
MindOmni:多模态大语言模型的创新探索
在人工智能领域,多模态大语言模型正成为研究和应用的热点。其中,MindOmni是由腾讯ARC Lab联合清华大学深圳国际研究生院、香港中文大学和香港大学等机构共同推出的创新模型。该模型基于强化学习算法(RGPO),旨在显著提升视觉语言模型的推理生成能力,为多模态AI的发展开辟新的路径。
MindOmni的技术架构与训练策略
MindOmni的技术原理复杂而精妙,其核心在于其模型架构和训练策略。模型架构主要由视觉语言模型(VLM)、轻量级连接器、文本头和解码器扩散模块组成。
**视觉语言模型(VLM)**是整个架构的基础,它利用预训练的ViT(Vision Transformer)提取图像特征,并使用文本编码器将文本输入转换为离散的文本标记。ViT模型在图像处理方面表现出色,能够有效地捕捉图像中的关键信息。
轻量级连接器的作用是连接VLM和扩散解码器,确保特征在不同模块之间的有效传递。这种连接器的设计旨在优化信息流动,使得模型能够更好地理解和整合视觉与语言信息。
文本头负责处理文本输入和生成文本输出,确保模型在文本处理方面具有强大的能力。
解码器扩散模块则负责生成图像,其核心是基于去噪过程将潜在噪声转换为实际图像。这种扩散模型在图像生成领域具有广泛的应用,能够生成高质量、高分辨率的图像。
MindOmni的训练策略分为三个阶段,每个阶段都有其独特的优化目标:
第一阶段:预训练
在这一阶段,模型主要学习基本的文本到图像生成和编辑能力。通过训练图像文本对和X2I数据对,连接器能够确保扩散解码器无缝处理VLM的语义表示。优化目标函数主要基于扩散损失和KL散度损失,这些损失函数能够帮助模型学习生成高质量的图像。
第二阶段:基于链式思考(CoT)的指令数据微调
为了进一步优化模型的推理生成能力,研究人员构建了一系列粗到细的CoT指令数据,并使用这些数据对模型进行监督微调。CoT数据能够引导模型学习逻辑推理过程,从而提升其在复杂场景下的表现。
第三阶段:基于强化学习的推理生成能力提升
在这一阶段,模型通过强化学习进一步提升推理生成能力,确保生成内容的质量和准确性。研究人员推出了推理生成策略优化(RGPO)算法,并使用多模态反馈信号(包括图像和文本特征)指导策略更新。此外,还引入了格式奖励函数和一致性奖励函数,用于评估视觉语言对齐情况。为了稳定训练过程,防止知识遗忘,研究人员还使用了KL散度正则化器。
MindOmni的主要功能
MindOmni作为一款多模态大型语言模型,具备多种强大的功能,使其在不同应用场景中都能发挥重要作用。以下是其主要功能的详细介绍:
视觉理解
MindOmni能够理解和解释图像内容,准确回答与图像相关的问题。这项功能使其在图像分析、智能问答等领域具有广泛的应用前景。例如,用户可以上传一张图片,然后向MindOmni提问关于图片内容的问题,模型能够准确地识别图像中的物体、场景和人物,并给出详细的描述和解释。
文本到图像生成
MindOmni可以根据文本描述生成高质量的图像。这项功能在内容创作、广告设计等领域具有重要价值。用户只需输入一段文字描述,MindOmni就能够生成与之对应的图像,从而大大提高创作效率。例如,用户可以输入“一个阳光明媚的海滩,有椰子树和白色沙滩”,MindOmni能够生成一幅逼真的海滩风景图。
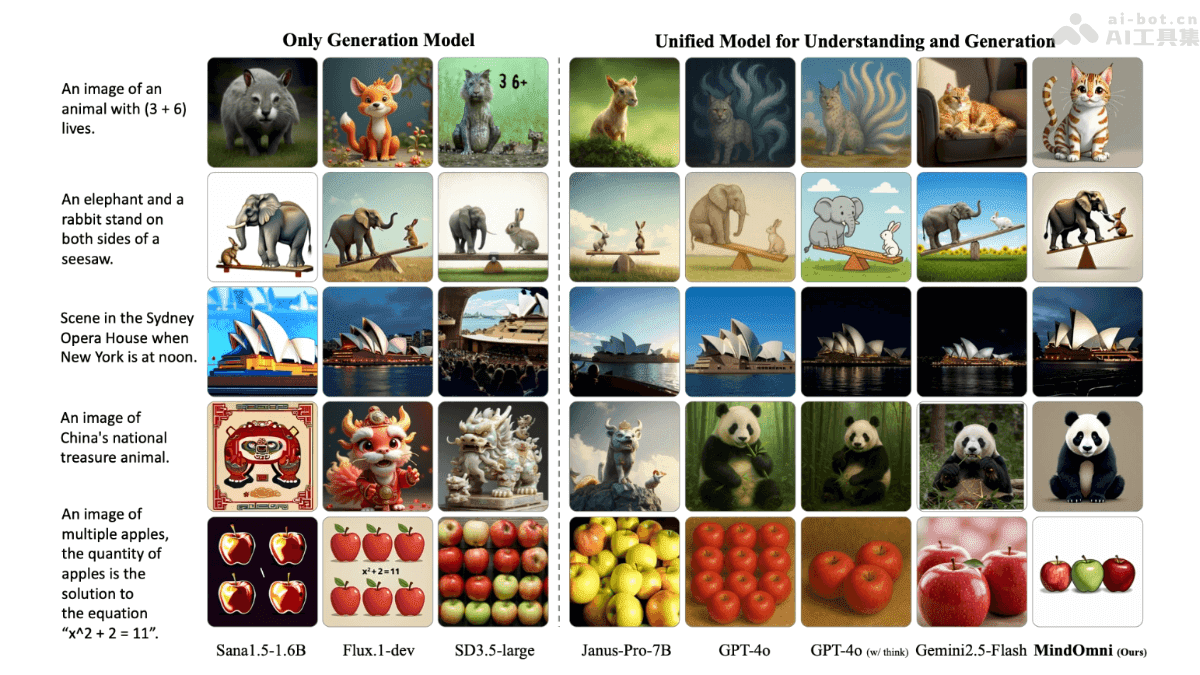
推理生成
MindOmni能够进行复杂的逻辑推理,生成包含推理过程的图像。这项功能使其在教育、科研等领域具有独特的优势。模型不仅能够生成图像,还能够展示生成图像的推理过程,帮助用户更好地理解和学习。例如,在数学问题中,MindOmni可以生成解题步骤的图像,从而帮助学生理解解题思路。
视觉编辑
MindOmni支持对现有图像进行编辑,如添加、删除或修改图像中的元素。这项功能在图像处理、设计等领域具有广泛的应用。用户可以通过简单的操作,对图像进行修改和优化,从而满足不同的需求。例如,用户可以上传一张照片,然后使用MindOmni添加滤镜、调整色彩、裁剪图像等。
多模态输入处理
MindOmni支持同时处理文本和图像输入,并生成相应的输出。这项功能使其在人机交互、智能助手等领域具有重要价值。模型能够综合理解文本和图像信息,从而提供更准确、更智能的服务。例如,用户可以上传一张图片并输入一段文字描述,MindOmni能够根据这些信息生成新的图像或文本。
MindOmni的应用场景分析
MindOmni作为一种先进的多模态AI模型,其应用场景非常广泛,几乎涵盖了所有需要视觉和语言理解的领域。以下是一些具体的应用场景分析:
内容创作
在内容创作领域,MindOmni能够根据文本描述生成高质量图像,广泛应用于广告、游戏、影视等行业的视觉内容创作。这种能力可以显著加速创意设计流程,降低创作成本。例如,广告公司可以使用MindOmni快速生成各种广告创意图,游戏开发者可以利用它生成游戏场景和角色,影视制作人员可以借助它制作故事板和概念图。
教育领域
MindOmni可以生成与教学内容相关的图像和解释,辅助教学,帮助学生更好地理解和记忆复杂概念,提升学习效果。例如,在生物课上,MindOmni可以生成细胞结构图和生物进化图;在历史课上,它可以生成历史事件的场景图和人物画像;在数学课上,它可以生成几何图形和函数图像。
娱乐产业
在游戏开发中,MindOmni可以生成角色、场景和道具,加速开发流程。在影视制作中,它可以提供故事板和概念图,丰富创意表达。例如,游戏开发者可以使用MindOmni快速生成各种游戏角色和场景,影视制作人员可以利用它快速制作故事板和概念图,从而节省大量时间和成本。
广告行业
MindOmni可以生成吸引人的广告图像和视频,提高广告效果。广告公司可以使用MindOmni快速生成各种广告创意图,从而吸引更多用户的关注。例如,在推广一款新产品时,可以使用MindOmni生成与产品相关的图像和视频,从而提高广告的吸引力。
智能助手
MindOmni可以结合语音、文本和图像输入,提供更自然、更智能的交互体验,满足用户多样化的需求。例如,用户可以通过语音、文本或图像与智能助手进行交互,MindOmni能够理解用户的意图,并提供相应的服务。这种智能助手可以应用于智能家居、智能客服等领域,为用户提供更便捷的生活体验。
MindOmni的开源项目与资源
MindOmni作为一个开源项目,为研究者和开发者提供了丰富的资源和工具。以下是一些重要的项目地址和资源:
- 项目官网:https://mindomni.github.io/
- GitHub仓库:https://github.com/TencentARC/MindOmni
- arXiv技术论文:https://arxiv.org/pdf/2505.13031
- 在线体验Demo:https://huggingface.co/spaces/stevengrove/MindOmni
通过这些资源,研究者和开发者可以深入了解MindOmni的技术原理、模型架构和训练策略,从而更好地利用和扩展MindOmni的功能。
未来展望
MindOmni作为多模态大语言模型的代表,其发展前景广阔。未来,随着技术的不断进步,MindOmni有望在更多领域发挥重要作用,为人类带来更多便利和创新。
随着多模态技术的不断发展,我们有理由相信,MindOmni将在未来的AI领域中扮演更加重要的角色。通过不断优化模型架构、改进训练策略和拓展应用场景,MindOmni有望成为多模态AI领域的领头羊,引领人工智能技术的发展方向。
结论
MindOmni通过其独特的技术架构和训练策略,展现了强大的多模态理解与生成能力。它不仅在数学推理等复杂场景下表现出色,而且在内容创作、教育、娱乐、广告等多个领域具有广泛的应用前景。随着技术的不断进步和应用场景的不断拓展,MindOmni有望成为多模态AI领域的领军者,为人工智能技术的发展注入新的活力。










