为读者全面了解这一前沿技术提供参考。
MindOmni:多模态AI的新星
MindOmni是由腾讯 ARC Lab 联合清华大学深圳国际研究生院、香港中文大学和香港大学等顶尖学术机构共同研发的多模态大型语言模型。该模型基于强化学习算法(RGPO),在视觉语言模型的推理生成能力方面取得了显著提升。通过三阶段训练策略,MindOmni不仅构建了统一的视觉语言模型,还通过链式思考(CoT)数据进行监督微调,并利用 RGPO 算法优化推理生成过程。这一系列创新举措使得 MindOmni 在多模态理解与生成任务中表现出色,尤其在数学推理等复杂场景下展现出强大的推理生成能力,为多模态 AI 的发展开辟了新的路径。
MindOmni的核心功能
MindOmni 的强大功能主要体现在以下几个方面:
视觉理解:MindOmni 具备强大的视觉理解能力,能够深入理解和解释图像内容,并准确回答与图像相关的问题。这意味着,用户可以通过提问的方式,让 MindOmni 帮助他们理解图像中的各种元素和关系。
文本到图像生成:MindOmni 能够根据文本描述生成高质量的图像。用户只需提供一段文字描述,MindOmni 就能将其转化为逼真的图像,这为内容创作提供了极大的便利。
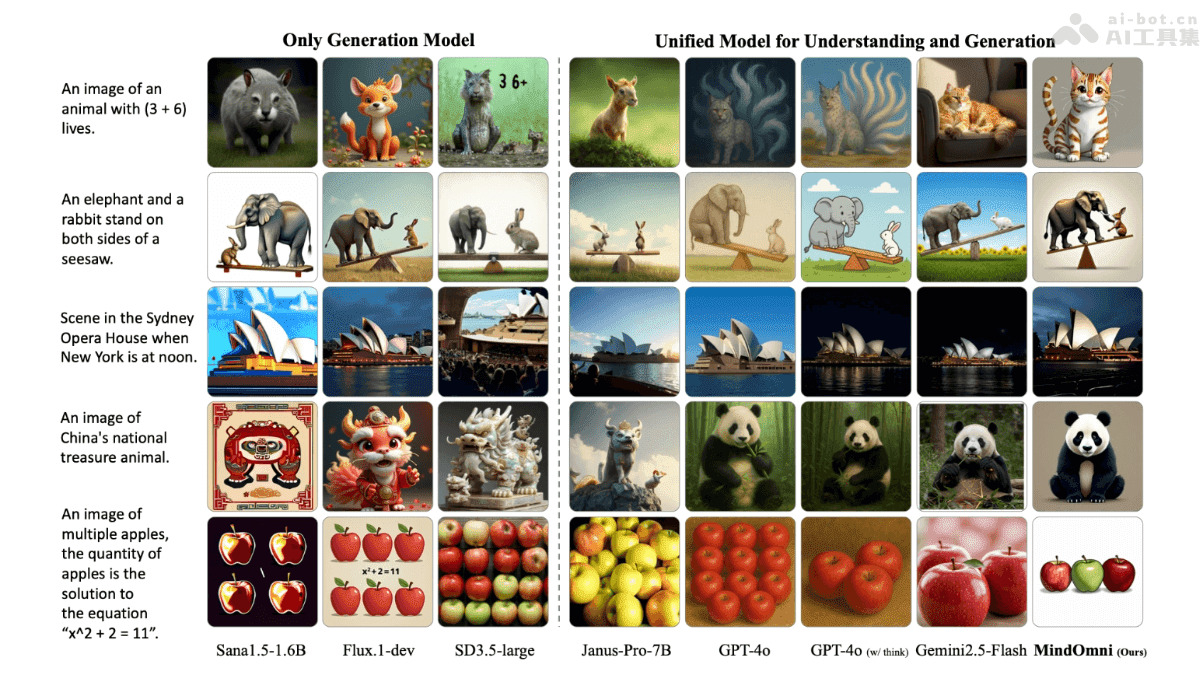
推理生成:MindOmni 不仅能生成图像,还能进行复杂的逻辑推理,并生成包含推理过程的图像。这意味着,MindOmni 能够处理需要逻辑推理才能完成的任务,例如数学问题、科学实验等。
视觉编辑:MindOmni 还可以对现有图像进行编辑,例如添加、删除或修改图像中的元素。这为图像处理提供了更多的灵活性和创造性。
多模态输入处理:MindOmni 支持同时处理文本和图像输入,并生成相应的输出。这意味着,用户可以通过混合输入的方式,让 MindOmni 更好地理解他们的意图,并生成更符合需求的输出。
MindOmni的技术原理
MindOmni 的技术原理主要包括模型架构和三阶段训练策略两个方面。
1. 模型架构
MindOmni 的模型架构主要由以下几个部分组成:
视觉语言模型(VLM):VLM 是 MindOmni 的核心组成部分,它基于预训练的 ViT(Vision Transformer)提取图像特征,并使用文本编码器将文本输入转换为离散的文本标记。ViT 是一种先进的图像处理模型,能够有效地提取图像中的各种特征。文本编码器则负责将文本信息转换为计算机可以理解的形式。
轻量级连接器:轻量级连接器用于连接 VLM 和扩散解码器,确保特征在不同模块之间的有效传递。连接器的作用是将 VLM 提取的图像和文本特征传递给扩散解码器,以便生成最终的图像。
文本头:文本头负责处理文本输入和生成文本输出。它可以理解用户的文本指令,并生成相应的文本回复。
解码器扩散模块:解码器扩散模块负责生成图像,基于去噪过程将潜在噪声转换为实际图像。扩散模型是一种强大的图像生成模型,可以通过逐步去噪的方式生成高质量的图像。
2. 三阶段训练策略
MindOmni 采用了三阶段训练策略,以逐步提升模型的性能:
第一阶段:预训练
在第一阶段,模型主要学习基本的文本到图像生成和编辑能力。通过将图像文本对和 X2I 数据对训练连接器,确保扩散解码器能够无缝处理 VLM 的语义表示。这一阶段的优化目标函数主要基于扩散损失和 KL 散度损失。
第二阶段:基于链式思考(CoT)的指令微调
在第二阶段,模型基于链式思考(CoT)指令数据进一步优化,以生成逻辑推理过程。通过构建一系列粗到细的 CoT 指令数据,并使用这些数据对模型进行监督微调,可以提高模型的推理能力。
第三阶段:基于强化学习的推理生成策略优化
在第三阶段,模型基于强化学习进一步提升推理生成能力,确保生成内容的质量和准确性。腾讯推出了推理生成策略优化(RGPO)算法,并使用多模态反馈信号(包括图像和文本特征)指导策略更新。此外,还引入了格式奖励函数和一致性奖励函数,以评估视觉语言对齐情况。为了稳定训练过程,防止知识遗忘,还使用了 KL 散度正则化器。
MindOmni的应用场景
MindOmni 的多功能性使其在多个领域具有广泛的应用前景:
内容创作:MindOmni 可以根据文本描述生成高质量图像,广泛应用于广告、游戏、影视等行业的视觉内容创作,从而加速创意设计流程。例如,广告设计师可以使用 MindOmni 快速生成各种广告创意图,游戏开发者可以使用 MindOmni 生成游戏角色和场景,影视制作人员可以使用 MindOmni 制作故事板和概念图。
教育领域:MindOmni 可以生成与教学内容相关的图像和解释,辅助教学,帮助学生更好地理解和记忆复杂概念,提升学习效果。例如,教师可以使用 MindOmni 生成生物细胞的结构图、物理实验的演示动画等,帮助学生更直观地理解抽象的概念。
娱乐产业:在游戏开发中,MindOmni 可以生成角色、场景和道具,加速开发流程;为影视制作提供故事板和概念图,丰富创意表达。例如,游戏开发者可以使用 MindOmni 快速生成各种游戏素材,影视制作人员可以使用 MindOmni 快速制作电影预告片。
广告行业:MindOmni 可以生成吸引人的广告图像和视频,提高广告效果。例如,广告公司可以使用 MindOmni 快速生成各种广告创意,并根据用户反馈进行优化。
智能助手:MindOmni 结合语音、文本和图像输入,提供更自然、更智能的交互体验,满足用户多样化的需求。例如,用户可以通过语音、文本和图像的方式与智能助手进行交互,让智能助手更好地理解他们的意图,并提供更个性化的服务。
未来展望
MindOmni 的出现为多模态 AI 的发展注入了新的活力。随着技术的不断进步和应用场景的不断拓展,MindOmni 有望在内容创作、教育、娱乐、广告等领域发挥更大的作用,为人们的生活和工作带来更多的便利和惊喜。
然而,多模态大语言模型的发展仍然面临着一些挑战。例如,如何提高模型的推理能力、如何保证生成内容的安全性和可靠性、如何降低模型的计算成本等。相信随着研究的深入和技术的创新,这些问题将逐步得到解决。
MindOmni 作为多模态 AI 领域的一颗新星,其技术创新和应用前景值得期待。我们有理由相信,在不久的将来,多模态大语言模型将成为人工智能领域的重要发展方向,为人类社会带来更深远的影响。










