
在人工智能领域,具身智能正逐渐成为研究的热点。近日,香港大学与上海人工智能实验室联合推出了全新的具身智能框架——VLN-R1,该框架引起了业界的广泛关注。那么,VLN-R1究竟是什么?它又具有哪些独特的功能和技术原理?本文将对VLN-R1进行深入剖析,并探讨其潜在的应用场景。
VLN-R1:具身智能的新突破
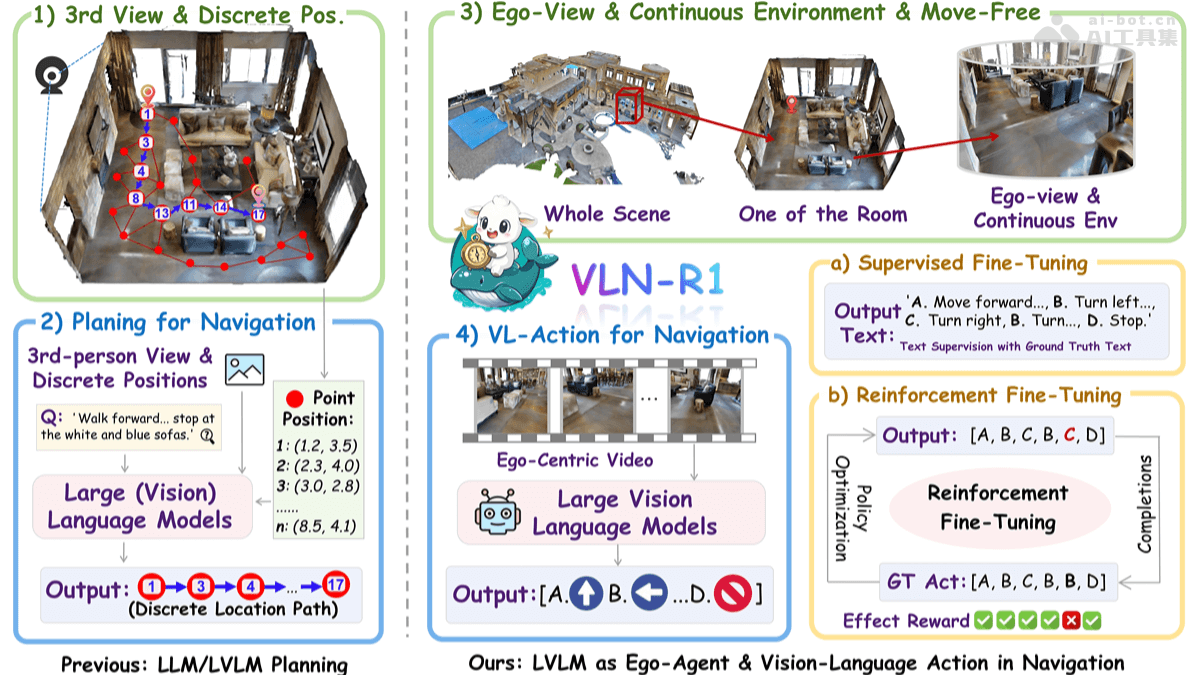
VLN-R1,全称为Vision-Language Navigation with Recurrent neural network,是一种基于大型视觉语言模型(LVLM)的具身智能框架。与传统的导航方法不同,VLN-R1能够直接将第一人称视频流转化为连续的导航动作,从而实现智能体在复杂环境中的自主导航。这一突破性的设计理念,为具身智能的发展开辟了新的道路。
该框架的开发团队基于Habitat 3D模拟器构建了VLN-Ego数据集,用于训练和评估VLN-R1的性能。为了更好地平衡历史和当前观测,团队还采用了长短期记忆(LSTM)采样策略。在训练过程中,VLN-R1采用了两阶段训练方法:首先是监督微调(SFT),使模型的动作序列文本预测与专家演示对齐;然后是强化微调(RFT),基于时间衰减奖励(TDR)机制优化多步未来动作。实验结果表明,VLN-R1在VLN-CE基准测试中表现出色,充分证明了LVLM在具身导航中的有效性,并能够显著提升任务特定推理能力,同时保持较高的数据效率。
VLN-R1的核心功能
VLN-R1之所以备受关注,主要在于其独特的功能设计,这些功能使其在具身智能领域具有显著的优势:
连续环境导航:VLN-R1能够直接处理第一人称视频流,使智能体在连续的3D环境中自由移动。这意味着智能体不再局限于预定义的节点,而是可以在整个环境中进行探索和导航,极大地提高了导航的灵活性和适应性。
精确的动作生成:VLN-R1能够生成四种基本动作命令,包括FORWARD(前进)、TURN-LEFT(左转)、TURN-RIGHT(右转)和STOP(停止)。通过这些基本动作的组合,智能体可以实现精确的导航控制,从而更好地完成各种任务。
高效的数据训练:VLN-R1采用了监督微调(SFT)和强化微调(RFT)相结合的训练方法,能够在有限的数据下实现高效的模型训练。这种数据高效性对于实际应用具有重要意义,因为收集和标注大量训练数据往往是一项耗时且昂贵的任务。
强大的跨领域适应性:通过强化微调(RFT),VLN-R1能够快速适应新的导航任务和环境,即使只有少量数据。这意味着该框架可以广泛应用于不同的场景,而无需进行大量的重新训练。
优越的任务特定推理能力:VLN-R1基于时间衰减奖励(TDR)机制,能够优化多步未来动作的预测,从而增强长期导航性能。这种任务特定推理能力使智能体能够更好地理解导航指令,并制定合理的导航策略。
VLN-R1的技术原理剖析
VLN-R1的卓越性能,离不开其先进的技术原理。下面将对VLN-R1的几个关键技术进行详细分析:
VLN-Ego数据集的构建:VLN-Ego数据集是VLN-R1的基石。该数据集基于Habitat 3D模拟器生成,包含了大量的第一人称视频流和对应的未来动作预测。通过使用Habitat 3D模拟器,研究团队可以方便地生成各种复杂的室内环境,并模拟智能体在这些环境中的导航过程。这为VLN-R1的训练提供了丰富的数据。
长短期记忆采样策略:在处理视频输入时,VLN-R1采用了长短期记忆(LSTM)采样策略。该策略能够动态平衡历史帧的重要性与实时输入的敏感性,确保模型在导航过程中既考虑短期相关性,又不丢失长期上下文信息。这意味着智能体可以更好地理解当前环境,并根据历史经验做出合理的导航决策。
LSTM是一种特殊的循环神经网络(RNN),它能够有效地处理序列数据中的长期依赖关系。在VLN-R1中,LSTM被用于对视频帧序列进行编码,从而提取出与导航任务相关的特征。通过LSTM的记忆功能,智能体可以记住之前的状态和动作,并将其用于指导未来的导航决策。这种记忆能力对于在复杂环境中进行导航至关重要,因为智能体需要根据历史信息来推断当前位置和方向。
- 监督微调(SFT):监督微调(SFT)是VLN-R1训练过程的第一阶段。在该阶段,模型通过最小化模型预测文本与专家演示文本之间的交叉熵损失,使模型的动作序列预测与真实动作对齐。这意味着模型可以学习到如何根据语言指令生成相应的动作。
交叉熵损失是一种常用的损失函数,用于衡量模型预测结果与真实结果之间的差异。在SFT中,研究团队使用交叉熵损失来衡量模型预测的动作序列与专家演示的动作序列之间的差异。通过最小化交叉熵损失,模型可以逐步学习到如何生成与专家演示相似的动作序列。
- 强化微调(RFT):强化微调(RFT)是VLN-R1训练过程的第二阶段。在该阶段,模型基于组相对策略优化(GRPO)的强化学习方法,并采用时间衰减奖励(TDR)机制来评估和优化多步未来动作的预测。这意味着模型可以学习到如何在长期导航任务中做出更优的决策。
强化学习是一种机器学习方法,它通过让智能体在环境中进行交互,并根据获得的奖励来学习最优策略。在RFT中,研究团队使用强化学习来训练VLN-R1,使其能够在长期导航任务中获得更高的奖励。时间衰减奖励(TDR)机制是一种特殊的奖励机制,它根据动作发生的时间来调整奖励的大小。通过使用TDR机制,模型可以更加关注近期的动作,从而更好地优化导航策略。
- 大型视觉语言模型(LVLM):VLN-R1基于先进的LVLM(如Qwen2-VL)处理视觉和语言输入,实现了从第一人称视频流到导航动作的直接映射。LVLM是一种将视觉和语言信息融合在一起的模型,它能够理解图像中的内容,并将其与语言指令联系起来。
通过使用LVLM,VLN-R1可以更好地理解用户的导航指令,并根据图像中的信息来生成相应的动作。例如,当用户说“向左转”时,LVLM可以分析图像中的内容,判断哪个方向是左边,并生成相应的左转动作。这种视觉和语言的融合,大大提高了VLN-R1的泛化能力和适应性。
VLN-R1的应用前景展望
VLN-R1作为一种先进的具身智能框架,具有广泛的应用前景。以下列举了几个典型的应用场景:
家庭服务机器人:VLN-R1可以应用于家庭服务机器人,使其能够根据主人的自然语言指令在家中自由导航,完成打扫卫生、取物等任务,从而提升生活便利性。例如,主人可以说“去厨房帮我拿一杯水”,机器人就可以根据指令自主导航到厨房,并将水杯送到主人手中。
工业自动化:VLN-R1可以应用于工厂车间,助力机器人按操作员指令灵活导航,完成物料搬运和设备维护,从而提高生产效率。例如,操作员可以说“将零件A运送到工作台B”,机器人就可以根据指令自主导航到零件A的存放位置,并将零件运送到指定的工作台。
智能仓储:VLN-R1可以应用于仓库,使仓库机器人依据指令在货架间精准导航,高效完成货物存储与检索,从而优化仓储管理。例如,管理员可以说“将商品C放入货架D”,机器人就可以根据指令自主导航到货架D,并将商品C放入指定的位置。
医疗保健:VLN-R1可以应用于医院或养老院,支持机器人按医护人员或患者指令导航,完成送药、送餐等任务,从而减轻医护负担。例如,护士可以说“将药物E送到病房F”,机器人就可以根据指令自主导航到病房F,并将药物E送到患者手中。
智能交通:VLN-R1可以应用于自动驾驶车辆,帮助车辆在复杂城市环境中按交通信号和指令导航,从而增强行驶安全性和灵活性。例如,驾驶员可以说“沿着这条路直行,然后右转”,车辆就可以根据指令自主导航,并安全到达目的地。
结语
VLN-R1的推出,无疑为具身智能领域注入了新的活力。凭借其独特的功能和先进的技术原理,VLN-R1在连续环境导航、动作生成、数据高效训练、跨领域适应和任务特定推理等方面都展现出了卓越的性能。随着人工智能技术的不断发展,相信VLN-R1将在未来的各个领域发挥越来越重要的作用,为人类创造更加美好的生活。
未来,我们可以期待更多基于VLN-R1的创新应用,例如智能家居、智慧医疗、智能交通等。这些应用将极大地改变我们的生活方式,使我们的生活更加便捷、舒适和安全。





